
It’s Summer 21’ in the year of the data engineer. You and your team are ready to build pipelines to knock down the ever expanding list of requests from your counterparts in analytics. But when you go to look for a tool for data pipelines you’re met with bolted on legacy Frankensteins or simplistic services that only get you halfway there. It’s summertime, shouldn’t the living be easy?
My friend, I am happy to inform you that the StreamSets Data Integration Platform is now available to everyone, for free as a cloud SaaS service you can access from anywhere. The platform provides a single graphical development experience for all data integration patterns (Batch, Streaming, Change Data Capture (CDC), ETL, and ML) so you don’t have the swivel-chair between different tools. A single pane of glass for management across hybrid/multi-cloud so you always know what is happening because you have smart data pipelines. And most importantly, in today’s digital world, the platform has pipelines that are built to handle change, so you spend your time designing and deploying vs downtime and rewrites.
The StreamSets Platform is now open to everyone and has some exciting new features to help you get going quickly.
Getting Started Page and Walk-throughs:
New to StreamSets? We have a page for you! As soon as you log in you will see the Getting Started Page and be greeted by a short welcome video. I encourage you to view the video and dive into some of the material on the page. Each video is short (2-3 minutes) and contains some great tips to help you get started without any confusion. We also have multiple walk-throughs to guide you in getting setup with your environments and deployments.
Environments:
An environment defines where to deploy StreamSets engines. An environment represents the resources needed to run the engines. After you create and enable an environment, you create a deployment that defines a group of identical engine instances to launch into that environment. A single environment can host multiple deployments.You can create the following types of environments: Self-managed, Amazon Web Services (AWS) and Google Cloud Platform (GCP).
Deployments:
A deployment is a group of identical engine instances deployed within an environment. A deployment defines the StreamSets engine type, version, and configuration to use. You can deploy and launch multiple instances of the configured engine. A deployment allows you to manage all deployed engine instances with a single configuration change. You can update a deployment to install an additional stage library on the engines or to customize engine configuration properties. After a deployment update, you instruct Control Hub to restart all engine instances in the deployment to replicate the changes to each instance.
Deployment: Running StreamSets Data Platform on Your Laptop
If you have chosen the deployment type “Self-managed”, then it means that you will need to install one of our engines directly on your laptop, within Docker or on a VM. For the purpose of this blog, we are just going to focus on installing on a laptop which is a quick and easy way to start building and testing pipeline design patterns. For this example, I am on a MAC running MacOSX Catalina. Please note that the platform will work on the newest OS version of Apple operating systems without any issues.
The platform has great tutorials and videos that will explain much of the installation process, but in the event you are stuck or temporarily confused, this article offers up 7 tips for a successful data engine creation.
1. Be Sure to Install Java First
If you are a data engineer you likely already have Java installed on your laptop. But in the case you are new to the practice or are working on a fresh laptop for your data engineering project, you must first install Oracle Java 8 or OpenJDK 8 in order for your StreamSets engine to be successfully installed. Keep in mind, if you are deploying on the cloud there is a different process but for this blog we are using it only on our laptop.
There are two simple ways to install Java on your laptop. Already have an Oracle/Java license? Simply log into the website and download the full version of Java version 16.0 or higher. No pre-existing Oracle/Java account? No problem. Open JDK is fully supported as well. Simply visit the OpenJDK download page and complete the installation onto your computer.
2. Increase Your ulimit Size
One common mistake we see users making in installing the Data Collector or Transformer engine is that their operating system won’t give the engine the needed resources in order to complete the installation. To avoid this it is important to check and increase your ulimit size. In order to do this you will need to open up the Terminal application on your computer.
Most operating systems provide a configuration to limit the number of files a process or a user can open. The default values are usually less than the Data Collector requirement of 32768 file descriptors. Use the following command to verify the configured limit for the current user:
ulimit -n
Most operating systems use two ways of configuring the maximum number of open files – the soft limit and the hard limit. The hard limit is set by the system administrator. The soft limit can be set by the user, but only up to the hard limit. Increasing the open file limit differs for each operating system. Consult our operating system documentation for the preferred method.
- Use the following command to create a property list file named limit.maxfiles.plist:
sudo vim /Library/LaunchDaemons/limit.maxfiles.plist
- Use the following command to set the session limit:
ulimit -n 32768
- Use this command to check if the ulimit has been updated successfully:
ulimit -n
There you are, your computer now has the needed resources to be successful with StreamSets Platform.
3. Define Your Environment
We introduced you to the idea of environments earlier in this blog. At a high level they help you manage your systems across hybrid and multi-cloud architectures. The StreamSets platform manages data engines in your environment (On-prem, on cloud, on your laptop). You can have multiple environments all assigned to different cloud providers and data center footprints. As you scale, environments make it easy for you to manage across them all. For our example today, we will focus on “Self-Managed” and the deployments will consist of executing a tarball file locally on my computer.

It’s important to create your environment before you configure a deployment or try to design a pipeline. To find out more about engines I recommend you checkout this short video.
4. Deployments: Copy the Script (the whole thing)
In an environment you may have multiple deployments of different engines. Data Collector engines are scalable and you can design pipelines that leverage multiple engines for things like fault tolerance and failover. However, when running on your laptop you most likely will only be running one engine at a time. The engine is what relies on the Java you have installed and the ulimit you setup in the previous steps. When setting up a deployment you will select self managed.
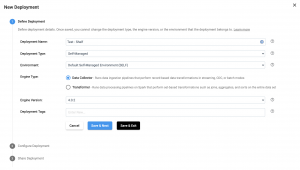
Now select the stage libraries you need, and the users on your team that you’d like to share the deployment with.

Now is when you’ll need to pull up the Terminal application. The StreamSets Platform will generate the script you need to run in the terminal.This is very important, so please copy the entire curl command. This script will download and install the selected version of the engine, boot it up and also register it with the StreamSets Platform so you can start designing your data pipelines. If it is your first time installing a StreamSets engine, the Terminal application will ask if you want to create the file locations. Note these file locations as they become important in our next step.
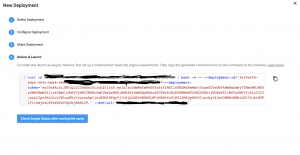
The terminal prompt will inform you once the engine installation has been completed and that the engine has successfully connected to the Control Hub. To learn more about deployments check out this short video.
5. Run a command to keep it up and running (nohup)
As mentioned before, the engine is stateful and is only active when the terminal window is open. A restart of your machine may cause your engine to no longer connect which will prevent you from designing data pipelines.
If you want to keep your engine running but close out the terminal, you will want to run a command to keep the engine running. I often recommend running this command as it will make your experience with the platform a lot more pleasant. First, navigate to your engine folder in the terminal. Once in the folder, run this command.
nohup bin/streamsets dc &
Once you see the output of the above command in the terminal window, press CTRL+C. Then, to verify that the command has worked correctly, also run this command.
tail -f nohup.out
If all goes well, you should see a successful connection message in the terminal window. At this point you can press CTRL+C to stop tailing the logs.
6. Try a Sample Pipeline First
Building a pipeline with StreamSets Platform is made super simple with hundreds of out of the box sources, destinations, and stage processors. But how do you get started with the platform if you don’t yet understand your use case?
Sample pipelines are a great way to get started if you are new to building data pipelines. We have several sample pipelines, many that have sample data preloaded to allow you to quickly run a pipeline and see all the metrics and alerts you get. Here is page one of our sample pipelines.
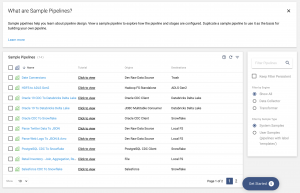
Pick any with a dev destination and a destination like Trash to quickly run and experiment with a pipeline (safely). To find out more on how to build a pipeline, watch this video.
7. What happens if your engine goes offline?
Every so often, depending on how you manage your personal computer, your Data Collector engine may go offline. In order to verify this, simply go to your Deployments section in StreamSets and you will see either a green or red status of the engine. If the status is red, then it will also show you how long the engine has been offline. On server and cloud deployments this is not often an issue as the state of the server is static and running 24/7.
There are also many scenarios where you would need the engine to stop running if the resources needed are not available, therefore piping bad data into your destination data. For the full forensic list of what happened to the engine, check deployment logs. The logs should provide details about why the engine went offline and also any issues with the resources on your computer.
If an engine is not running or you get an error while previewing, validating, or running a pipeline, a job, or a topology, check the State of the deployment. It should be Active as shown below.
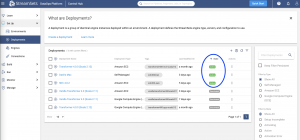
If that’s not what you see, click on the three dots and see if enabling the deployment is an option and try that.
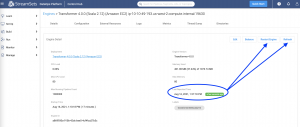
If the state and status looks good, browse to the engine page. In the example above, check the Last Reported Time, which ideally should be in minutes if not seconds. If it’s been longer, first try refreshing the stats by clicking on the Refresh button. If that doesn’t help, try restarting the engine by clicking on Restart Engine.
If you are still stuck, check in with our community or select “Connect with an Expert” in the Help menu at the top.
Get Started Building Pipelines Today
It’s never been easier to get started building smart data pipelines with StreamSets. You can sign up and start building your first pipeline in under ten minutes or grab a sample pipeline to test things out. While summer is often categorically quite, you can begin delivering continuous data and be the hero of your organization without any further delay. A great data journey often starts with a dataset and a laptop. Yours can start today with these 7 helpful tips.