 There has been an explosion of innovation in open source stream processing over the past few years. Frameworks such as Apache Spark and Apache Storm give developers stream abstractions on which they can develop applications; Apache Beam provides an API abstraction, enabling developers to write code independent of the underlying framework, while tools such as Apache NiFi and StreamSets Data Collector provide a user interface abstraction, allowing data engineers to define data flows from high-level building blocks with little or no coding.
There has been an explosion of innovation in open source stream processing over the past few years. Frameworks such as Apache Spark and Apache Storm give developers stream abstractions on which they can develop applications; Apache Beam provides an API abstraction, enabling developers to write code independent of the underlying framework, while tools such as Apache NiFi and StreamSets Data Collector provide a user interface abstraction, allowing data engineers to define data flows from high-level building blocks with little or no coding.
In this article, I’ll propose a framework for organizing stream processing projects, and briefly describe each area. I’ll be focusing on organizing the projects into a conceptual model; there are many articles that compare the streaming frameworks for real-world applications – I list a few at the end.
The specific categories I’ll cover include stream processing frameworks, stream processing APIs, and streaming dataflow systems.
What is Stream Processing?
The easiest way to explain stream processing is in relation to its predecessor, batch processing. Much data processing in the past was oriented around processing regular, predictable batches of data – the nightly job that, during “quiet” time, would process the previous day’s transactions; the monthly report that provided summary statistics for dashboards, etc. Batch processing was straightforward, scalable and predictable, and enterprises tolerated the latency inherent in the model – it could be hours, or even days, before an event was processed and visible in downstream data stores.
As businesses demanded more timely information, batches grew smaller and were processed more frequently. As the batch size tended towards a single record, stream processing emerged. In the stream processing model, events are processed as they occur. This more dynamic model brings with it more complexity. Often, stream processing is unpredictable, with events arriving in bursts, so the system has to be able to apply back-pressure, buffer events for processing, or, better yet, scale dynamically to meet the load. More complex scenarios require dealing with out-of-order events, heterogeneous event streams, and duplicated or missing event data.
While batch sizes were shrinking, data volumes grew, along with a demand for fault tolerance. Distributed storage architectures blossomed with Hadoop, Cassandra, S3 and many other technologies. Hadoop’s file system (HDFS) brought a simple API for writing data to a cluster, while MapReduce enabled developers to write scalable batch jobs that would process billions of records using a simple programming model.
MapReduce was a powerful tool for scaling up data processing, but its model turned out to be somewhat limiting; developers at UC Berkeley’s AMPLab created Apache Spark, improving on MapReduce by providing a wider variety of operations beyond just map and reduce, and allowing intermediate results to be held in memory rather than stored on disk, greatly improving performance. Spark also presented a consistent API whether running on a cluster or as a standalone application. Now developers could write distributed applications and test them at small scale – even on their own laptop! – before rolling them out to a cluster of hundreds or thousands of nodes.
The trends of shrinking batch sizes and rising data volumes met in Spark Streaming, which adapted the Spark programming model to micro-batches by time-slicing the data stream into discrete chunks. Micro-batches provide a compromise between larger batch sizes and individual event processing, aiming to balance throughput with latency. Moving to the limit of micro-batching, single-event batches, Apache Flink provides low-latency processing with exactly-once delivery guarantees.
Fast-forward to today and Flink and Spark Streaming are just two examples of streaming frameworks. Streaming frameworks allow developers to build applications to address near real-time analytical use cases such as complex event processing (CEP). CEP combines data from multiple sources to identify patterns and complex relationships across various events. One example of CEP is analyzing parameters from a set of medical monitors, such as temperature, heart rate and respiratory rate, across a sliding time window to identify critical conditions, such as a patient going into shock.
To a large extent, the various frameworks present similar functionality: the ability to distribute code and data across a cluster, to configure data sources and targets, to join event streams, to deliver events to application code, etc. They differ in the ways they do this, offering trade-offs in latency, throughput, deployment complexity, and so on.
Streaming frameworks and APIs are aimed at developers, but there is a huge audience of data engineers looking for higher-level tools to build data pipelines – the plumbing that moves events from where they are generated to where they can be analyzed. Streaming dataflow systems such as StreamSets Data Collector and Apache NiFi provide a browser-based UI for users to design pipelines, offering a selection of out-of-the-box connectors and processors, plus extension points for adding custom code.
Stream Processing Frameworks
There are at least seven open source stream processing frameworks. Most are under the Apache banner, and each implements its own streaming abstraction with trade-offs in latency and throughput:
In terms of mindshare and adoption, Apache Spark is the 800-pound gorilla here, but each framework has its adherents. There are trade-offs in terms of latency, throughput, code complexity, programming language, etc., across the different frameworks, but they all have one thing in common: they all provide an environment in which developers can implement their business logic in code.
As an example of the developer’s-eye view of stream processing frameworks, here’s the word count application from the Spark documentation, the streaming equivalent of ‘Hello World’:
object NetworkWordCount {
def main(args: Array[String]) {
if (args.length < 2) {
System.err.println("Usage: NetworkWordCount <hostname> <port>")
System.exit(1)
}
StreamingExamples.setStreamingLogLevels()
val sparkConf = new SparkConf().setAppName("NetworkWordCount")
val ssc = new StreamingContext(sparkConf, Seconds(1))
val lines = ssc.socketTextStream(args(0), args(1).toInt, StorageLevel.MEMORY_AND_DISK_SER)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}
The streaming frameworks offer power and flexibility for coding streaming applications for use cases such as CEP, but have a high barrier to entry – only developers need apply.
Stream Processing APIs
The streaming frameworks differ in aspects such as event processing latency and throughput, but have many functional similarities – they all offer a way to operate on a continuous stream of events, and they all offer their own API. In addition, stream processing API abstractions offer a another level of abstraction above the frameworks’ own APIs, allowing a single app to run in a variety of environments.
A great example of an API abstraction is Apache Beam, which originated at Google as an implementation of the Dataflow model. Beam presents a unified programming model, allowing developers to implement streaming (and batch!) jobs that can run on a variety of frameworks. At present, there are Beam ‘Runners’ for Apex, Flink, Spark and Google’s own Cloud Dataflow.
Beam’s minimal word count example (stripped of its copious comments for space!) is not that different from the Spark code, even though it’s in Java rather than Scala:
public static void main(String[] args) {
PipelineOptions options = PipelineOptionsFactory.create();
Pipeline p = Pipeline.create(options);
p.apply(TextIO.Read.from("gs://apache-beam-samples/shakespeare/*"))
.apply("ExtractWords", ParDo.of(new DoFn<String, String>() {
@ProcessElement
public void processElement(ProcessContext c) {
for (String word : c.element().split("[^a-zA-Z']+")) {
if (!word.isEmpty()) {
c.output(word);
}
}
}
}))
.apply(Count.perElement())
.apply("FormatResults", MapElements.via(new SimpleFunction<KV<String, Long>, String>() {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}))
.apply(TextIO.Write.to("wordcounts"));
p.run().waitUntilFinish();
}
So, Beam gives developers some independence from the underlying streaming framework, but you’ll still be writing code to take advantage of it.
Kafka Streams is a more specialized stream processing API. Unlike Beam, Kafka Streams provides specific abstractions that work exclusively with Apache Kafka as the source and destination of your data streams. Rather than a framework, Kafka Streams is a client library that can be used to implement your own stream processing applications which can then be deployed on top of cluster frameworks such as Mesos. Kafka Connect is connectivity software that bridges the gap between Kafka and a range of other systems, with an API allowing developers to create Kafka consumers and producers.
Streaming Dataflow Systems
Stream processing frameworks and APIs allow developers to build streaming analysis applications for use cases such as CEP, but can be overkill when you just want to get data from some source, apply a series of single-event transformations, and write to one or more destinations. For example, you might want to read events from web server log files, look up the physical location of each event’s client IP, and write the resulting records to Hadoop FS – a classic big data ingest use case.
Apache Flume was created for exactly this kind of process. Flume allows you to configure data pipelines to ingest from a variety of sources, apply transformations, and write to a number of destinations. Flume is a battle-tested, reliable tool, but it’s not the easiest to set up. The user interface is not exactly friendly, as shown here:
# Sample Flume configuration to copy lines from # log files to Hadoop FS a1.sources = r1 a1.sinks = k1 a1.channels = c1 a1.sources.r1.type = spooldir a1.sources.r1.channels = c1 a1.sources.r1.spoolDir = /Users/pat/flumeSpool a1.channels.c1.type = memory a1.sinks.k1.type = hdfs a1.sinks.k1.channel = c1 a1.sinks.k1.hdfs.fileType = DataStream a1.sinks.k1.hdfs.path = /flume/events a1.sinks.k1.hdfs.useLocalTimeStamp = true
For a broader comparison of Flume to StreamSets Data Collector, see this blog entry.
StreamSets Data Collector (SDC) and Apache NiFi, on the other hand, each provide a browser-based UI to build data pipelines, allowing data engineers and data scientists to build data flows that can execute over a cluster of machines, without necessarily needing to write code. Although SDC is not an Apache-governed project, it is open source and freely available under the same Apache 2.0 license as NiFi, Spark, etc.
This pipeline, taken from the SDC tutorial, reads CSV-formatted transaction data from local disk storage, computes the credit card issuing network from the credit card number, masks all but the last 4 digits of the credit card number, and writes the resulting data to Hadoop:
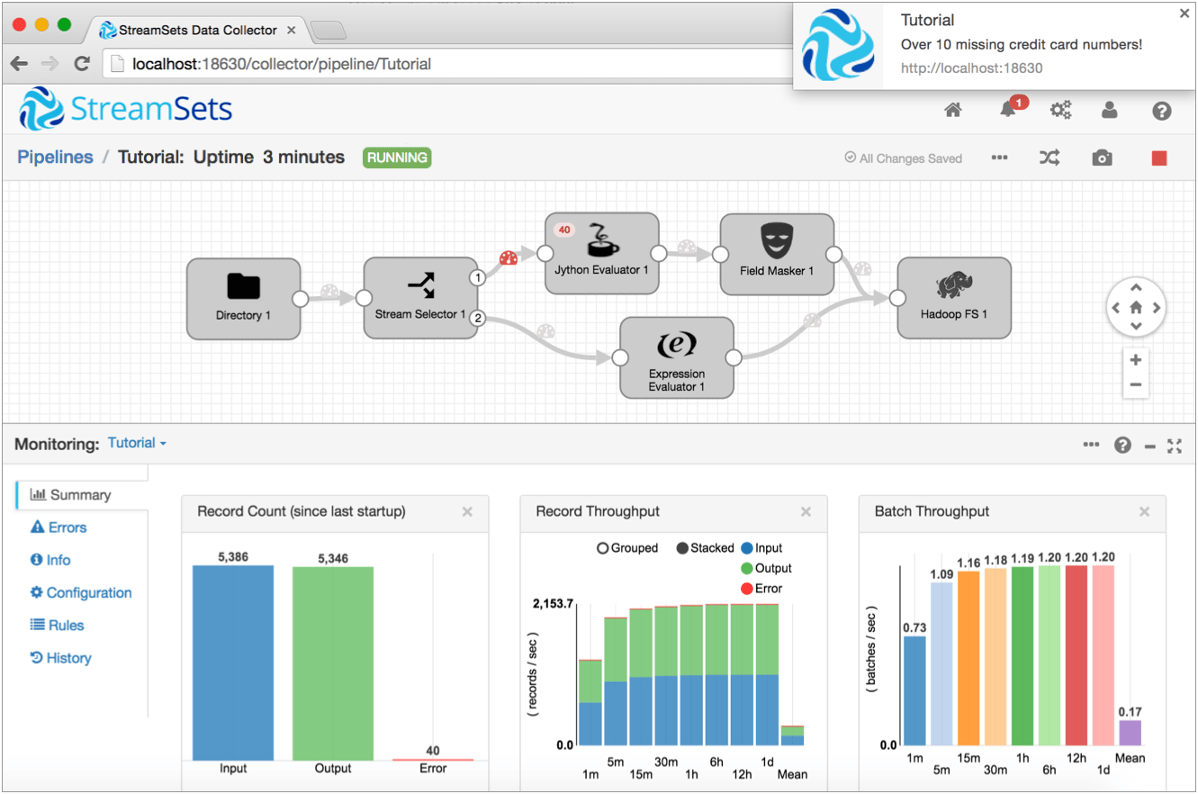
Of course, not every problem can be solved by plugging together prebuilt processing stages, so both SDC and NiFi allow customization via scripting languages such as Scala, Groovy, Python and JavaScript, as well as their common implementation language, Java.
Aside from UI, another aspect of the evolution of stream processing tools from Flume to NiFi and SDC is distributed processing. Flume has no direct support for clusters – it’s up to you to deploy and manage multiple Flume instances and partition data between them. NiFi can run either as a standalone instance or distributed via its own clustering mechanism, although one might expect NiFi to transition to YARN, the Hadoop cluster resource manager, at some point.
SDC can similarly run standalone, as a MapReduce job on YARN, or as a Spark Streaming application on YARN and Mesos. In addition, to incorporate stream processing into a pipeline, SDC includes a Spark Evaluator, allowing developers to integrate existing Spark code as a pipeline stage.
So What Should I Use?
Selecting the right system for your specific workload depends on a host of factors ranging from the functional processing requirements to service level agreements that must be honored by the solution. Some general guidelines apply:
- If you are implementing your own stream processing application from scratch for an analytical use case such as CEP, you should use one of the stream processing frameworks or APIs.
- If your workload is on the cluster and you want to set up continuous data streams to ingest data into the cluster, using a stream processing framework or API may be overkill. In this case you are better off deploying a streaming dataflow system such as Flume, NiFi or SDC.
- If you want to perform single-event processing on data already residing in the cluster, use SDC in cluster mode to apply transformations to records and either write them back to the cluster, or send them to other data stores.
In practice, we see enterprises using a mix of stream processing and batch/interactive analytics applications on the back end. In this environment, single-event processing is handled by a system like SDC, depositing the correct data in the data stores, keeping analytical applications supplied with clean, fresh data at all times.
Conclusion
The stream processing landscape is complex, but can be simplified by separating the various projects into frameworks, APIs and streaming dataflow systems. Developers have a wide variety of choices in frameworks and APIs for more complex use cases, while higher-level tools allow data engineers and data scientists to create pipelines for big data ingest.
References
This article focuses on the big picture and how all of these projects relate to each other. There are many articles that dive deeper, providing a basis for selecting one or more technologies for evaluation. Here are a few, in no particular order:
- All the Apache Streaming Projects: An Exploratory Guide
- Stream Processing Everywhere – What to Use?
- How-to: Build a Complex Event Processing App on Apache Spark and Drools
- Real-Time Stream Processing as Game Changer in a Big Data World with Hadoop and Data Warehouse
- Distributed Stream Processing Frameworks for Fast & Big Data
- An Overview of Apache Streaming Technologies
- Explained: Stream Processing, Streaming Data, and Streaming Data Pipelines