Imagine asking Amazon Alexa or Google Home to run your ETL, data processing, and automate your data pipelines. For example, “Start my data pipeline on Amazon EMR“, “How many active jobs do I have running on Databricks?“, or “Stop my machine learning pipeline on Snowflake” — all without firing up your computer or asking an admin or your favorite data engineer to do the work for you.
The concept of conversing with a computer is very interesting and has been around for a while — think Star Trek’s “LCARS” and Hal from “A Space Odyssey”. While we might be a long way off from those realities, recent advancements from Amazon, Google, Microsoft, IBM and other natural language and AI technologies have brought us closer. We can expect a lot of new, creative services being built in the near future.
Meanwhile, in the big data and analytics space, with the massive amounts of data generated along with advancements in machine learning algorithms and the speed at scale of computing, we’re already seeing the role Artificial Intelligence (AI) and Machine Learning (ML) plays in powering big data analytics. In ways and at speeds never experienced before. These systems are already melding with the technological innovations in the peripheral areas like Internet of Things (IoT), cloud computing, and natural language processing.
“The movement towards conversational interfaces will accelerate,” — Stuart Frankel, CEO, Narrative Science. “The recent, combined efforts of a number of innovative tech giants point to a coming year when interacting with technology through conversation becomes the norm. Are conversational interfaces really a big deal? They’re game-changing. Since the advent of computers, we have been forced to speak the language of computers in order to communicate with them and now we’re teaching them to communicate in our language.”
“Alexa, Start My Data Pipeline”
At StreamSets, the approach of developing products and features has always been one of API-first.
What is API-First Approach
This concept refers to designing and developing the actual API before implementation of the functionality. When developing new features, the functionality is first exposed as an API. Then the engineers responsible for the rest of the application tend to be the first consumers of this API. This ensures the quality, predictability, and stability of the functionality and helps answer questions like: What functionality will the API have?, What data might it expose? , What will the developer experience be?, How will it scale?
This approach allows the team to chime in on the proposed direction and functionality… early and often like in an agile environment. Once the direction has been solidified, the design serves as the contract and team members begin working towards the implementation.
What this also means is that things you can do on StreamSets DataOps Platform via the easy-to-use GUI, you can perform those operations using the platform’s APIs as well. For example,
- Starting or stopping a data pipeline
- Getting number of active jobs
- Scheduling a job to run at a particular hour on a given day
- Retrieving metrics around executor uptime, memory/CPU usage by executor at JVM level, etc.
- Generating reports
- Setting up alerts and notifications
These (and many more) APIs are used by customers for automating tasks, building dashboards, etc. So… as you’d imagine you can also use these StreamSets DataOps Platform APIs to build natural language experience and integrate with conversational platforms like Amazon’s Alexa and that’s exactly what I’ve done!
In this blog, I’ve outlined my approach on creating this mashup to build Alexa-enabled StreamSets. Let’s dive right in!
“Alexa, Play Demo Video”
As you saw and heard in the demo video, the application interacts with the StreamSets DataOps Platform via its APIs in response to voice commands delivered over Amazon Echo. The application is built to respond to voice commands like, “How many jobs do I have?”, “How many active jobs do I have?”, “Start a job”, “Stop a job”, etc.
Note that the visual in the demo video is just to show that the actions are actually being carried out via voice commands. In reality, you could very well be sitting across the room or even driving a Alexa-enabled car while interacting with the platform.
So, have I piqued your interest? :)
Create Your Own Alexa Experience
Here’s the approach I took to create Alexa-enabled StreamSets.
Prerequisites
- Access to StreamSets Control Hub
- Developer account on Amazon
- Ability to create Alexa Skill
- Ability to create AWS Lambda function
- ASK SDK Core package
- Programming in Python
Alexa Skills
After logging into the developer console, I selected Create Skill >> Custom (model) >> Start from Scratch model and template. Then, I configured the skill with the following:
- Skill Invocation Name: Stream Sets (such that Alexa can properly pronounce StreamSets :))
- Interaction Model >> Intents: I added these intents.
- Assets >> Slot Types: I added these slot types.
IMP: After you’ve created your Alexa skill, make note of “Your Skill ID” under Endpoint. You will need this ID when adding the Alexa Skills Kit trigger for your AWS Lambda function.
Learn more about Alexa Skills.
AWS Lambda
After logging into AWS Developer Console, I selected the AWS Lambda service >> Create function >> Author from scratch option. Then, I configured the function with the following:
-
- Function name: dash (could be anything… even your pet’s name :))
- Runtime: Python 3.7 (since my application is written against this version)
- Handler: streamsets.handler (name of the application/Python file with .handler)
- Add trigger
- After the Lambda function was created, I added an Alexa Skills Kit trigger and enabled Skill ID verification by providing my Alexa Skill’s ID. This is to verify the Skill ID in an incoming request from a Skill.
- Code
- Under the Code tab, I selected Upload from >> .zip file and uploaded my Python application along with its dependencies.
- Protip: It is very important that you know what to include in the compressed .ZIP file and its overall folder structure. (It took me a while to figure this out!) Basically, you need to compress all the contents under the application’s site-packages folder after you’ve copied over your application code file and any config files it depends on into the root of the application’s site-packages folder. In my case, that path looked like this: /AskStreamSets/tree/main/skill_env/lib/python3.7/site-packages
IMP: After you’ve created your AWS Lambda function, copy “Function ARN” of that function. Then, go back to your Alexa Skill dashboard and paste the AWS Lambda function ARN in Endpoint >> AWS Lambda ARN >> Default Region.
Learn more about hosting a custom skill as an AWS Lambda Function.
Test Your Alexa Skill
At this point, you’re ready to see your Alexa Skill and application in action!
If you don’t have access to a readily configured Amazon Echo or Alexa Device, that’s OK! You can still test your skill and application right from your browser! Just go to the Test section from your Skill’s dashboard and follow the instructions. See below.
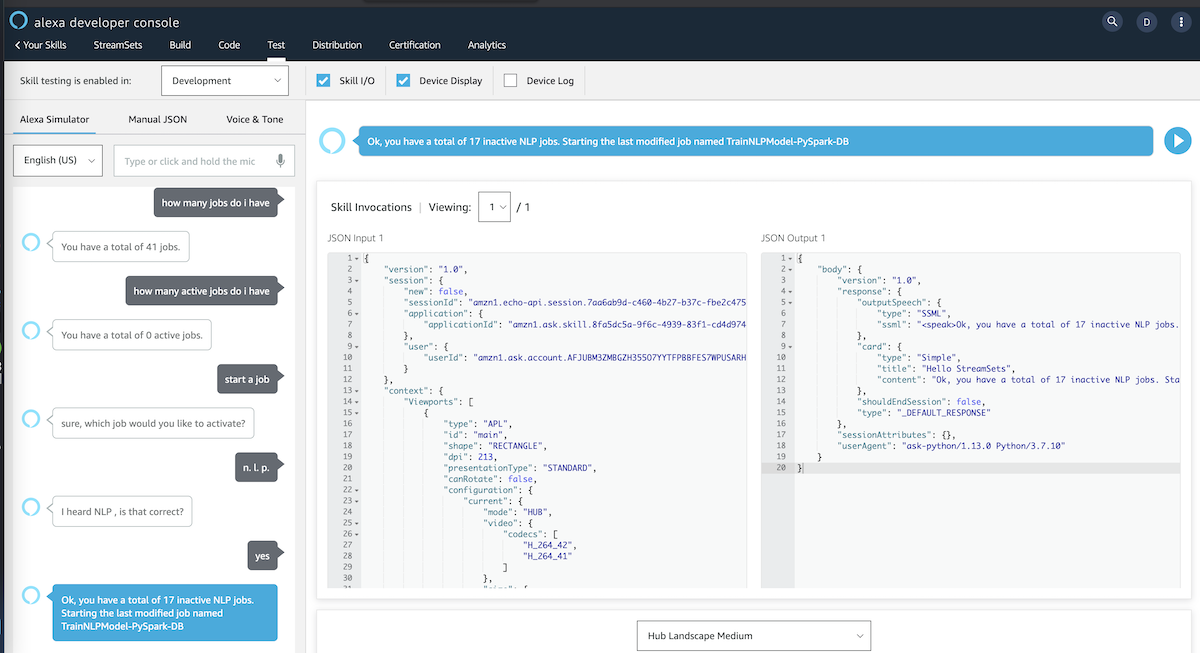
On the left, you can either type or hold down the microphone icon and provide voice commands. If all goes well, you will hear playback of audio responses and actions, if any, being triggered behind the scenes based via the intent handler.
That’s it! You’ve just built natural language experience with StreamSets DataOps Platform.
Sample Project On GitHub
If you’d like to get a head start on creating the natural language experience, you can checkout my project on GitHub.
Summary
Learn more about building data pipelines with StreamSets. If you like this topic and would like to continue similar conversations focused on APIs and mashups, connect with me on LinkedIn and Twitter.