 When it comes to loading data into Apache Hadoop™, the de facto choice for bulk loads of data from leading relational databases is using Apache Sqoop Commands. After initially entering Apache Incubator status in 2011, it quickly saw wide spread adoption and development, eventually graduating to a Top-Level Project (TLP) in 2012.
When it comes to loading data into Apache Hadoop™, the de facto choice for bulk loads of data from leading relational databases is using Apache Sqoop Commands. After initially entering Apache Incubator status in 2011, it quickly saw wide spread adoption and development, eventually graduating to a Top-Level Project (TLP) in 2012.
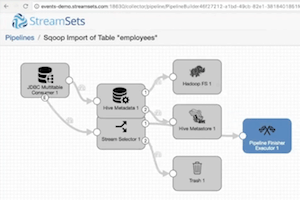
In StreamSets Data Collector Engine we now have capabilities that enable SDC to behave in a manner almost identical to Sqoop commands. Now customers can use SDC as a way to modernize Sqoop-like workloads, performing the same load functions while getting the ease of use and flexibility benefits that SDC delivers.


 Three months into my journey here at StreamSets and I’ve had a chance to talk with
Three months into my journey here at StreamSets and I’ve had a chance to talk with