Visualizing and Analyzing Salesforce Data with Neo4j
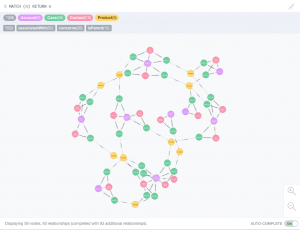 Graph databases represent and store data in terms of nodes, edges and properties, allowing quick, easy retrieval of complex hierarchical structures that may be difficult to model in traditional relational databases. Neo4j is an open source graph database widely deployed in the community; in this blog entry I’ll show you how to use StreamSets Data Collector to read case data from Salesforce and load it into the graph database using Neo4j’s JDBC driver.
Graph databases represent and store data in terms of nodes, edges and properties, allowing quick, easy retrieval of complex hierarchical structures that may be difficult to model in traditional relational databases. Neo4j is an open source graph database widely deployed in the community; in this blog entry I’ll show you how to use StreamSets Data Collector to read case data from Salesforce and load it into the graph database using Neo4j’s JDBC driver.
 I run StreamSets Data Collector on my MacBook Pro. In fact, I have about a dozen different versions installed – the latest, greatest 2.5.0.0, older versions, release candidates, and, of course, a development ‘master’ build that I hack on. Preparing for tonight’s
I run StreamSets Data Collector on my MacBook Pro. In fact, I have about a dozen different versions installed – the latest, greatest 2.5.0.0, older versions, release candidates, and, of course, a development ‘master’ build that I hack on. Preparing for tonight’s 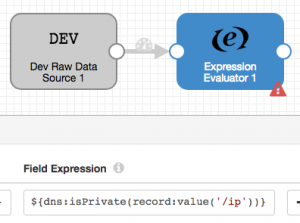 One of the most powerful features in
One of the most powerful features in 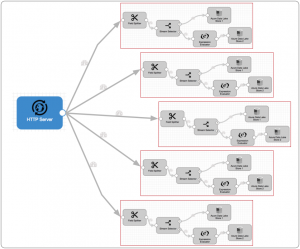
 There has been an explosion of innovation in open source stream processing over the past few years. Frameworks such as Apache Spark and Apache Storm give developers stream abstractions on which they can develop applications; Apache Beam provides an API abstraction, enabling developers to write code independent of the underlying framework, while tools such as Apache NiFi and StreamSets Data Collector provide a user interface abstraction, allowing data engineers to define data flows from high-level building blocks with little or no coding.
There has been an explosion of innovation in open source stream processing over the past few years. Frameworks such as Apache Spark and Apache Storm give developers stream abstractions on which they can develop applications; Apache Beam provides an API abstraction, enabling developers to write code independent of the underlying framework, while tools such as Apache NiFi and StreamSets Data Collector provide a user interface abstraction, allowing data engineers to define data flows from high-level building blocks with little or no coding.
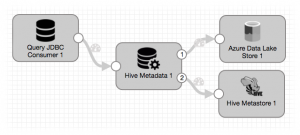 One of the great things about
One of the great things about  The
The