When it comes to creating and managing your smart data pipelines, the graphical user interfaces of StreamSets Control Hub and StreamSets Data Collector Engine put the complete power of our robust Data Operations Platform at your fingertips. There are times, however, when a more programmatic approach may be needed, and those times will be significantly more enjoyable with the release of version 3.2.0 of the StreamSets SDK for Python. In this post, I’ll describe some of the SDK’s new functionality and show examples of how you can use it to enable your own data use cases.
Note on StreamSets SDK for Python
SDK for Python is part of our subscription offering, and requires a license key to work. For installation instructions, please see our documentation.
New Data Collector Engine Control Functionality
The latest release of the StreamSets SDK for Python includes a number of new features to automate interactions with StreamSets Data Collector Engine instances. To demonstrate these, we’ll follow a typical development workflow where a user designs a pipeline, runs it and takes a snapshot to validate that the data is being processed as expected, confirms that neither the Data Collector instance nor the pipeline complain of any errors, and then repeats the process until the expected results are achieved. We’ve picked just a handful of new functionality to demonstrate below, but read our SDK for Python documentation for more details.
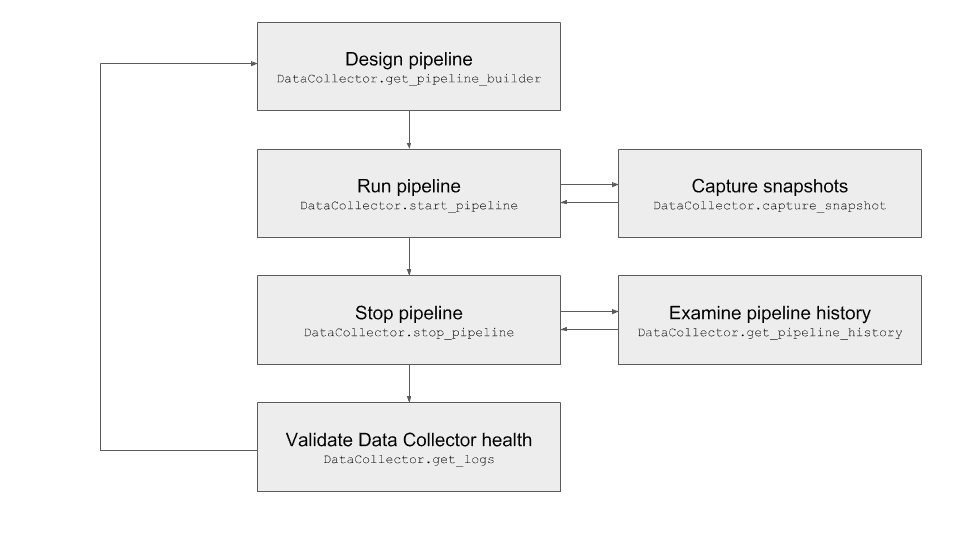
Building Pipelines
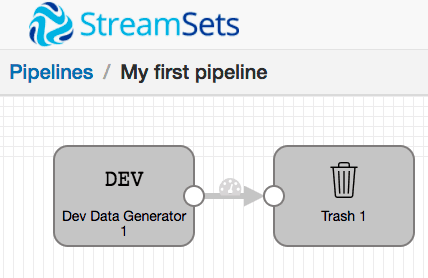
After opening a Python 3 interpreter and creating an instance of the DataCollector class to communicate with your Data Collector instance, pipelines are built with a PipelineBuilder object (in the example below, we assume a Data Collector running on localhost:18630):
from streamsets.sdk import DataCollector
data_collector = DataCollector(server_url='http://localhost:18630')
builder = data_collector.get_pipeline_builder()
dev_data_generator = builder.add_stage('Dev Data Generator')
trash = builder.add_stage('Trash')
dev_data_generator >> trash
pipeline = builder.build('My first pipeline')
data_collector.add_pipeline(pipeline)
Starting and Stopping Pipelines
This one’s pretty self-explanatory. Note that the DataCollector.start_pipeline method will, by default, wait for the pipeline to reach a RUNNING or FINISHED state before returning. To make it return immediately, add wait=False to the argument list.
data_collector.start_pipeline(pipeline) # starts a pipeline data_collector.stop_pipeline(pipeline) # stops the pipeline
Capturing and Examining Pipeline Snapshots
The DataCollector.capture_snapshot method returns a streamsets.sdk.sdc_api.SnapshotCommand instance, which lets you monitor the state of the snapshot asynchronously. By accessing this object’s snapshot attribute, we can wait for the snapshot to be completed and then access its records (below, we’re looking at the first record output by the Dev Data Generator stage). Also note that if your pipeline is stopped and you’d like to capture a snapshot of the first batch upon starting it, simply add the start_pipeline=True argument when capturing the snapshot:
snapshot = data_collector.capture_snapshot(pipeline).snapshot record = snapshot[dev_data_generator].output[0]
Getting Pipeline History
Again, pretty self-explanatory. In our case, we’ll go a step further and query the latest entry in our pipeline history for metrics (e.g. to determine how many batches were processed by the pipeline):
history = data_collector.get_pipeline_history(pipeline)
history.latest.metrics.counter('pipeline.batchCount.counter').count
![]()

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
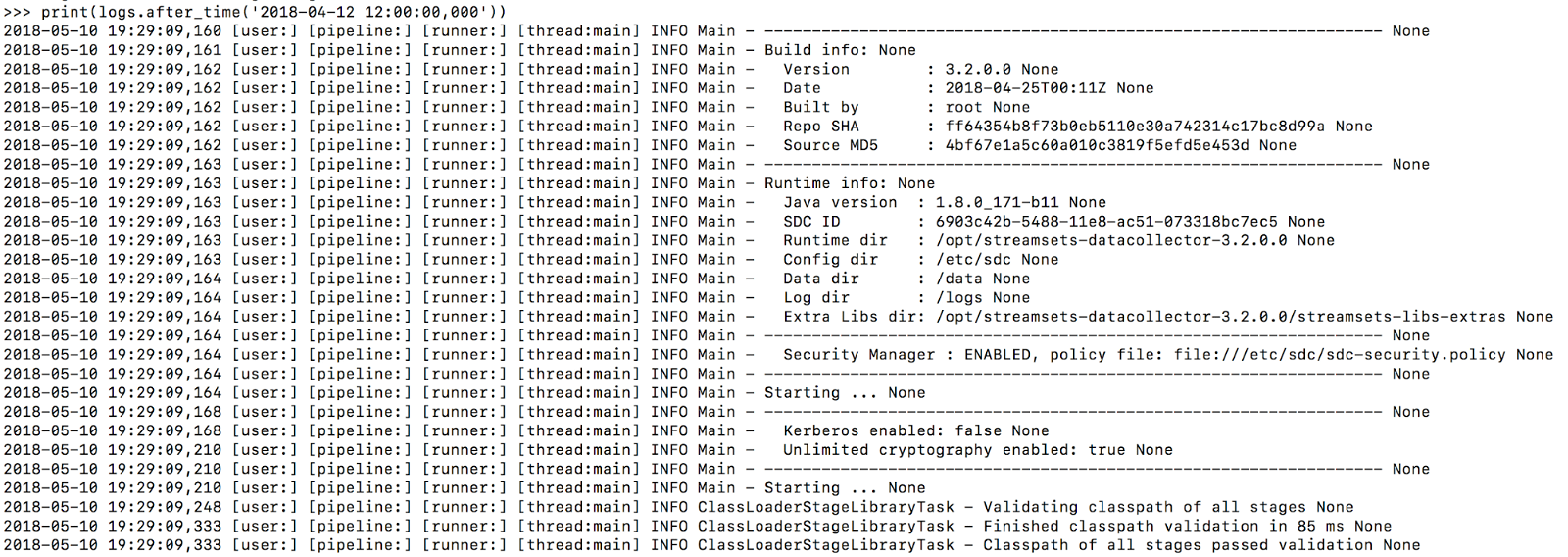
Getting Data Collector Logs
The streamsets.sdk.sdc_models.Log instance returned by this function can either be printed directly or manipulated using the Log.after_time or Log.before_time methods:
logs = data_collector.get_logs()
print(logs.after_time('2018-05-10 19:00:00,000'))
Support for StreamSets Control Hub-Registered Data Collector Instances
Users looking to interact with Data Collectors registered with StreamSets Control Hub can now do so. After instantiating the DataCollector class tied to a ControlHub instance, every command described above should work just as with any other Data Collector instance:
from streamsets.sdk import ControlHub, DataCollector control_hub = ControlHub(server_url='https://cloud.streamsets.com', username=<username>, password=<password>) data_collector = DataCollector(server_url='http://localhost:18630', control_hub=control_hub)
Clearer Compatibility Story
With this release, the StreamSets SDK for Python has moved to a versioning schema that aligns it with releases of StreamSets Data Collector Engine and StreamSets Control Hub. Moving forward, that means more clarity about which versions of StreamSets components are certified to work with SDK releases and more predictability about when new StreamSets features will be supported by the SDK.
What’s Next with SDK for Python?
We are committed to continue adding more functionality to the StreamSets SDK for Python to enable our customers’ evolving data operations needs. Upcoming releases will greatly expand upon integration with StreamSets Control Hub to help enterprises looking to take advantage of its rapidly-growing feature set scale up their design, execution, and operations efforts.
We’re also really excited about this release because it finally lets us pull back the curtains on the StreamSets Test Framework, which is built on top of the StreamSets SDK for Python. This is the platform we use to test the quality of our StreamSets product line, and we’ll go into more detail about what it is, how it works, and how we use it in a future series of blog posts. Stay tuned!
Want to start building smart data pipelines today? Start with a demo from one of our experts.