Last week we announced the results of a survey of over 300 enterprise data professionals conducted by Dimensional Research and sponsored by StreamSets. We were trying to understand the market’s state of play for managing their big data flows. What we discovered was that there is an alarming issue at hand: companies are struggling to detect and keep bad data out of their stores.
There is a bad data problem within big data.
Bad Data: What to Do?
When we asked data pros about their challenges with big data flows, the most-cited issue was ensuring the quality of the data in terms of accuracy, completeness and consistency, getting votes from over ⅔ of respondents. Security and operations were also listed by more than half. The fact that quality was rated as a more common challenge than even security and compliance is quite telling, as you usually can count on security to be voted the #1 challenge for most IT domains.

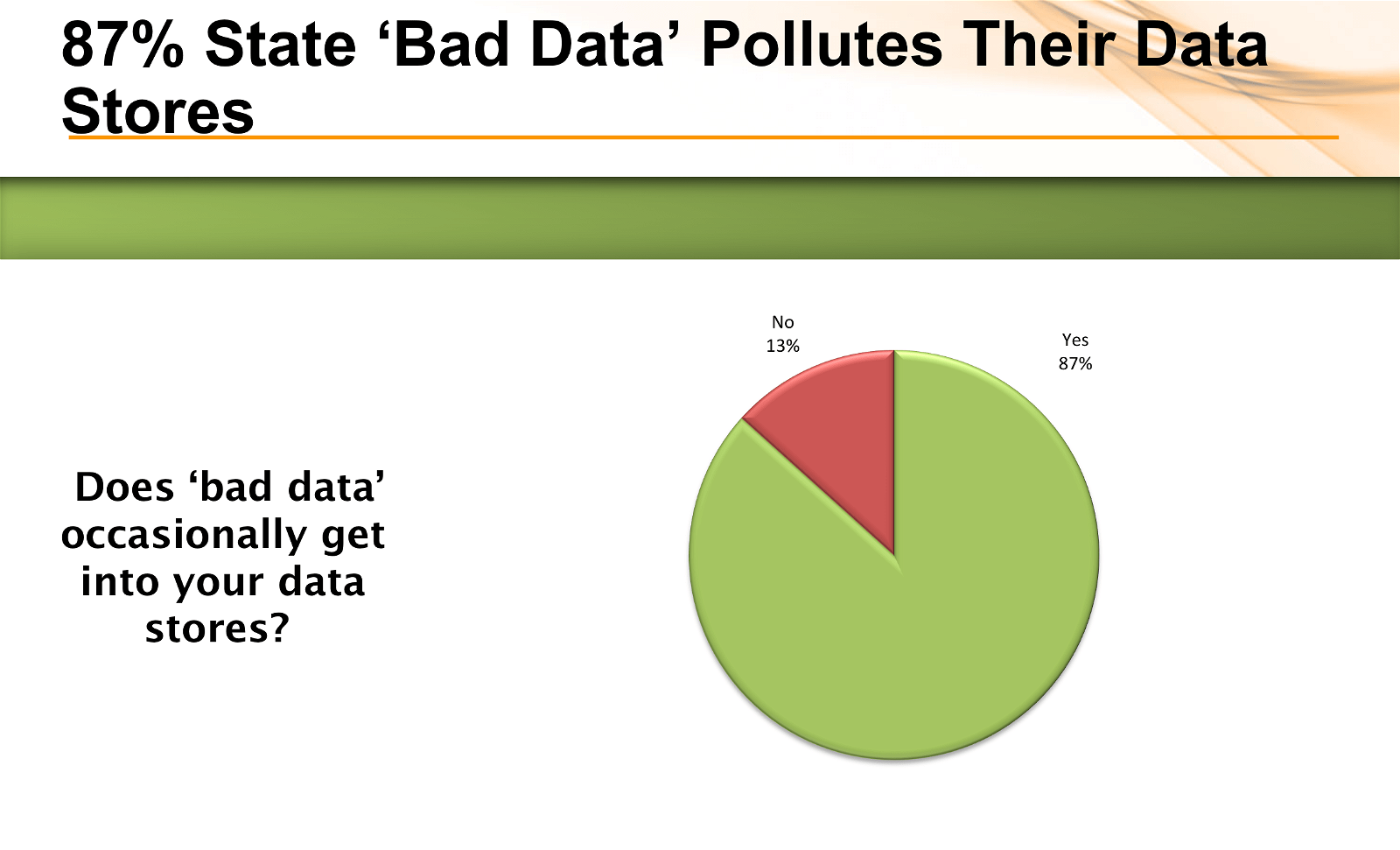
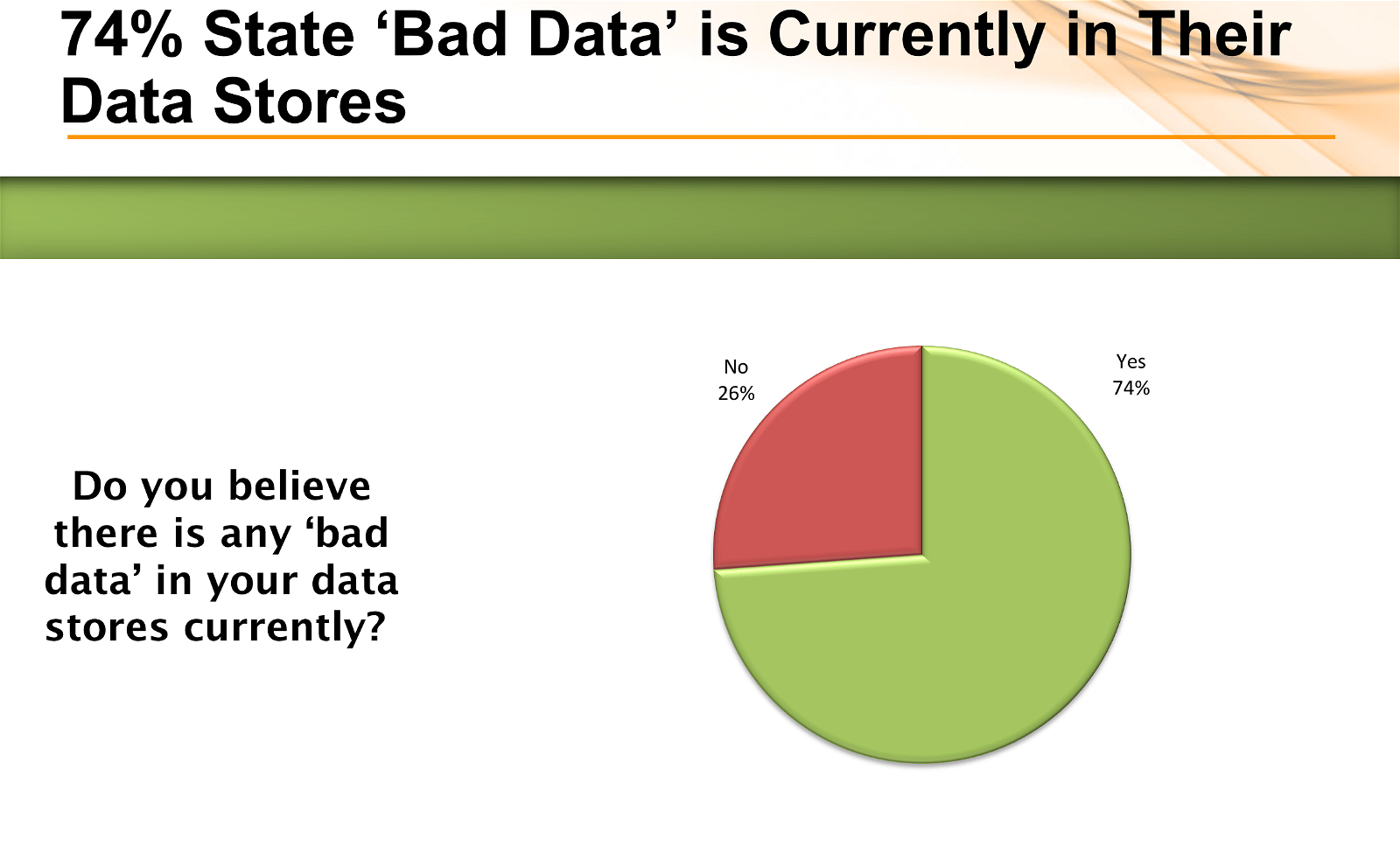
The painful reality of this challenge was hammered home by the number of people who admitted to flowing bad data into their stores (87%) or knowingly having bad data in their stores (74%). On an equally disturbing note, nearly one in 8 respondents (12%), answered “I don’t know” to the question about bad data in their stores, which may point to an issue around data governance.
Data drift plus hand coding and create quality issues
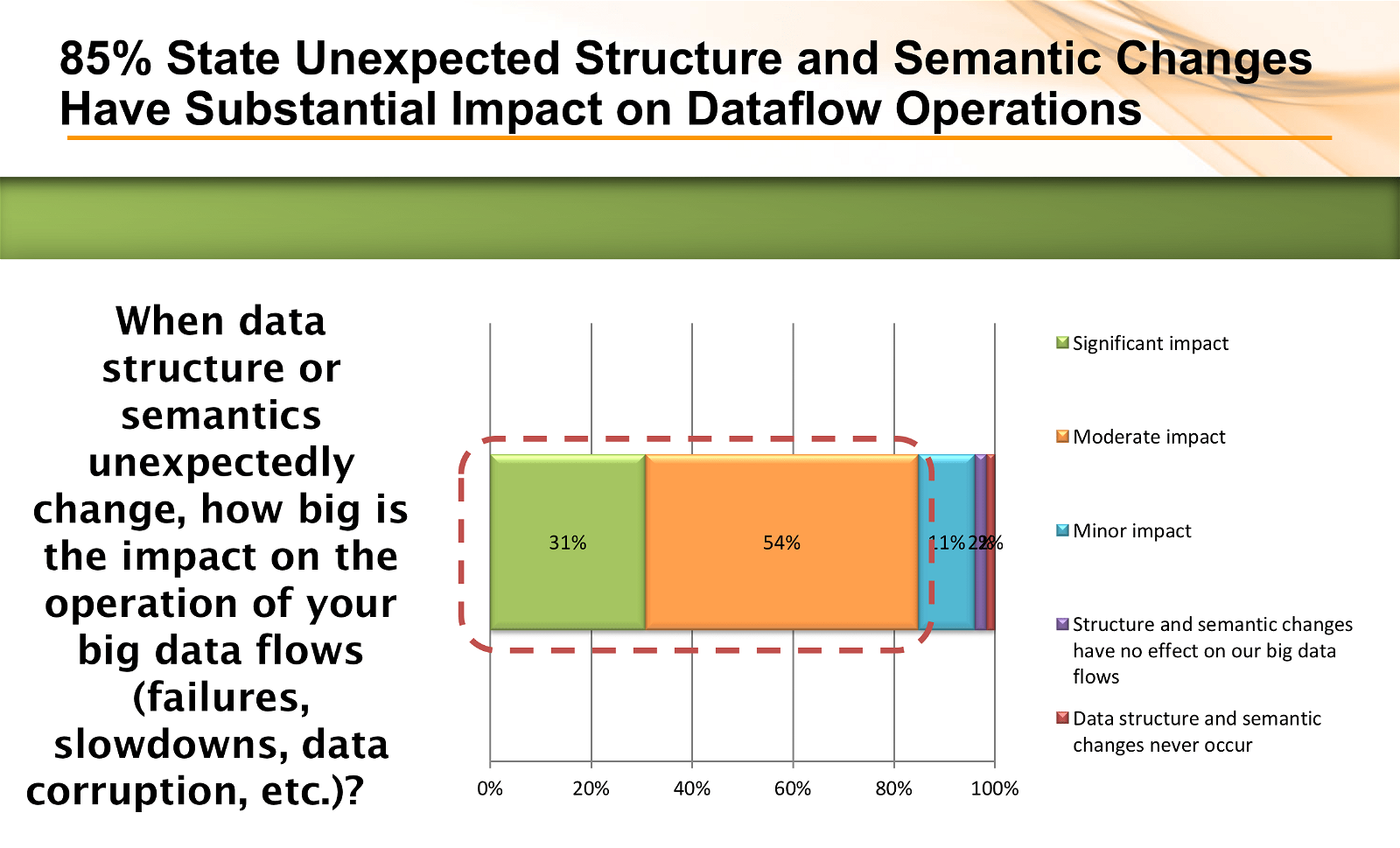
At StreamSets we believe that the quality issue within big data flows is related to data corrosion and data loss caused by data drift. Data drift is defined as unexpected, unannounced and unending changes to schema and semantics that occur at the data source and usually go undetected as they flow into data stores or to analytic applications. In the survey, a dramatic majority of respondents acknowledged that data drift creates a significant impact on their data flow operations such as pipeline failures, slowdowns or data corruption.
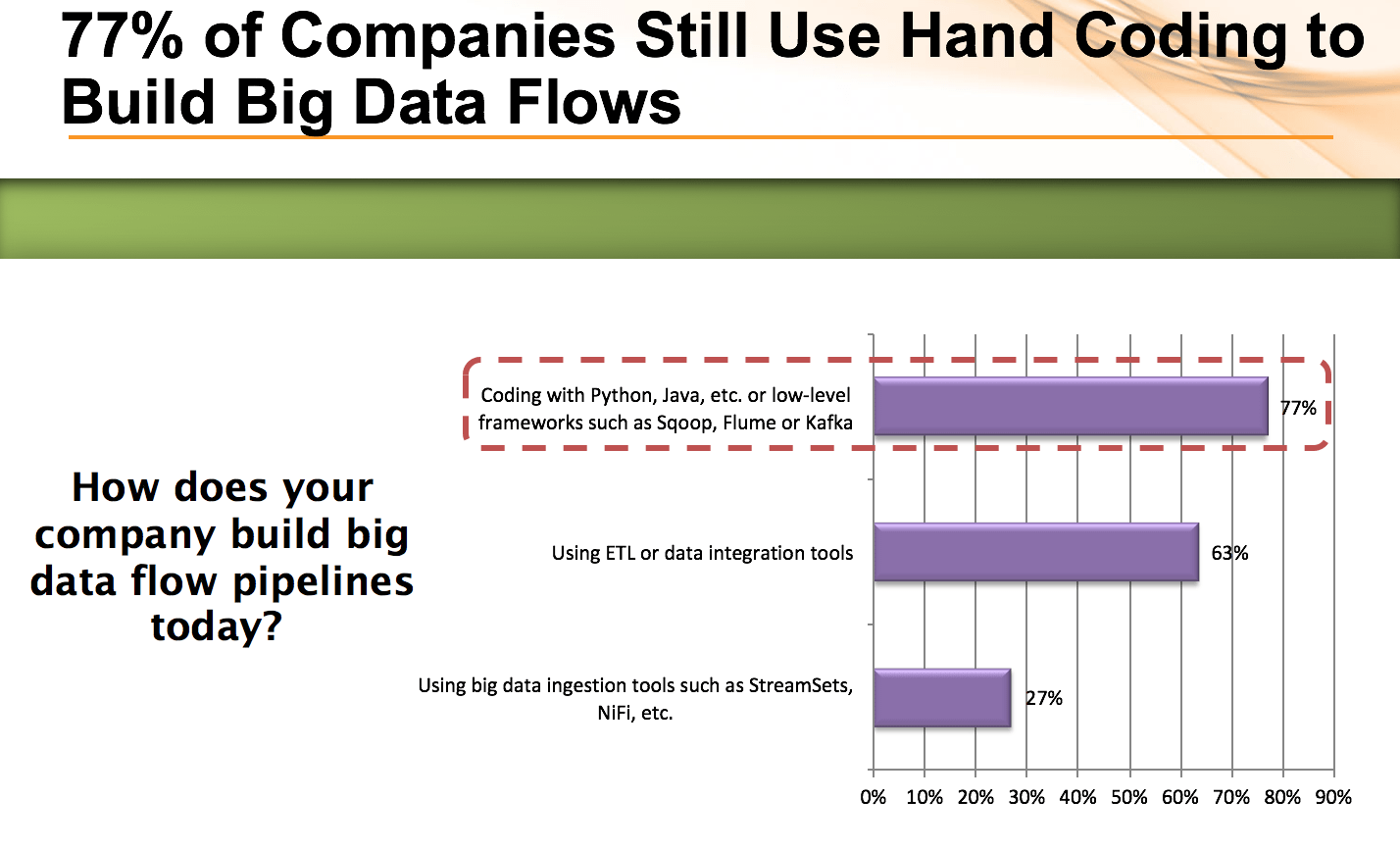
Part of the reason for this high impact from data drift may be the continued reliance on hand-coded data pipelines. Low-level coded solutions tends to be brittle in the face of schema changes and usually are not instrumented to monitor, detect or deal with changing schema or semantics (opaqueness). Nearly 4 in 5 respondents still use hand-coding. As you can see ETL tools are also heavily used and they too suffer from being brittle in the face of change and opaque when it comes to operational visibility.
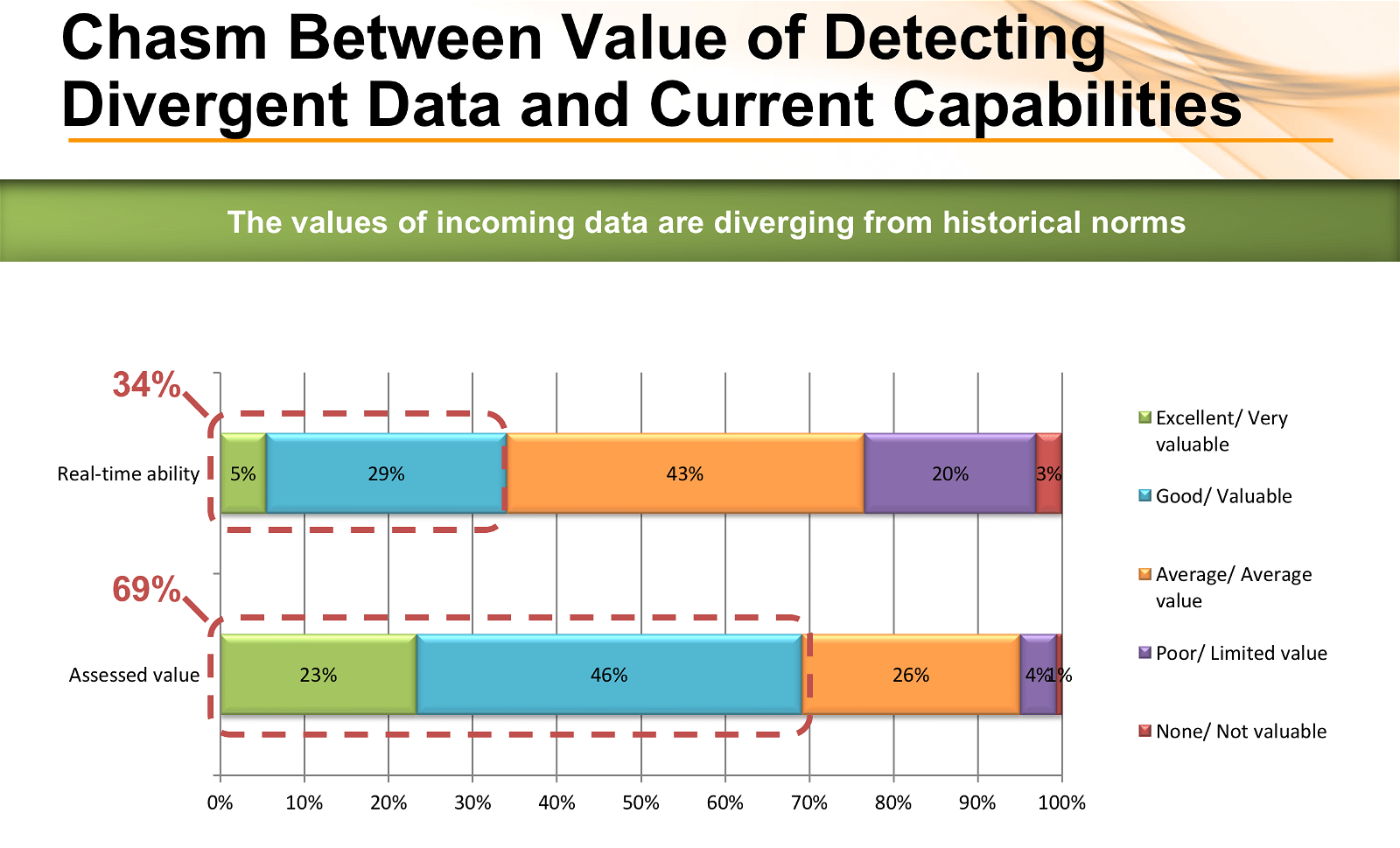
You can’t address what you can’t detect
Lastly, we also surveyed on abilities and desires related to different areas of operational management. Given this preponderance of bad data caused in part by data drift and hand coding, it’s not surprising that detecting changes to data while it is in motion is the domain where enterprises felt weakest, and where there was the biggest gap between current capabilities and preferred state. Only 34% graded themselves as “good” or “excellent” at detecting data divergence; but more than twice that percentage (69%) considered detecting divergent data to be a valuable capability.
What do you do about it?
So what is the appropriate response to this challenge of data drift and inadequate tooling? Given we designed StreamSets Data Collector to detect and handle data drift in big data flows, with the ability to fully introspect data in motion, we feel it is a useful tool for enterprises attempting to get control of data upon ingest, before it lands in the data store.
If you suspect (or know) you have an issue with data drift and bad data in your stores, please download the open source StreamSets Data Collector and give it try. We’re currently offering a free Getting Started live consulting session as well to help you get going.