
 SME has worked closely with industry leaders for two decades to solve data pain points. Our Subject Matter Experts are skilled in multiple verticals and pride themselves in being a full life cycle partner invested in each client’s success. SME is dedicated to leading its clients with a holistic view and personalized vision. We will supply innovative and sustainable solutions to ensure organizational excellence for our customers. We are committed to superior quality service based on integrity and business ethics that strive for continuous improvement. We deliver valuable services to our clients by conducting our operations prudently and strategically through the application of proven methodologies and analytical software.
SME has worked closely with industry leaders for two decades to solve data pain points. Our Subject Matter Experts are skilled in multiple verticals and pride themselves in being a full life cycle partner invested in each client’s success. SME is dedicated to leading its clients with a holistic view and personalized vision. We will supply innovative and sustainable solutions to ensure organizational excellence for our customers. We are committed to superior quality service based on integrity and business ethics that strive for continuous improvement. We deliver valuable services to our clients by conducting our operations prudently and strategically through the application of proven methodologies and analytical software.
In this case study, the SME Team addressed the data integration, data automation, and data governance need. The customer in this case study is an Utility Co-op facing challenges around data collection, how that data is being processed, where it needs to go and the SLAs that are associated with that, for their smart meter deployment. The original blog was published on SME Solutions website: https://blog.smesgroup.com/continuous-data-delivery
THE CHALLENGE
The utility wanted to keep building analytical, reporting, and operational use cases but as more data was implemented, too much strain was being applied to the current system and the need for real-time or right-time data was not being met.
Oracle and SQL Server are managing the operational use cases, but for the analytical use cases, trying to do the data blending, data transformation, as well as the analytical processing was slowing the system down tremendously. Some of those jobs were not being completed within a reasonable amount of time, some even taking overnight to complete. They were facing significant risk of their pipelines breaking because of the increased data volume, especially as the smart meter deployment expanded and more meters were added.
KEY INITIATIVE AND APPROACH
SME came in to assess the current DataOps process and recommended that a modern pipeline solution would bring data sources and destinations together and enable data to move in real-time. The recommended solution would prevent the need for the data engineer to repeatedly repair the pipelines when the data was not delivered, or the data was incorrect.
SME’s approach was designed to meet the following requirements:
- Move data from operational databases, data lakes, and applications into multiple downstream destinations.
- Reduce the pipeline complexity, even with the diverse systems, to make the data easier to manage.
- Transform the data from semi-structured to structured to join the data, without the reduction of speed.
- Visibility into pipelines breaks and a process to handle those errors.
The key areas to address those requirements include data integration and automation, data storage and processing, and data governance.
Data integration and automation, taking data from the different systems and integrating it into other systems as well as automating the pipeline movements, automating the transformation.
Data storage and processing, delivering data to a data lake and a data warehouse simultaneously as well as in different stages throughout the pipelines to achieve different levels of data organization.
Data governance, the overall control plane that ensures that we have rules or guidelines in place that if something does break, we can use error handling to make sure that that data comes through properly. SME recommended applying the governance rules upstream as it is being collected as opposed to at the ETL, data warehouse, or BI tool levels.
BUILDING AUTOMATED PIPELINES
The first step was to capture the AMI reads that were being generated from each of the smart meters. This raw data comes in at varying intervals, so implementing a streaming pipeline to write to destinations was the optimal choice.
Utilizing StreamSets Data Collector Engine, the SME team has the option to collect from a wide variety of different sources outside of just databases, including data lakes, APIs, and sensors.
The data coming through the pipeline was written to a Kafka stream that is connected to more pipelines for additional processing. With the pipeline in place, the solution returns summary statistics on the good records that are going through, error records, record throughput batch processing, and more. This helped the utility’s data engineer to understand the flow of data, see how fast data is coming through, and if there are any bottlenecks. Bottlenecks were discovered and determined to be certain aspects of the source network. Improvements were made to shape the data into a better state.
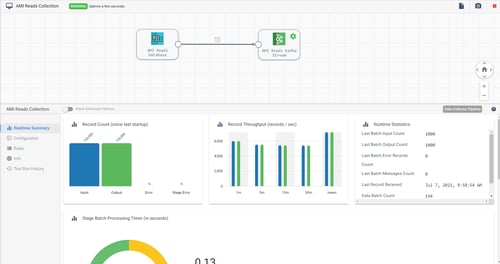
With data flowing through the pipeline, a process for error handling needed to be put in place. One example of the errors observed was when we were expecting an operating company to be listed for a particular meter but was not, we made a rule to flag that data point. And as opposed to stopping the whole pipeline or breaking the pipeline, the individual component is sent into a dedicated error handling pipeline where the utility uses the address of that meter to determine the operating company. Once again, the data engineer saves time from not having to intervene or repair.
TRANSFORMING DATA AND ADDRESSING DATA DRIFT
After the data had been processed in the collection streams, SME utilized StreamSets Transformer Engine for the heavy-duty data transformations.
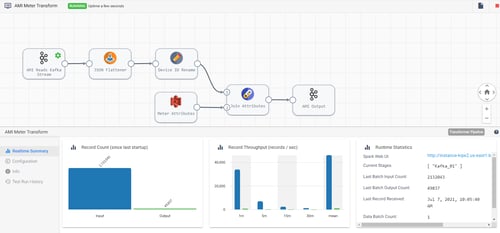
The Transformer pipelines captures the Kafka stream and joins the data with reference data from the company data lake. Transformer leverages the power of Apache Spark to manipulate and enrich the data in a near identical interface to Data Collector. The intuitive transformation capabilities allowed a lot of the work to get the data ready to be handled without manual effort from the data engineer and provides the BI team with data that does not require additional work.
Because the Spark clusters were separated from the Transformer Engine instance, SME was able to accomplish thorough performance testing to determine the optimal and most cost effective amount of processing power.
The transformed data was written back out to Kafka and streamed to a final Data Collector Engine pipeline. Built to handle the distribution of the data to the various destinations, the pipeline also contained real-time processing to further enhance the data for analysis. The origin was JSON data that needed to be flattened and ordered so that it comes through in a structured format, all performed within the pipeline itself without effort from the data engineer. This alleviated the data analysts from having to work with JSON, which was not a part of their skillset. At this stage, the data was delivered to the landing zone of the data lake.
Simultaneously, the stream forked to deliver the data to the company’s Snowflake data warehouse. Prior to landing there, a mask policy was put in place for the Account field to preserve customer privacy in the analytics. Also, through testing it was found that there were missing zip codes for certain records. SME sent these records to the data lake for error handling while the rest of the data was delivered to the data warehouse. To account for any potential data drift, new columns are automatically created on the fly. Previously, it was common for the data engineer to receive unexpected calls about fixing the pipeline when everything stopped because of a new field that was unexpected. Specific data and data drift rules were used to create real-time email alerts.
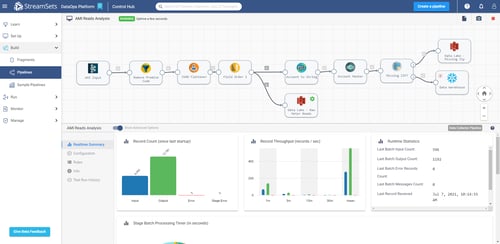
ADDING A CONTROL LAYER
We implemented StreamSets Control Hub, a SaaS based platform, to connect our multiple Data Collector Engines and Transformer Engines. The Control Hub acted as a one stop shop to see the health of the overall end to end process by looking at the overall topology of the use case as opposed to individual pipelines.
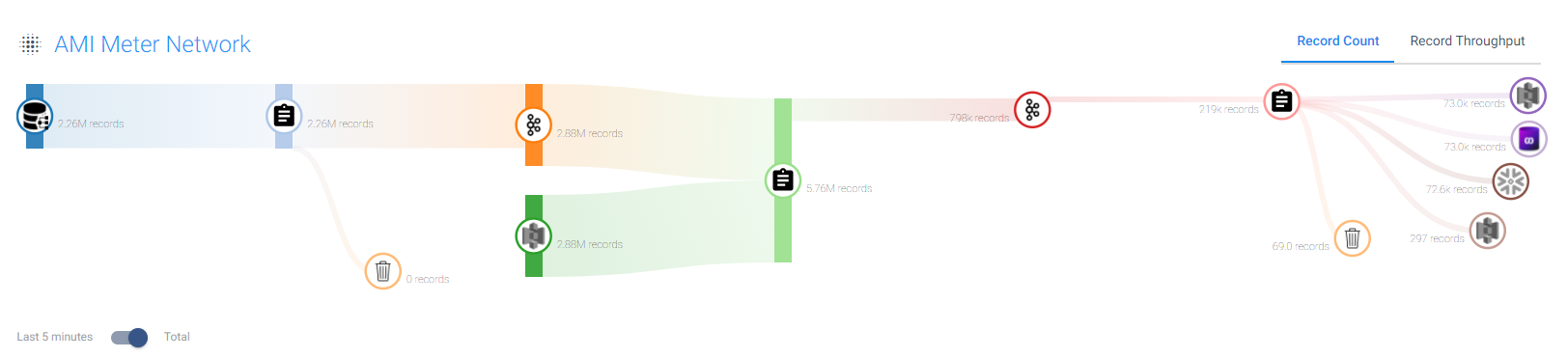
For the current use case, SME built a topology that includes all of the connected pipelines, the flow of data, and the record count. From the Control Hub, we created pipeline fragments from the existing pipelines, which are pieces of a pipeline that the utility’s data engineer can utilize in other use cases. For example, as opposed to having the data engineer repeatedly create three different pieces to get data from the Postgres database to Kafka, it can be saved as a fragment and reused throughout the rest of the environments.
The Control Hub also acted as a scheduler and monitor for the streaming and batch pipelines and detailed which jobs were continuously running, which jobs are in error state, and unhealthy engine reports.
The Control Hub is where the utility could see inside of their DataOps environment with full transparency including all of the data movements and data processes.
“I call it the top-down approach. Like if you’re on the road, you can only see the road that you’re on, but if you go up into a helicopter and look down, you can see all the roads, what’s flowing, and what’s jammed up.” George Barrett, Solutions Engineer
BUSINESS IMPACTS
- The time between data collection and delivery to the data lakes and warehouses was reduced from overnight to near real-time.
- The streaming architecture reduced the strain on the source systems which drastically reduced the chances for crashes or failures.
- Performing data transformations to ensure your data is delivered ready to go, all within StreamSets as opposed to writing manual code.
- Increased monitoring capabilities resulted in cost savings because the data became more resilient. No more issues with delivering the data at the wrong time or delivering bad data, meaning less downtime.
To learn more about SME Solutions please visit their website: https://smesgroup.com/