In this post, we will explore how to bulk ingest and process change data capture (CDC) information from Oracle 19c database using the enhanced Oracle CDC Client origin into Databricks Delta Lake in StreamSets Data Collector, a fast data ingestion engine. You’ll also learn one way to automate and orchestrate the two jobs using StreamSets Control Hub REST APIs.
Introduction
With Databricks Runtime version 6.3 or later, you can use the Databricks Delta Lake destination in Data Collector version 3.16 and in future releases for the following bulk ingest and CDC use cases.
- Bulk Ingest — In this case the Databricks Delta Lake destination uses the COPY command to load data into Delta Lake tables.
- Change Data Capture — When processing CDC data, the Databricks Delta Lake destination uses the MERGE command to load data into Delta Lake tables.
Prerequisites
- Install the Databricks stage library
- Prepare the Databricks cluster
- Access to Oracle 19 database
- Enable backup
- If running on AWS RDS, execute these 2 procedures from your Oracle client:
begin rdsadmin.rdsadmin_util.alter_supplemental_logging( p_action => 'ADD', p_type => 'ALL'); end;
begin rdsadmin.rdsadmin_util.set_configuration( name => 'archivelog retention hours', value => '24'); end;
Note: For other versions of Oracle and installations, refer to these prerequisites.
Ok, let’s get after it!
Oracle 19c Bulk Ingest: Oracle to Databricks Delta Lake
Let’s consider an Oracle data warehouse that contains database tables related to retail — for example, transactions recorded in master-detail tables orders and order items respectively, products, customers, (product) categories and departments.
Job Overview
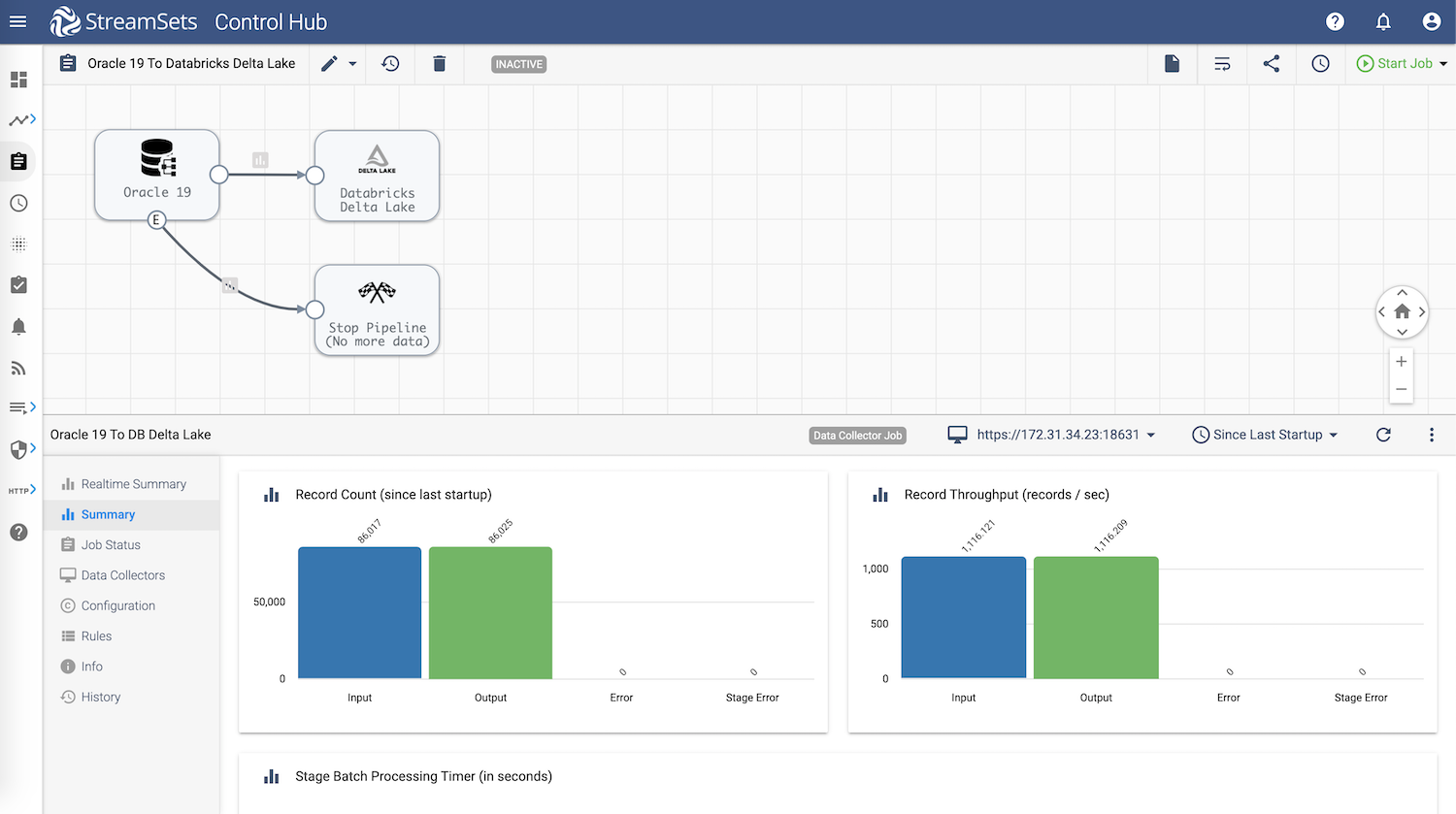
Origin
JDBC Multitable Consumer origin to connect to Oracle which will enable us to load multiple tables.
Key configuration for this setup:
- Set Tables tab >> Table Name Pattern to %
- This wildcard will select all tables for the Oracle 19c bulk ingest process
- Set Advanced tab >> Create JDBC Header Attributes to true
- This will ensure that record header attributes like source table name etc. are created
For other configuration details such as JDBC connection string, number of threads, connection pools, timeouts, etc. please refer to the configuration section.

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
Destination
Databricks Delta Lake destination will write data that’s being ingested from Oracle. In this case the Databricks Delta Lake destination uses the COPY command to load data into Databricks Delta Lake tables.
Key configuration on Databricks Delta Lake tab for this setup:
- Set JDBC URL
- In Databricks, you can locate the JDBC URL for your cluster on the JDBC/ODBC tab in the cluster configuration details.
- Set Table Name to ${record:attribute(‘jdbc.tables’)}
- This will dynamically set the table name from the record header attribute generated by the JDBC Multitable Consumer origin.
- Set Auto Create Table to true
- This will automatically create the respective Delta Lake table if it doesn’t already exist.
- Set Directory for Table Location to the path on Databricks File System (DBFS) where the tables need to be created
For other configuration details such as staging and defaults for missing fields please refer to the configuration section.
Pipeline Finisher
Another stage included in this pipeline is Pipeline Finisher Executor. This will automatically stop the pipeline once the data from all tables is read and written to Databricks Delta Lake destination.
Key configuration on General tab for this setup:
- Set Preconditions to ${record:eventType()==”no-more-data”}
- This event will be generated by JDBC Multitable Consumer origin.
- Set On Record Error to Discard
- This is just to reduce “noise” when error records are generated for events produced by the origin are of type other than “no-more-data”.
Change Data Capture: Oracle CDC to Databricks Delta Lake
Change Data Capture is a design pattern to determine, track, capture, and deliver changes made to enterprise data sources–typically relational databases like Oracle, SQLServer, DB2, MySQL, PostgreSQL, etc. This pattern is critical because when these changes occur, actions must be taken using the changed data in data warehouses for downstream analysis.
Once the data has been offloaded from Oracle to Databricks Delta Lake, the next step is to keep the two in sync. Let’s see how.
Job Overview
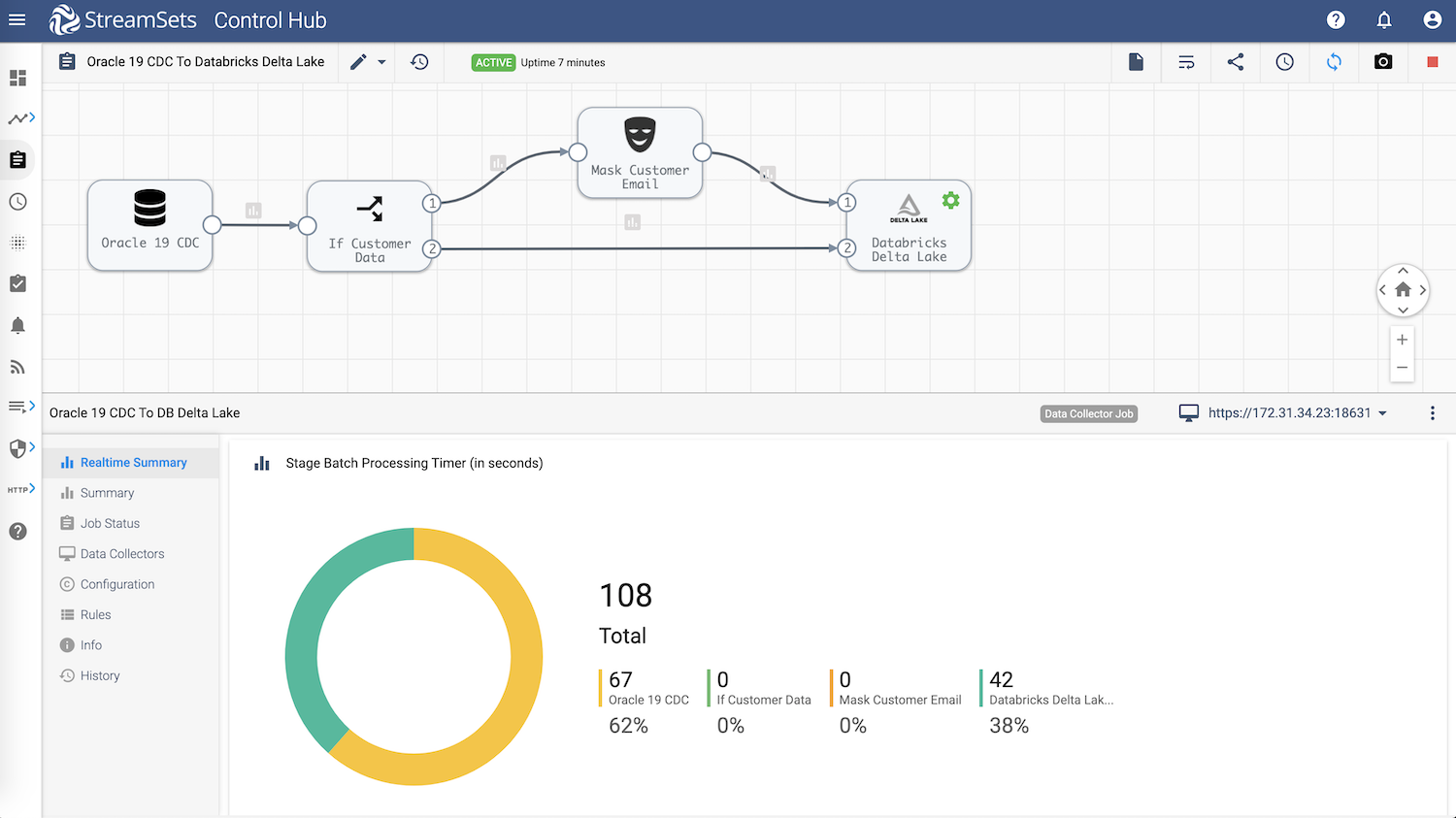
Origin
Oracle CDC Client origin will enable us to capture CRUD operations across various tables in the same Oracle data warehouse so that the Databricks Delta Lake can be kept in sync.
Key configuration Oracle CDC tab for this setup:
- Set Table Name Pattern to %
- This wildcard will capture changes across all tables.
- Set Dictionary Source to Online Catalog
For other configuration details such as JDBC connection string, operations, LogMiner session window, transaction length, System Change Number, etc., please refer to the configuration section.
Stream Selector
This will conditionally route a subset of records based on user-defined conditions. For instance, in our case, we’d like to protect customer email addresses from being reported (in plaintext) in Databricks Delta Lake.
Key configuration for this setup:
- On Conditions tab, set condition 1 to ${record:attribute(‘oracle.cdc.table’) == ‘CUSTOMERS’}
- This will route records being read from ‘CUSTOMERS‘ table through Field Masker; all other records will flow directly into Databricks Delta Lake.
Field Masker
In StreamSets DataOps Platform, it is really easy to apply any number of transformations while the data is in motion. A good example in this case is using Field Masker to “mask” a customer’s email address before sending it over to Databricks Delta Lake.
Key configuration on Mask tab for this setup:
- Set Fields to Mask to /CUSTOMER_EMAIL
- Set Mask Type to Custom
- Set Custom Mask to XXXXXX
Destination
Databricks Delta Lake destination to write CDC data that’s being captured from Oracle. In this case the Databricks Delta Lake destination uses the MERGE command to load data into Databricks Delta Lake tables. StreamSets supports many other destinations including Snowflake.
Key configuration on Databricks Delta Lake tab for this setup:
- Set JDBC URL
- In Databricks, you can locate the JDBC URL for your cluster on the JDBC/ODBC tab in the cluster configuration details.
- Set Table Name to ${record:attribute(‘oracle.cdc.table’)}
- This will dynamically set the table name from the record header attribute generated by the Oracle CDC Client origin.
- Set Auto Create Table to true
- This will automatically create the respective Delta Lake table if it doesn’t already exist.
- Set Directory for Table Location to the path on Databricks File System (DBFS) where the tables need to be created
Key configuration on Data tab for this setup:
- Set Merge CDC Data to true
- Set Table and Key Columns for all the tables you’d like to capture and sync changes. For example, in my case:
- Table: CUSTOMERS; Key Columns: CUSTOMER_ID
- Table: ORDERS; Key Columns: ORDER_ID
- Table: ORDER_ITEMS; Key Columns: ORDER_ITEM_ID, ORDER_ITEM_ORDER_ID
- Table: PRODUCTS; Key Columns: PRODUCT_ID
For other configuration details such as staging, defaults for missing fields, etc. please refer to the configuration section.
Automation and Orchestration
Now that you’ve seen how to set up the Oracle 19c bulk ingest and CDC jobs from Oracle to Databricks Delta Lake, let’s take a look at one way of orchestrating the two jobs such that when the bulk ingest job finishes, the CDC job starts up automatically.
To accomplish this, I have defined three pipeline parameters — CDC_JOB_ID, SCH_USERNAME and SCH_PASSWORD — and leveraged Stop Event in the Oracle 19c bulk ingest pipeline. Note: The values for pipeline parameters will be specific to your environment.
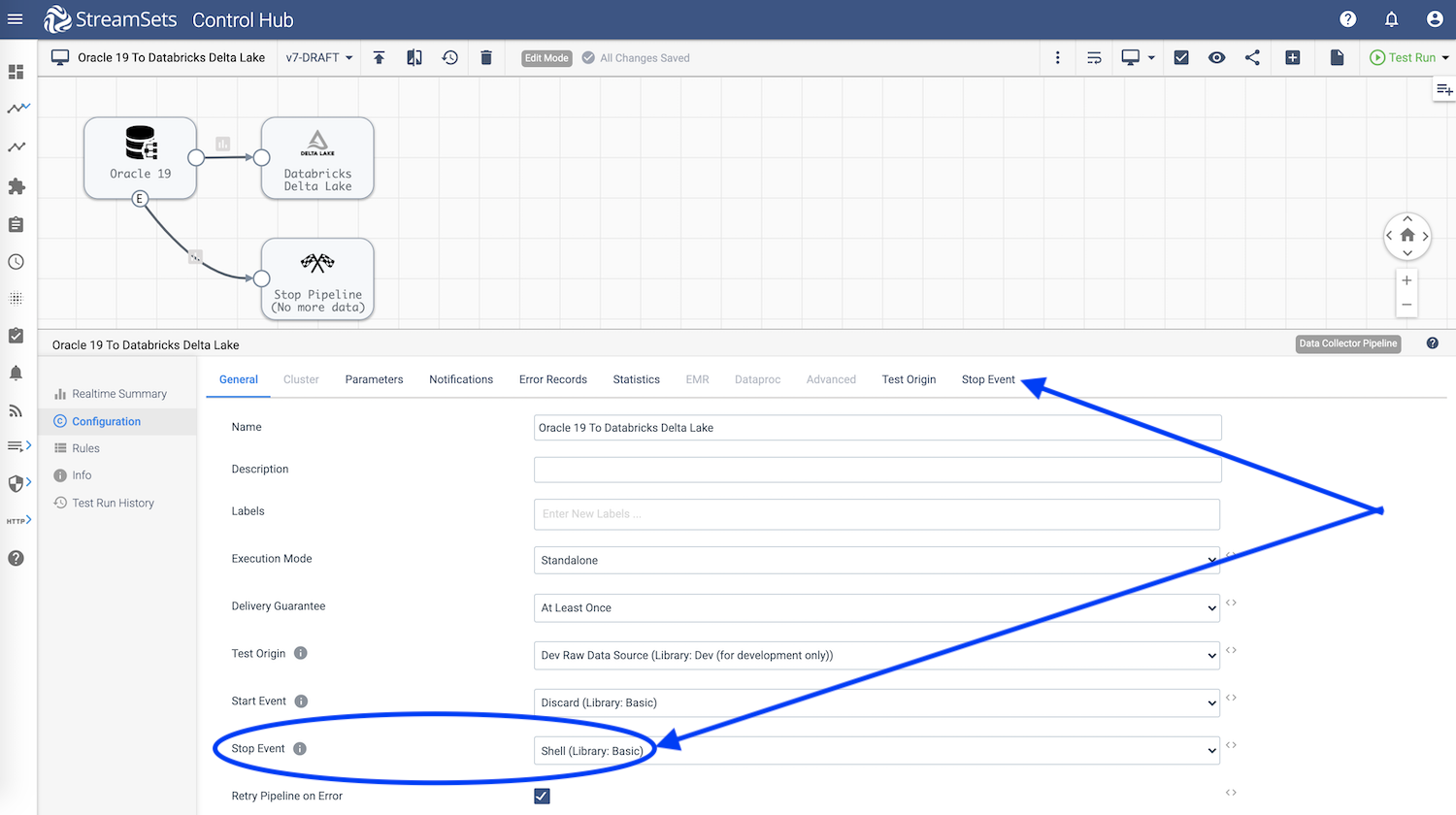
Stop Event
On this tab, I’ve assigned the 3 pipeline parameter values to three environment variables respectively so that those values can be accessed in the Shell script. See below.
#!/bin/bash echo "==== Get SCH Auth Token ====" SCH_TOKEN=$(curl -s -X POST -d "{\"userName\":\"$SCH_USERNAME\", \"password\": \"$SCH_PASSWORD\"}" https://trailer.streamsetscloud.com/security/public-rest/v1/authentication/login -H "Content-Type:application/json" -H "X-Requested-By:SDC" -c - | grep SSO | grep -o '\S*$') echo "==== Reset Oracle CDC job ====" curl -H "X-Requested-By: SDC" -H "Content-Type: application/json" -H "X-SS-User-Auth-Token:$SCH_TOKEN" -X POST "https://trailer.streamsetscloud.com/jobrunner/rest/v1/job/$CDC_JOB_ID/resetOffset" > reset.txt echo "==== Start Oracle CDC job ====" curl -H "X-Requested-By: SDC" -H "Content-Type: application/json" -H "X-SS-User-Auth-Token:$SCH_TOKEN" -X POST "https://trailer.streamsetscloud.com/jobrunner/rest/v1/job/$CDC_JOB_ID/start" > start.txt exit 0
In the script:
- Authenticate
- Invoke SCH REST API (/security/public-rest/v1/authentication/login) to authenticate SCH_USERNAME and SCH_PASSWORD and store auth token in SCH_TOKEN environment variable.
- Reset CDC Job
- Use SCH_TOKEN and invoke SCH REST API (jobrunner/rest/v1/job/$CDC_JOB_ID/resetOffset) to reset the CDC job.
- Note: this step is optional and depends on whether the job was ever run before, the current status of it, as well as on your particular use case.
- Start CDC Job
- Use SCH_TOKEN and invoke SCH REST API (jobrunner/rest/v1/job/$CDC_JOB_ID/start) to start the CDC job.
- Note: it is assumed that the job is currently inactive.
IMP: The above orchestration is intentionally kept to a minimum in the interest of the scope of this blog and does not account for things like monitoring and error handling in case the script fails for whatever reason, the credentials and/or job id supplied are incorrect, or the job fails to start, etc. It is assumed that such things are handled manually by inspecting the jobs on Jobs dashboard in StreamSets Control Hub (SCH). Having said that, as long as the SCH credentials and CDC job id provided are correct and the CDC job is in an inactive state, the above setup does work as expected :)
In one of my upcoming blogs, I will illustrate a better, more “controlled” approach to orchestration between jobs using a set of newly released orchestrator stages. Stay tuned!
Summary | Oracle 19c Bulk Ingest
Learn more about StreamSets For Databricks. To take advantage of these and additional features and enhancements, get started today by deploying StreamSets in your favorite cloud to design, deploy, and operate smart data pipelines in minutes. For any other questions and inquiries, please contact us.