Data Integration: Tools,
Techniques, and Key Concepts
How data integration has evolved from ETL to data engineering and why you need to know
Data integration is a complex topic that’s evolved in leaps and bounds over its short, 30-year history. So if you want to understand modern tools, techniques, and key concepts of data integration, first, we need to review the basics.
What Is Data Integration?
Data integration combines various types and formats of data from various sources into a single dataset that can be used to run applications or support business intelligence and analytics. Working from this single data-set set allows businesses to make better decisions, aligns departments to work better together, and drives better customer experience.
Data Integration Techniques: How Do They Work?
Moving data from one system to another requires a data pipeline that understands the structure and meaning of the data as well as defines the path it will take through the technical systems. The specific techniques used for data integration depend on:
- The volume, velocity, and variety of the data to be integrated.
- The characteristics of the sources and destinations of data.
- The time and resources available.
- The minimum performance standards.
A relatively simple and common process involved in data integration is data ingestion, where data from one system is regularly ingested into another. Data integration also includes cleansing, sorting, and enriching data to make it ready for use.
Sometimes this cleansing happens before the data is stored by a process called ETL (extract, transform, load). Other times it makes more sense to store the data first, then prepare it for use, which is a process known as ELT (extract, load, transform). And in yet other cases, data is transformed and conformed where it’s stored without moving it.
The steps, in part, depend on the type and volume of data, how the data will be stored, and how it will be used, among other things. The most common techniques for data integration are:
-
- Manual Data Integration: Engineers manually write code that moves and manipulates data based on business needs.
- Application-Based Data Integration: Applications are directly linked and move and transform data based on event triggers.
- Common Data Storage: Data is extracted from sources and stored in a data lake or data warehouse providing a single source.
- Data Virtualization: Data from different sources is combined in a virtual database where end users can access it.
- Middleware Data Integration: Software is used to transfer information between systems.
Key Concepts of Data Integration
To grasp the most important concepts of data integration, rather than list and explain them, let’s look back on how data integration has developed. Within the story of data integration’s evolution, the key concepts will become self-evident.
The Early Days of Data Integration
In the early 1990s, when companies began adopting data warehouses to collect data from multiple systems to fuel analysis, there were no smartphones or ecommerce. Salesforce and Software as a Service as a category did not yet exist. And Amazon had not sold a single book, much less on-demand computing.
A set of tools for integrating data among on-premises applications, SaaS apps, databases, and data warehouses had begun to emerge. Back then:
- Data came from business applications and operational databases in a structured format that could be mapped to the structure required for analysis.
- Data arrived and was processed in batches, creating snapshots of the business in time and stored in data warehouses or data marts.
- Data was used for financial reporting, sales dashboards, supply chain analytics, and other essential functions of the enterprise.
Data integration was primarily the responsibility of ETL developers, who used hand coding or specialized software to create ETL mappings and jobs. They developed specialized skills related to the source and target systems they integrated to build ETL mappings that would work correctly with the intricacies of those systems.
Data integration was owned and governed by enterprise IT with control of the hardware and software used to collect, store, and analyze data. They focused on performance, security, and cost of the monolithic data management systems that powered business growth and innovation. Change occurred carefully, over years, according to explicit change management processes.
The Evolution of Data
The world of data looks very different today. Let’s look at what’s changed:
- More than 3 billion people now have smartphones, and over 4 billion use the Internet.
- Ecommerce accounted for 20% of retail purchases (minus auto and gas sales) in the U.S. in 2020.
- The SaaS market doubled from 2014 to 2020, led by Salesforce.
- The public cloud computing market was estimated at around $257.5 billion by 2020.
The explosion of data, data sources (IoT, APIs, cloud applications, on-premise databases, and more), and data structures combined with radical innovation in infrastructure services, compute power, analytic tools, and machine learning have transformed enterprise data integration.
- Real-time decision-making and real-time services require continuous data that is transformed in flight.
- DevOps and agile software development practices have spread throughout the organization, increasing the demand for always-on, self-service data.
- The move from on-premises to the cloud for applications and computing services requires cloud data integration, i.e., data integration beyond the walled garden of the corporate data center.
Suddenly, the full data integration lifecycle matters as much as the initial implementation. Data integration has to support continuous integration of data from different sources, continuous data delivery, and continuous innovation, which takes automation. Data integration is just one part of an agile DataOps practice, and ETL mappings or jobs are considered one type of the many different “data pipeline” patterns needed to enable it.
The focus is not just on the “how” of implementation, but on “what” the business needs.
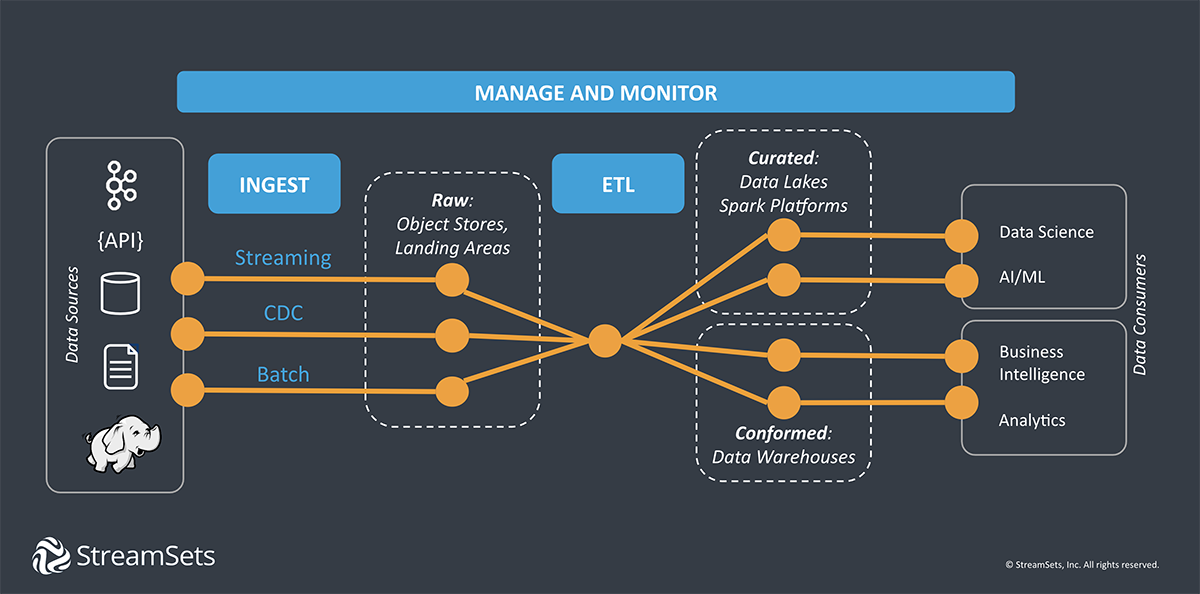
New Roles and New Responsibilities
As data integration has evolved into a more sophisticated business imperative, responsibility for data pipelines requires more than understanding how to build what the business requests. This has led to growth of new roles and responsibilities in managing data integration.
The Shift to Data Engineering and Data Science
Data engineers have become key members of the data platform team. They are technical professionals who understand why business analysts and data scientists need data, and how to build data pipelines to deliver the right data, in the right format, to the right place. The best data engineers are able tocan anticipate the needs of the business, track the rise of new technologies, and maintain a complex and evolving data infrastructure.
A skilled data engineer with the right tools can support 10s of ETL developers who, in turn, enable 100s of data scientists. As a result, the demand for data engineers is up 50% according to a 2020 report from Datanami, making it one of the fastest growing jobs in the United States.
Data Management from the C-Suite
The importance of data to the organization is increasingly reflected in the C-suite with Chief Data Officers and Chief Information Officers leading enterprise-wide digital transformation and platform standardization initiatives. Their involvement often focuses on compliance, cost containment, and reliability goals.
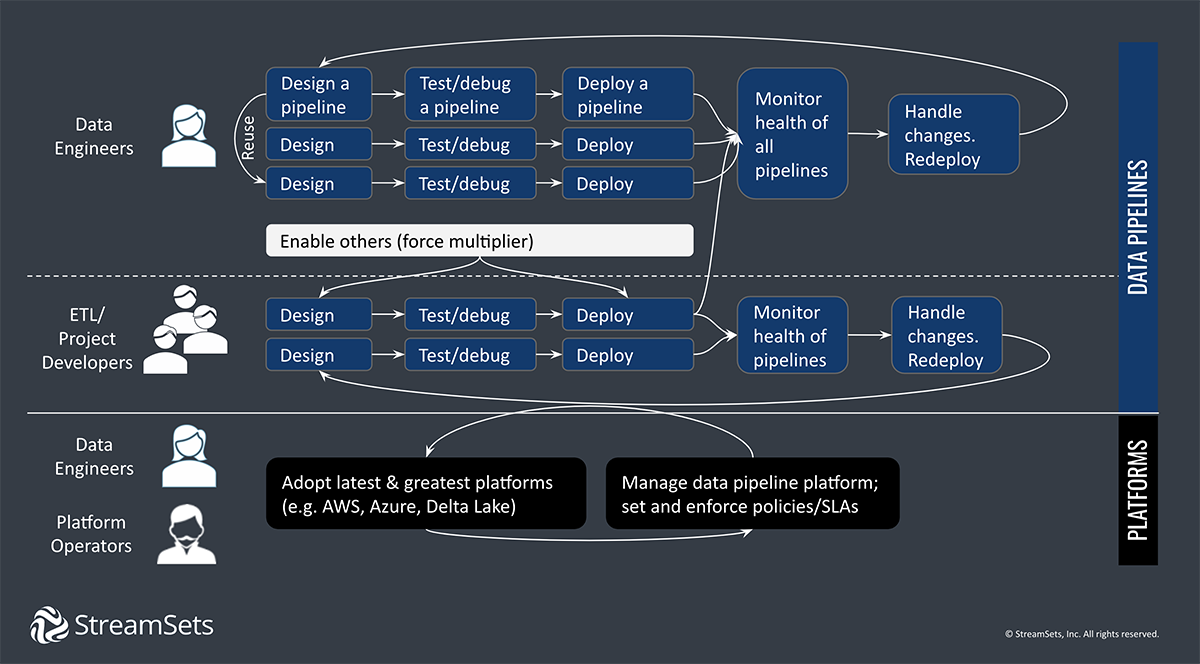
Data Integration Tools
As data integration has become increasingly complex and multi-faceted, so have the tools that facilitate it. In this section, we’ll review the basics of data integration tools and how to choose the best one for your organization.
What are data integration tools?
Data Integration tools are software-based tools that ingest, consolidate, transform, and move data from source(s) to destination, performing mappings, transformations, and data cleansing along the way. Ultimately, they integrate the data into a ‘single source of truth’ destination, such as a data lake or data warehouse. This allows consistent, reliable data for use in analytics and business intelligence.
How do I identify good data integration tools?
Along with the explosion of data, source systems, and destinations, the number of data integration solutions available has multiplied in recent years – as has the innovation in those technologies. The on-premises ETL (extract, transform, and load) solutions of yesteryear can’t handle today’s multiple data sources, complex transformations, hybrid and multi-cloud environments, and real-time data needs.
Luckily, there’s no shortage of new data integration platforms out there. Finding them is as easy as checking a site like G2 Crowd or Gartner Peer Insights for user reviews.
Data Integration Tool Considerations for the Age of Data Engineering
When choosing a tool for data integration, there are a few important considerations to take into account:
- What type of data will be in your data pipeline?
- How will that data be processed?
- Where will the data come from and go to?
Type of Data: Structured, Unstructured, and Semi-Structured
Let’s start with the type of data you need to have integrated for your analytics, machine learning, and AI workloads.
Structured data is organized in a spreadsheet or a relational database like SQL. All the data has a row and a column that defines what it means. Mapping the “company” column in one database to the “companyname” column in another is pretty straightforward. Structured data is often transformed then consolidated, stored, and regularly refreshed in a data warehouse or data mart for analytics and reporting.
Unstructured data lacks a row/column type of organizational structure to help you sort through it. For example, a stream of Twitter comments may contain your brand name, but Twitter does not define your brand name as the “company name.” There is no way to logically map the Twitter stream contents to a database. Unstructured data is generally integrated within a data warehouse or data lake using an ELT or ETL process.
Semi-structured data has some logic and hierarchy, but not as much as a relational database. For example, an electronic medical record may use an industry-standard XML format with a structure to indicate patient name, diagnosis, etc., but the information is not in a row and column setup.
Your business might use all 3 types of data in a variety of ways, even combining them together (which can have its own challenges). For data integration to be successful, your data team will need to be conversant with what type of data is needed, when, and how to process it.
Type of Processing: Batch, Micro-batch, and Streaming
Next, you will need to consider how quickly your data needs to be processed. Can your analytics systems and applications wait for the data? Or is it needed immediately?
Batch data processing allows you to do a one-time data migration or to run your data transformations periodically on a defined dataset. ETL developers use bulk processing to gather and transform datasets to be queried by analytics systems. For example, batch processing a restaurant’s orders at night works well to support weekly, monthly, or quarterly financial and HR reporting.
Micro-batch processing allows smaller datasets to be processed more frequently. This approach allows data to be used for immediate feedback and automated responses without the always-on of streaming data. A truck carrying a shipment of potatoes to the restaurant might have a sensor that sends a batch of GPS data to the data lake every 5 minutes. If the truck breaks down, the restaurant would receive an alert within minutes, but not at the moment the truck stopped.
Stream processing is the always-on flow of data from source to destination. Examples include customer interactions, sensor data, web clicks, voice-activated assistants, camera feeds, and more. If our restaurant started accepting online orders, a recommendation engine might use event stream processing to suggest fries to go with that shake. Delivering the recommendation a day later is simply too late.
Sources & Destinations: On-Premises, Cloud, Multi-Cloud, and Hybrid Architectures
The availability of on-demand processing and compute power in the cloud has shifted data storage (and, with it, data integration) and investment from on-premises data centers to cloud service providers.
On-premises refers to the data centers built and maintained on-site. For large, global organizations, on-premises may span national and geographic boundaries and represent significant investments in hardware, software, people, and even buildings.
Cloud architectures allow companies to get started quickly, pay for what they use, and offload the maintenance burden of data centers to a vendor. Cloud infrastructure providers, Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP) and others, enable companies to run workloads on “rented” infrastructure without having to build or maintain it.
From Data Integration to Data Engineering
As data types, processing types, and infrastructures expand, the “how” of data integration has become almost unknowable.
The days of the boardroom IT infrastructure map are history. It is too complex and too varied for a single person or group to map and track. Every change made to data structure, data semantics, or data infrastructure is a potential point of failure or opportunity in such a complex, interconnected, unknowable system.
This is why the modern data platform designed for data engineers depends on smart data pipelines that abstract away the “how” of implementation so you can focus on the what, who, and where of the data. The StreamSets data engineering platform is dedicated to building the smart data pipelines needed to power DataOps across hybrid and multi-cloud architectures. You can build your first data pipeline with StreamSets Data Collector for free.
Frequently Asked Questions
What are data integration techniques?
Data integration techniques are methods used to combine data from multiple sources, in multiple formats into a single, unified view. Common data integration techniques include:
- Extract, Transform, Load (ETL)
- Extract, Load, Transform (ELT)
- Change Data Capture (CDC)
- Enterprise Application Integration (EAI)
- Data Virtualization
- Master Data Management (MDM)
These various data integration techniques can be combined based on the needs of an organization.
What is the main goal of data integration?
In terms of data management, the main goal of data integration is to combine different sources of data into one, clean set of data that analysts, applications, data scientists, and other people or systems can easily access and use to accomplish their tasks, like making decisions or triggering workflows.
For the business, the main goal of data integration is to generate value and improve decision-making.
What are the challenges of data integration?
The challenges of data integration include:
- Data being in many different places and many different formats.
- Inconsistent definitions of data
- Continuously ensuring data security, quality, privacy, and compliance
- Technical complexity of data engineering requires specialized staff and tools
- Costs of data integration can quickly escalate
What makes data integration even more challenging is that all these listed items are constantly evolving. New data security laws, new sources and use cases of data, and changing business priorities make successful data integration a moving target.