How to Create a Microservice Data Pipeline with StreamSets DataOps Platform
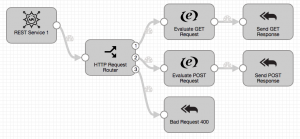 A microservice data pipeline is a lightweight component that implements a relatively small component of a larger system – for example, providing access to user data. A microservice architecture comprises a set of independent microservices, often implemented as RESTful web services communicating via JSON over HTTP, that together implement a system’s functionality, rather than a single monolithic application. Think of an e-commerce web site: we might have separate microservices for searching for inventory, managing the shopping cart, and recommending items based on the shopping cart’s content. Compared to monolithic applications, the microservice approach promotes fine-grained modularity, allowing agile implementation of components by independent teams, which may even be using different technologies. Now, one of those technologies can be StreamSets Data Collector Englne. Data Collector 3.4.0, released earlier this week, introduces microservice data pipelines, with a new REST Service origin and Send Response to Origin destination allowing you to implement RESTful web services completely within the Data Collector Engine.
A microservice data pipeline is a lightweight component that implements a relatively small component of a larger system – for example, providing access to user data. A microservice architecture comprises a set of independent microservices, often implemented as RESTful web services communicating via JSON over HTTP, that together implement a system’s functionality, rather than a single monolithic application. Think of an e-commerce web site: we might have separate microservices for searching for inventory, managing the shopping cart, and recommending items based on the shopping cart’s content. Compared to monolithic applications, the microservice approach promotes fine-grained modularity, allowing agile implementation of components by independent teams, which may even be using different technologies. Now, one of those technologies can be StreamSets Data Collector Englne. Data Collector 3.4.0, released earlier this week, introduces microservice data pipelines, with a new REST Service origin and Send Response to Origin destination allowing you to implement RESTful web services completely within the Data Collector Engine.
The REST Service origin accepts requests via HTTP, parsing incoming data into an in-memory record, including metadata such as the query string and HTTP request headers. As in any other Data Collector Engine pipeline, processors such as Field Flattener, JDBC Lookup, or any of the script Evaluators (take your pick of Groovy, JavaScript or Jython) can enrich, filter and transform the data, handing the resulting record off to the Send Response to Origin destination to be returned via HTTP as a JSON-formatted response to the original request.
Although any existing processors or destinations can be included in a microservice data pipeline, this initial implementation is particularly well suited to integrations via JDBC. The JDBC Lookup and JDBC Tee processors can interact with a wide variety of data stores, and both return data that can enrich the record on its way through the pipeline. In fact, you can use the JDBC Lookup and JDBC Tee processors to implement create, read, update and delete operations, and a new tutorial guides you through the process of Creating a CRUD Microservice Pipeline. Here’s a short video that shows the resulting pipeline and how it responds to REST requests:
Another application of microservice pipelines is as a RESTful web service proxy. A microservice data pipeline can receive a request, perform lookups, rename fields, query a different service via the HTTP Client processor, and similarly process the response before passing it back to the REST client.
Since Data Collector pipelines can send data to multiple destinations, you can send data almost anywhere, as well as returning a response to a REST client. Note, however, at present, it is not possible to define an ordering between Send Response to Origin and another destination – this is why processors such as JDBC Tee and HTTP Client are so useful in microservice pipelines. In the future, microservice pipelines will be able to indicate in the response that the record was successfully written to another destination.
What will you implement in a microservice data pipeline? Signup for StreamSets DataOps Platform, follow the tutorial, and get to work on your own use case!

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.