![]() Although the recent public preview of Amazon Managed Streaming for Kafka (MSK) certainly made headlines, Kinesis remains Amazon’s supported, production, real-time streaming service. In this blog post, I’ll show you how to get started using StreamSets Data Collector to build dataflow pipelines to send data to and receive data from Amazon Kinesis Data Streams.
Although the recent public preview of Amazon Managed Streaming for Kafka (MSK) certainly made headlines, Kinesis remains Amazon’s supported, production, real-time streaming service. In this blog post, I’ll show you how to get started using StreamSets Data Collector to build dataflow pipelines to send data to and receive data from Amazon Kinesis Data Streams.
Getting Started with Amazon Kinesis Data Streams
A Kinesis stream is partitioned into shards in much the same way as a Kafka topic is split into partitions. Shards provide scalability, but message order is only preserved within a shard, and not between shards. It’s important to remember this if the order in which messages arrive at consumer applications is important!
We can use the Kinesis CLI to create a stream with a specified number of shards. We’ll start with a single shard to keep things simple:
$ aws kinesis create-stream --stream-name pat-test-stream \
--shard-count 1
Note that the create-stream command returns immediately, but it takes a few seconds for the stream to be created. We use the describe-stream command to monitor progress:
$ aws kinesis describe-stream --stream-name pat-test-stream
{
"StreamDescription": {
"RetentionPeriodHours": 24,
"StreamStatus": "CREATING",
"StreamName": "pat-test-stream",
"StreamARN": "arn:aws:kinesis:us-west-2:316386816690:stream/pat-test-stream",
"Shards": []
}
}
# After a few seconds...
$ aws kinesis describe-stream --stream-name pat-test-stream
{
"StreamDescription": {
"RetentionPeriodHours": 24,
"StreamStatus": "ACTIVE",
"StreamName": "pat-test-stream",
"StreamARN": "arn:aws:kinesis:us-west-2:316386816690:stream/pat-test-stream",
"Shards": [
{
"ShardId": "shardId-000000000000",
"HashKeyRange": {
"EndingHashKey": "340282366920938463463374607431768211455",
"StartingHashKey": "0"
},
"SequenceNumberRange": {
"StartingSequenceNumber": "49592737466164404699690711438135121373532229144527503362"
}
}
]
}
}
When we use the CLI to add data to the stream, we need to specify a partition key. Records with the same partition key will be sent to the same partition. In this way, we can preserve ordering of messages relating to the same object. For example, we might use ‘account number’ as a partition key so that messages concerning the same account are ordered correctly. In our simple example, we only have a single shard, so the partition key is irrelevant for now.
$ aws kinesis put-record --stream-name pat-test-stream \
--partition-key 1 \
--data '{"a":1}'
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49592737466164404699690711439258213459954231536299016194"
}
Retrieving messages from Kinesis using the CLI is a little more involved. First, we need to get a shard iterator, specifying an iterator type:
TRIM_HORIZONto start iterating from the oldest data record in the shardLATESTto start iterating from just after the most recent record in the shardAT_SEQUENCE_NUMBERto start iterating from a specific recordAFTER_SEQUENCE_NUMBERto start iterating from just after a specific recordAT_TIMESTAMPto start iterating from a given point in time
Let’s get a shard iterator with TRIM_HORIZON, so we can get all the data in the shard:
$ aws kinesis get-shard-iterator --shard-id shardId-000000000000 \
--shard-iterator-type TRIM_HORIZON \
--stream-name pat-test-stream
{
"ShardIterator": "AAAAAAAAAAFiuV2h51uGfRcr97suGhG/JjyI3XLayOtndZxsYcHi19pUGlauq+bvKwLA9q+uQDPVCgmBd5xDmFeTgmtpgUkr6T92IvG91tMDR674dFY+zCGIrePikMjIKwu+HQa60bKOL01kHLej49ZWoH8wltjJoENilQ+czzVxWMQtjy8EfJxQNuPx6bNIzYFaAvQ9gqxW++/nHUdeFF7JbR4HncZg"
}
Now we can use get-records with the shard iterator to actually retrieve some records:
$ aws kinesis get-records --shard-iterator "AAAAAAAAAAFiuV2h51uGfRcr97suGhG/JjyI3XLayOtndZxsYcHi19pUGlauq+bvKwLA9q+uQDPVCgmBd5xDmFeTgmtpgUkr6T92IvG91tMDR674dFY+zCGIrePikMjIKwu+HQa60bKOL01kHLej49ZWoH8wltjJoENilQ+czzVxWMQtjy8EfJxQNuPx6bNIzYFaAvQ9gqxW++/nHUdeFF7JbR4HncZg"
{
"Records": [
{
"Data": "eyJhIjoxfQ==",
"PartitionKey": "1",
"ApproximateArrivalTimestamp": 1549500408.399,
"SequenceNumber": "49592737466164404699690711439258213459954231536299016194"
}
],
"NextShardIterator": "AAAAAAAAAAGgKxdoh4yt3xfM0QAoOk5YJwPACebS6C7l+rCsvAdHsNLLU/drv2U94VRT640cT0klE7Kv46sUDz7VFFMsIFaHteB8tQTxxE110y/nkPdIq/zG//WjBwcJXTKirlZrJN0ropQDjVOAgXzshDsMi2ojkJdeGPJ69Hl+rH6bPbhSSPpJJbyMjP3c4icMFSBin1ycZzpteAn3bdhEUtYIlFh6",
"MillisBehindLatest": 0
}
Notice that the data is encoded. You can send any sort of data to Kinesis, text or binary, so the CLI base64-encodes the data so that it is shown in a legible format. We can base64-decode the data using openssl:
$ echo "eyJhIjoxfQ==" | openssl base64 -d -A
{"a":1}
The Kinesis CLI is a thin wrapper over the underlying API, and there is no single command to just stream messages from a shard. We can use a bit of bash-scripting and the excellent jq JSON processor to build what we need:
$ shard_iterator=$(aws kinesis get-shard-iterator --shard-id shardId-000000000000 \
--shard-iterator-type TRIM_HORIZON \
--stream-name pat-test-stream |
jq -r .ShardIterator)
$ while true; do
response=$(aws kinesis get-records --shard-iterator ${shard_iterator})
echo ${response} | \
jq -r '.Records[]|[.Data] | @tsv' |
while IFS=$'\t' read -r data; do
echo $data | \
openssl base64 -d -A | \
jq .
done
shard_iterator=$(echo ${response} | jq -r .NextShardIterator)
sleep 1
done
{
"a": 1
}
If we send messages from a second terminal window, we’ll see them arriving in the first:
$ aws kinesis put-record --stream-name pat-test-stream \
--partition-key 1 \
--data '{"a":2}'
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49592737466164404699690711440392185878752788680387067906"
}
$ aws kinesis put-record --stream-name pat-test-stream \
--partition-key 1 \
--data '{"a":3}'
{
"ShardId": "shardId-000000000000",
"SequenceNumber": "49592737466164404699690711440393394804572404134195494914"
}
...
{
"a": 2
}
{
"a": 3
}
Now we can send and receive messages from the command line, let’s build our first dataflow pipeline with Data Collector and Kinesis!
Sending Data to Kinesis with StreamSets Data Collector
The basic Data Collector tutorial provides a great starting point to generate some realistic messages. I simply replaced the Local FS destination in the tutorial with the Kinesis Producer destination:
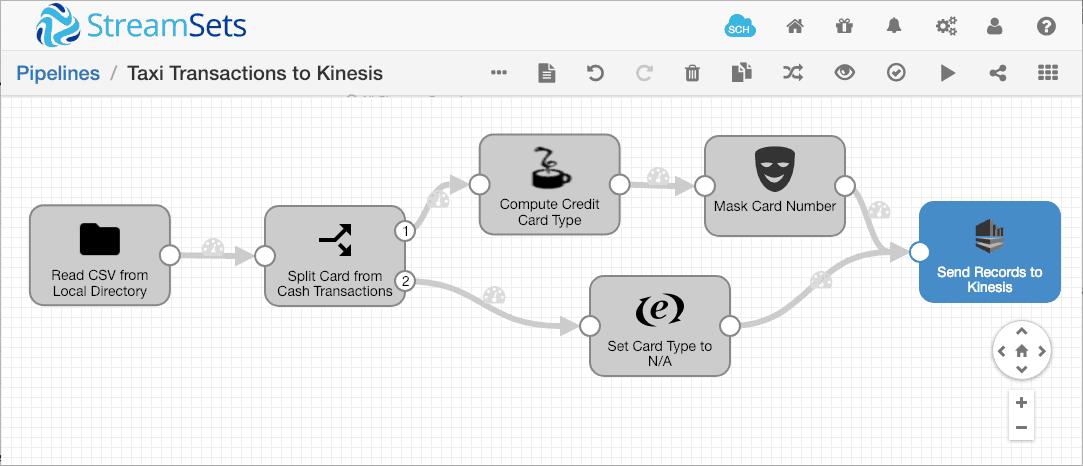
I configured the destination to send data to taxi-stream, and to use the credit card type (Mastercard, Visa, etc) as the partitioning key. This allows the pipeline to scale across multiple shards, but keeps transactions for each credit card network in the original order:
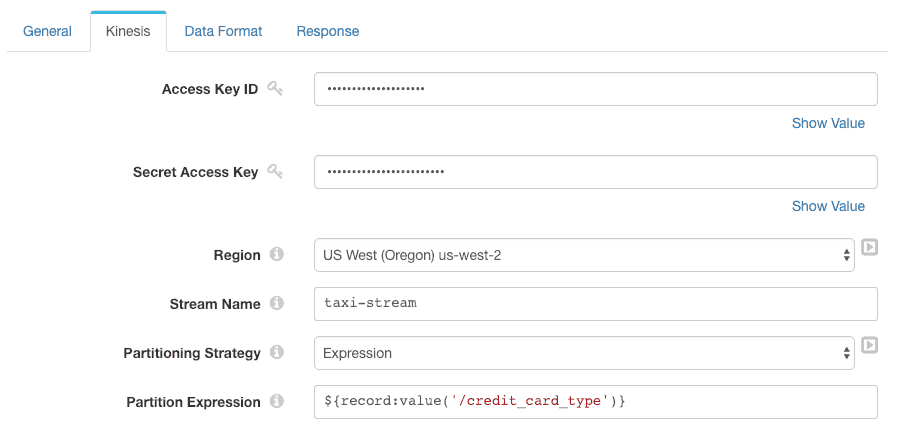
Outgoing records are formatted as JSON:

We’ll create taxi-stream with three partitions, so we can see the effect of the partitioning strategy:
$ aws kinesis create-stream --stream-name taxi-stream --shard-count 3
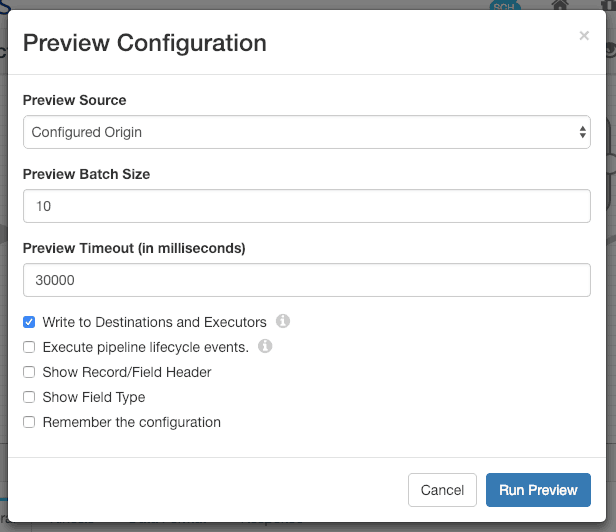
Once the stream is active, we’ll write a few records. I used Data Preview, with a ‘Preview Batch Size’ of 10 and ‘Write to Destinations and Executors’ enabled to send 10 records to Kinesis:
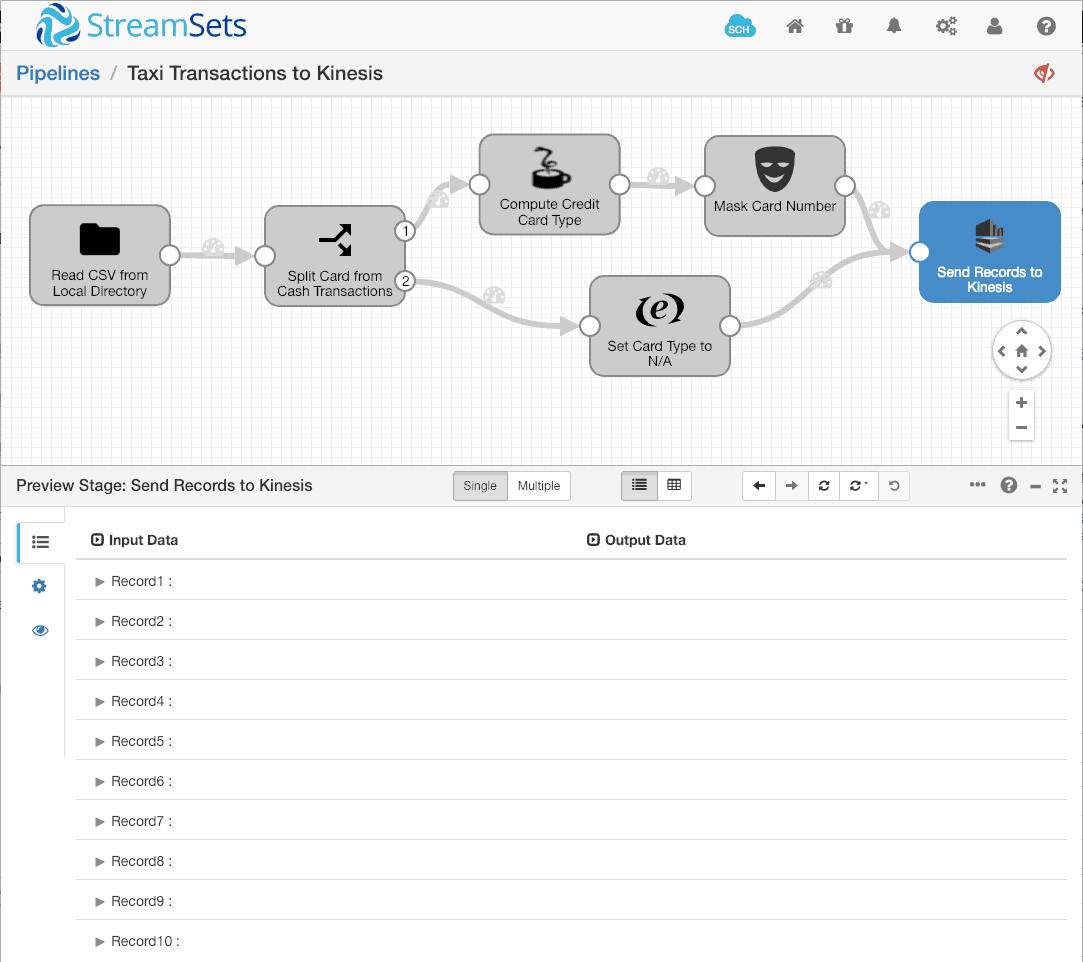
We can see the 10 records in the preview user interface:
Now we can read the records from Kinesis using our CLI script to verify that the data was correctly sent. I’ll abbreviate the records for clarity:
$ shard_iterator=$(aws kinesis get-shard-iterator --shard-id shardId-000000000000 \
--shard-iterator-type TRIM_HORIZON \
--stream-name taxi-stream |
jq -r .ShardIterator)
$ while true; do
response=$(aws kinesis get-records --shard-iterator ${shard_iterator})
echo ${response} | \
jq -r '.Records[]|[.Data] | @tsv' |
while IFS=$'\t' read -r data; do
echo $data | \
openssl base64 -d -A | \
jq .
done
shard_iterator=$(echo ${response} | jq -r .NextShardIterator)
done
{
"medallion": "20D9ECB2CA0767CF7A01564DF2844A3E",
...
"credit_card_type": "n/a"
}
{
"medallion": "BE386D8524FCD16B3727DCF0A32D9B25",
...
"credit_card_type": "MasterCard"
}
{
"medallion": "496644932DF3932605C22C7926FF0FE0",
...
"credit_card_type": "n/a"
}
{
"medallion": "89D227B655E5C82AECF13C3F540D4CF4",
...
"credit_card_type": "n/a"
}
{
"medallion": "0BD7C8F5BA12B88E0B67BED28BEA73D8",
...
"credit_card_type": "n/a"
}
{
"medallion": "0BD7C8F5BA12B88E0B67BED28BEA73D8",
...
"credit_card_type": "n/a"
}
{
"medallion": "DFD2202EE08F7A8DC9A57B02ACB81FE2",
...
"credit_card_type": "n/a"
}
{
"medallion": "DFD2202EE08F7A8DC9A57B02ACB81FE2",
...
"credit_card_type": "n/a"
}
Wait – there are only 8 messages there, but we sent 10! Where are the other two? Remember, we’re only pulling records from a single shard, but this stream has three shards. Let’s try the second shard:
$ shard_iterator=$(aws kinesis get-shard-iterator --shard-id shardId-000000000001 \
...
{
"medallion": "F6F7D02179BE915B23EF2DB57836442D",
...
"credit_card_type": "Visa"
}
{
"medallion": "E9FF471F36A91031FE5B6D6228674089",
...
"credit_card_type": "Visa"
}
We found the missing two records. As we would expect, the third shard is empty:
$ shard_iterator=$(aws kinesis get-shard-iterator --shard-id shardId-000000000002 \ ...
You’ll notice that the records in the first shard all have credit card type n/a or Mastercard, while the second shard holds records with credit card type Visa. Records are being sent to partitions based on credit card type, as we configured, so that ordering is preserved for transactions related to a given credit card network.
Now that we’re successfully sending records to Kinesis, let’s create a consumer pipeline.
Receiving Data from Kinesis with StreamSets Data Collector
I’m going to create a dataflow pipeline to run on Amazon EC2, reading records from the Kinesis stream and writing them to MySQL on Amazon RDS. When Data Collector is running on EC2, you can configure the EC2 instance with an AWS IAM role allowing it to access Kinesis and other resources. In this case, I created an AWS IAM role with a policy allowing access to Kinesis as a consumer. There are several permissions that must be granted for a Kinesis consumer – they are listed in the Kinesis documentation. Note that you must grant permissions in DynamoDB as well as Kinesis.
Here’s a simple pipeline to run on EC2, reading messages with the Kinesis Consumer origin and writing them to MySQL with the JDBC Producer destination:
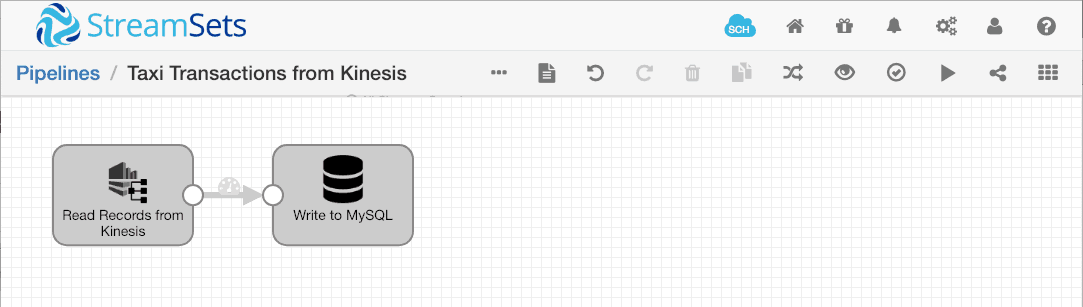
Since the pipeline will be running on EC2, we can leave the AWS credentials blank. Data Collector will inherit the permissions configured in the IAM role associated with the EC2 instance on which it is running:
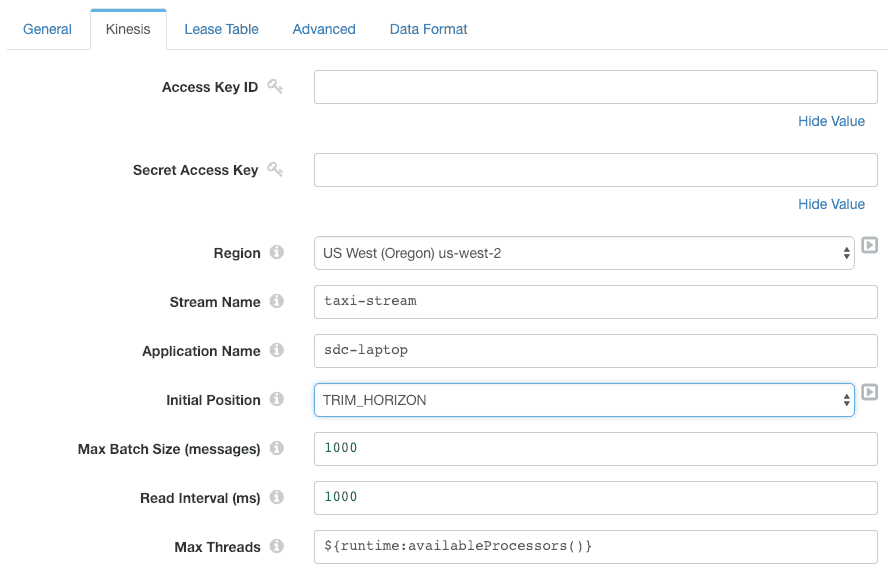
Note that we can configure the initial position at which the pipeline should start. Here we can choose between LATEST, TRIM_HORIZON and AT_TIMESTAMP. The Kinesis Consumer is a multithreaded origin, so we can configure the maximum number of threads that Data Collector will create to ingest data. Data Collector will create multiple threads, up to this limit, to process records concurrently, maximizing record throughput.
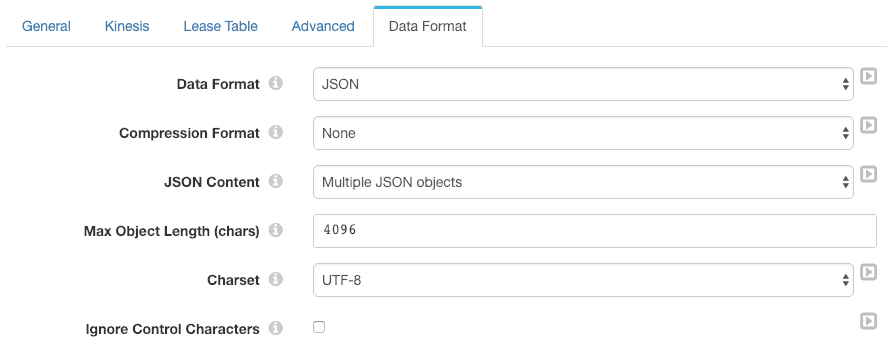
The Kinesis Consumer data format matches the destination data format in the producer pipeline:
I created separate tables for credit card and cash transactions in MySQL, so I could show how records in the same batch can be written to different tables. The only difference between them is that the credit card table has card type and number:
CREATE TABLE crd ( medallion VARCHAR(32), hack_license VARCHAR(32), vendor_id VARCHAR(8), fare_amount DECIMAL(7,2), surcharge DECIMAL(7,2), mta_tax DECIMAL(7,2), tip_amount DECIMAL(7,2), tolls_amount DECIMAL(7,2), total_amount DECIMAL(7,2), rate_code INT, pickup_datetime DATETIME, dropoff_datetime DATETIME, passenger_count INT, trip_time_in_secs INT, trip_distance FLOAT, pickup_longitude DECIMAL(9,3), pickup_latitude DECIMAL(9,3), dropoff_longitude DECIMAL(9,3), dropoff_latitude DECIMAL(9,3), credit_card VARCHAR(16), credit_card_type VARCHAR(16) ); CREATE TABLE csh ( medallion VARCHAR(32), hack_license VARCHAR(32), vendor_id VARCHAR(8), fare_amount DECIMAL(7,2), surcharge DECIMAL(7,2), mta_tax DECIMAL(7,2), tip_amount DECIMAL(7,2), tolls_amount DECIMAL(7,2), total_amount DECIMAL(7,2), rate_code INT, pickup_datetime DATETIME, dropoff_datetime DATETIME, passenger_count INT, trip_time_in_secs INT, trip_distance FLOAT, pickup_longitude DECIMAL(9,3), pickup_latitude DECIMAL(9,3), dropoff_longitude DECIMAL(9,3), dropoff_latitude DECIMAL(9,3) );
On examining the sample data, we can see that some of the records have payment types other than CRD (credit card) or CSH (cash), so we configure a precondition on the JDBC Producer destination to ensure that only records with CRD and CSH payment types are send to the database:
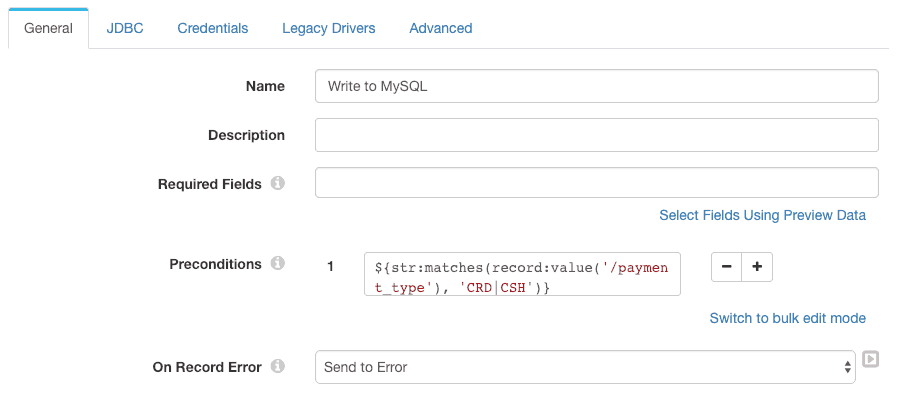
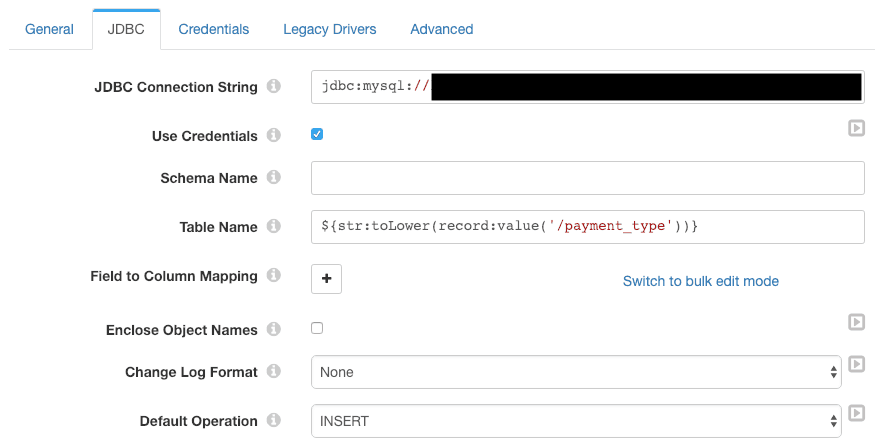
The JDBC configuration is straightforward. Note the table name expression – this is evaluated for each record to send it to the correct table. I didn’t need to define any field to column mappings, since I deliberately created the MySQL tables with column names matching the record field names.
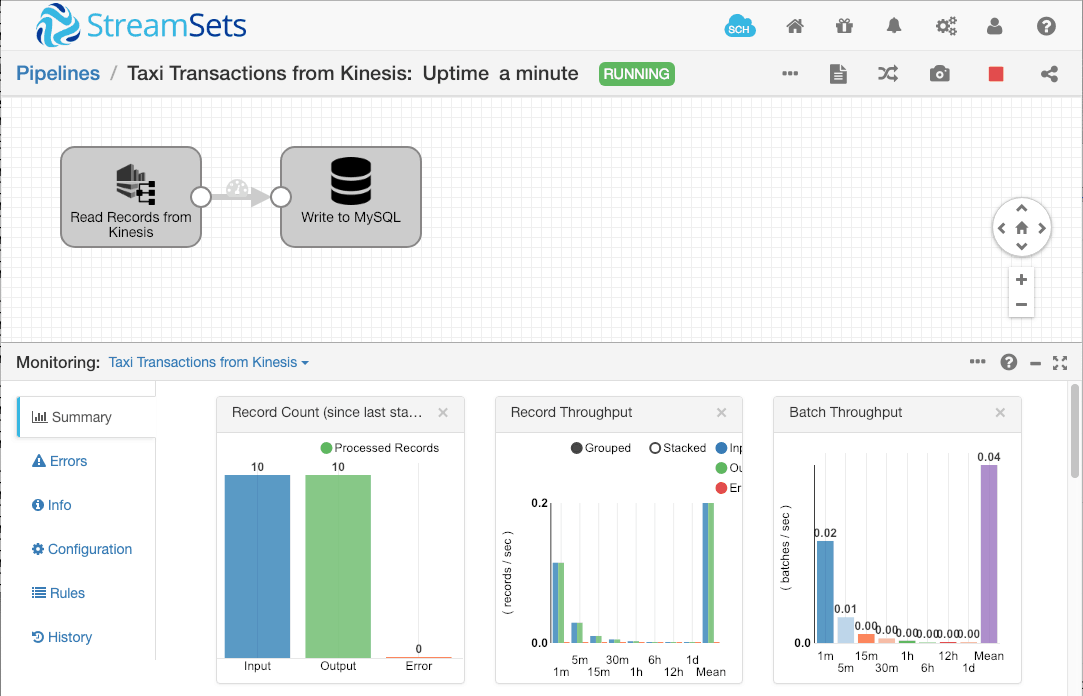
Running the pipeline, it consumes the ten records we wrote to Kinesis earlier:
We can examine the tables in MySQL to check that the data has been written as expected:
mysql> SELECT pickup_datetime, passenger_count, trip_time_in_secs, trip_distance, total_amount, credit_card_type, credit_card FROM crd; +---------------------+-----------------+-------------------+---------------+--------------+------------------+------------------+ | pickup_datetime | passenger_count | trip_time_in_secs | trip_distance | total_amount | credit_card_type | credit_card | +---------------------+-----------------+-------------------+---------------+--------------+------------------+------------------+ | 2013-01-13 04:36:01 | 5 | 600 | 3.12 | 15.00 | Visa | xxxxxxxxxxxx2922 | | 2013-01-13 04:41:00 | 1 | 240 | 1.16 | 8.00 | Visa | xxxxxxxxxxxx9608 | | 2013-01-13 04:37:00 | 2 | 660 | 3.39 | 16.00 | MasterCard | xxxxxxxxxxxx0902 | +---------------------+-----------------+-------------------+---------------+--------------+------------------+------------------+ 3 rows in set (0.00 sec) mysql> SELECT pickup_datetime, passenger_count, trip_time_in_secs, trip_distance, total_amount FROM csh; +---------------------+-----------------+-------------------+---------------+--------------+ | pickup_datetime | passenger_count | trip_time_in_secs | trip_distance | total_amount | +---------------------+-----------------+-------------------+---------------+--------------+ | 2013-01-01 15:11:48 | 4 | 382 | 1 | 7.00 | | 2013-01-06 00:18:35 | 1 | 259 | 1.5 | 7.00 | | 2013-01-05 18:49:41 | 1 | 282 | 1.1 | 7.00 | | 2013-01-07 23:54:15 | 2 | 244 | 0.7 | 6.00 | | 2013-01-07 23:25:03 | 1 | 560 | 2.1 | 11.00 | | 2013-01-07 15:27:48 | 1 | 648 | 1.7 | 10.00 | | 2013-01-08 11:01:15 | 1 | 418 | 0.8 | 7.00 | +---------------------+-----------------+-------------------+---------------+--------------+ 7 rows in set (0.00 sec)
Success!
Now let’s stop the consumer pipeline, reset the database by truncating the tables, then run both pipelines to process all of the input data and send it to MySQL via Kinesis:
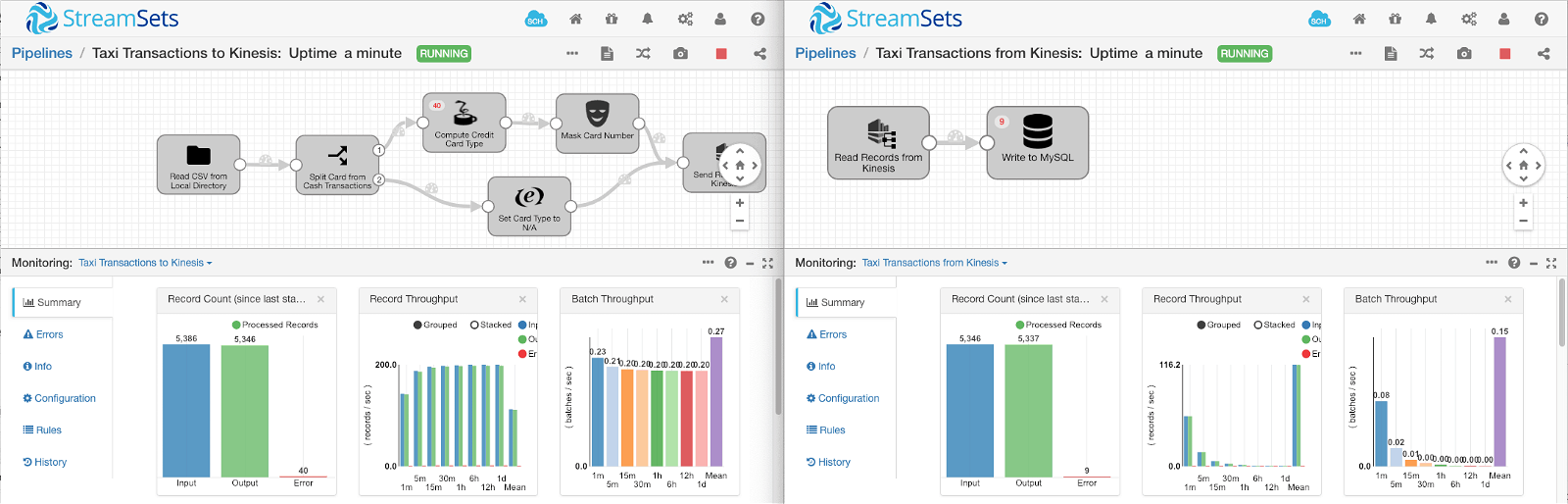
We can see that all of the records sent by the producer pipeline were received by the consumer pipeline. Nine records were not inserted into the database; this is test data and some records are deliberately corrupted to show error handling.
Now we have the data in MySQL, we can begin to perform some simple analyses – how does the transaction count and average total transaction amount differ across card and cash transactions?
mysql> SELECT COUNT(*) FROM crd; +----------+ | COUNT(*) | +----------+ | 2433 | +----------+ 1 row in set (0.00 sec) mysql> SELECT COUNT(*) FROM csh; +----------+ | COUNT(*) | +----------+ | 2904 | +----------+ 1 row in set (0.01 sec) mysql> SELECT AVG(total_amount) FROM crd; +-------------------+ | AVG(total_amount) | +-------------------+ | 17.402795 | +-------------------+ 1 row in set (0.01 sec) mysql> SELECT AVG(total_amount) FROM csh; +-------------------+ | AVG(total_amount) | +-------------------+ | 13.095386 | +-------------------+ 1 row in set (0.00 sec)
There are more cash than card transactions, but the card transactions have a greater average value.
Conclusion
Amazon Kinesis is a stable, production platform for real-time messaging, transporting messages via streams and scaling via shards. The Kinesis command line tools provide a useful basis for testing stream processing, while StreamSets Data Collector allows you to easily build dataflow pipelines that send and receive data via Kinesis. The Kinesis Producer destination allows you to control how data is sent to Kinesis shards, and the multi-threaded Kinesis Consumer origin can scale to handle high levels of concurrent throughput.
Try StreamSets Data Collector on AWS today and get started sending data via Amazon Kinesis.
![]()