We all know the shift to the cloud is massive and has been accelerated by COVID; however, I think many of us (myself included) don’t take enough time to really look at the new cloud-native services for doing data enrichment and analytics.
AWS Re:Invent last December was a great opportunity to talk to customers, prospects, and other technology companies. Meeting ChaosSearch was one of those opportunities I’d like to highlight and tell you about how our two products can really help our customers in their cloud modernization efforts.
The Problem: Data Lakes Aren’t Built for High-Performance Analytics
Cloud analytics requires a different approach and architecture. The Modern Data Architecture does just that and takes into account the proliferation of new data sources (e.g. new SaaS apps), destinations (e.g. cloud data store), and increasing data volumes and types.
The ability for an organization to easily adapt to these changes has a direct impact on how well they’re able to get insights that help them make the best decisions at the right time.
However, getting to those precise data points is difficult when you have data from so many different systems–systems that have vastly different formats and do not always integrate cleanly.
The solution for many organizations has been the Data Lake because of its cheap-ish storage. But, storage is just one aspect of the solution.
The reality is that the cheap storage that Data Lakes is built on was never designed for high-performance analytics that businesses need to take advantage of their investment in data in the first place.
What you end up with is a data swamp! Let’s consider some classic use cases.
Log Files
Everyone produces this type of data whether you realize it or not. And, the data stored inside of these files can help you to determine systems issues, intrusion detection, application issues, and more.
However, log files are not exactly in the best format to easily glean the information that they contain. And the fact that the format also shifts (or as we like to say here at StreamSets “data drift”) makes it very difficult for upstream systems to consistently and accurately extract that information.
One such piece of data can be an IP Address of the system that was interacting with your application. That data alone can provide you with tons of information such as the geolocation of where the machine was at. You can even link it back to the ISP that the user was on. Depending on your needs, the latter may be a bit much but that simple 4 octet of numbers is very powerful if you can enrich it.
With StreamSets, you can not only break apart the log file but you can also reach out to other systems and use data enrichment on the payload before writing it into your Data Lake.
IoT
Given how just about everything now has a sensor (or will have a sensor in the near future) IoT devices are probably the biggest producers of data and will continue to be for a while. However, given that the devices they run on are incredibly small and have both limited power and storage, the data produced from these devices needs to be both very tiny and very rich.
Being able to translate the machine ID to something that is readable for a human needs to happen before you drop this information into your Data Lake.
The Solution: The Best Approach for Today’s Data Enrichment & Analytics
How exactly do StreamSets and ChaosSearch help solve this problem?
StreamSets
Customers use StreamSets in a variety of ways for data movement and data enrichment. StreamSets pipelines are always processing your various systems into your Data Lake to keep it current with your company.
- Data Collector Engine: Run on-premise or in your PaaS.
- Continuous Pipelines
- Patented data drift technology: Ability to detect and handle changes in your data with no downtime.
Data formats: StreamSets supports all Industry Standard formats without a user needing to fully understand how to implement them, such as Avro/Parquet for example. Just select which output you need and StreamSets takes over.
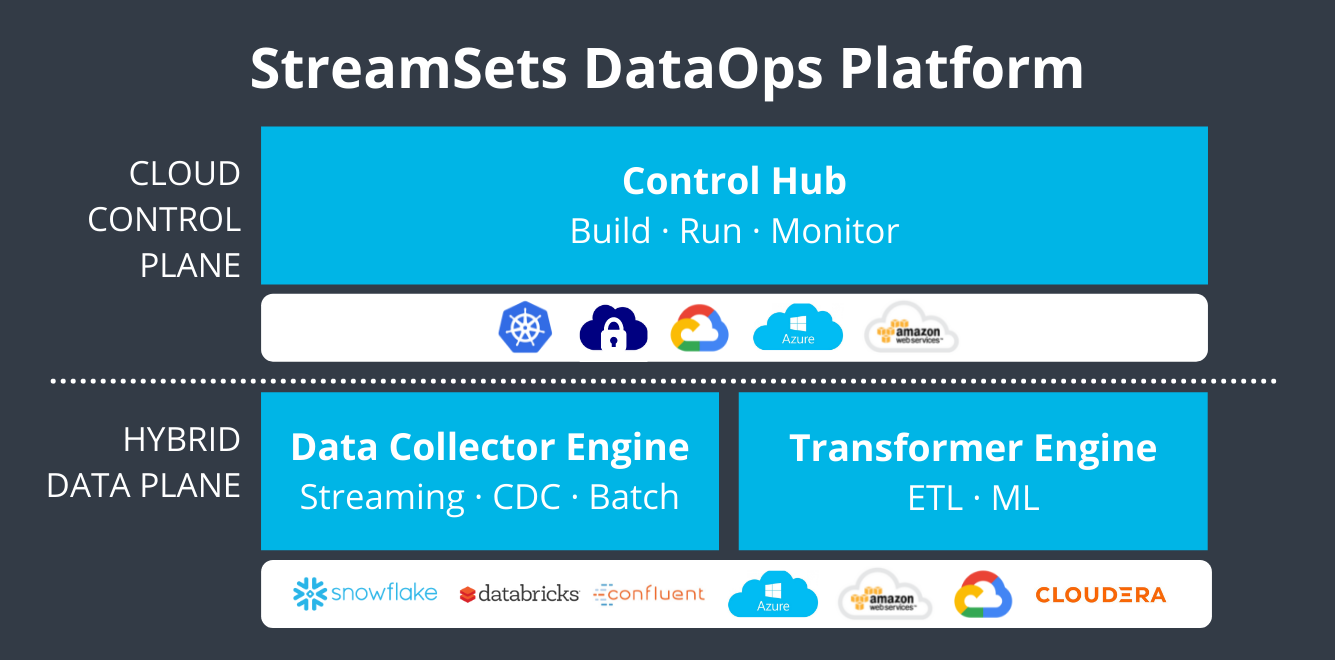
ChaosSearch
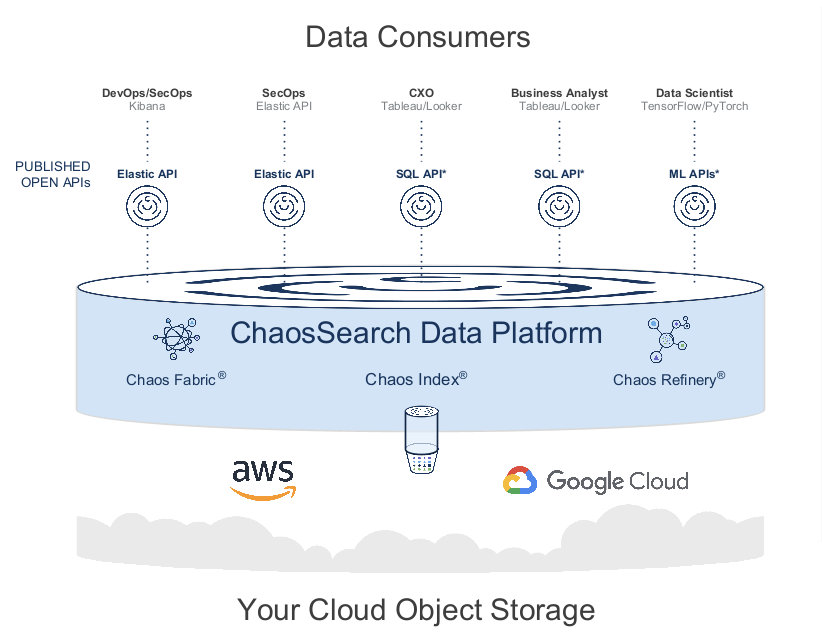
From our meeting with ChaosSearch, it’s evident that their platform is built to scale alongside your modern data architecture to provide a hot analytics environment that does not require additional data movement. ChaosSearch does this with three unique offerings that combined allow for Multi-model access of Search, SQL, and ML.
- Chaos Index: Ability to compress your cloud object store by 80-90% that is searchable, performant, and 100% lossless of data.
- Chaos Fabric: Fully managed, scalable, stateless architecture decoupling compute from storage.
- Chaos Refinery: Ability to perform a virtual transformation on your data
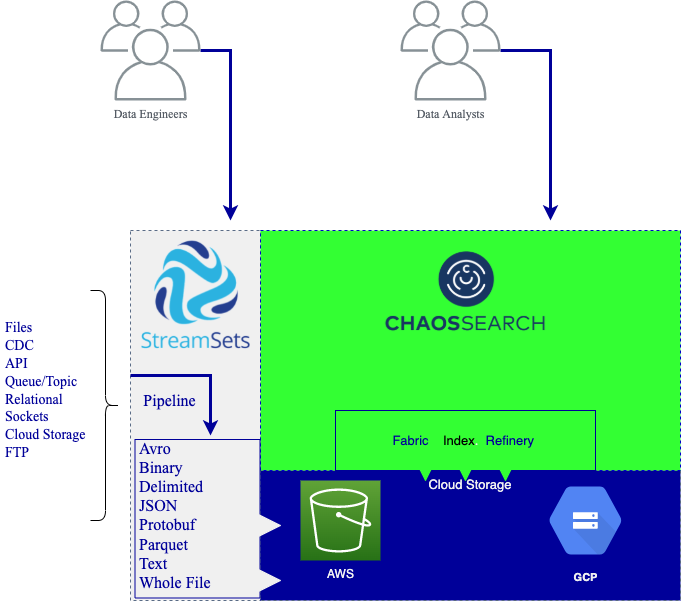
StreamSets and ChaosSearch: Better Together
Architecture diagrams speak a thousand words. In the diagram below, you’ll see:
- StreamSets is used for ingestion into your Data Lake (and data enrichment if required).
- Continuous data pipelines guarantee business decisions made on the most recent data
- Data loaded is in the correct format
- AWS / GCP offers cheap, elastic storage that is always available
- ChaosSearch is able to compress and index data for high-performance analytics whether for SQL, Search, or ML.
Conclusion
Being data-driven is a business requirement these days. But, ingesting and analyzing data is only a piece of the pie. The most successful companies and data teams understand that efficient, well-built data architecture is a critical foundation for long-term success and enables quick and impactful decision-making.
By utilizing the combination of StreamSets and ChaosSearch you can ingest your data from virtually anywhere, in any format, and place it into your Data Lake for quick and accurate data harvesting at the speed of your business–data enrichment and analytics for scale.