StreamSets Data Collector’s HTTP pipeline stages allow a wide range of API integrations. I recently built a data pipeline to integrate customer data from a MySQL database: retrieving, creating and updating leads in Marketo via their REST API. I’ll share the Marketo data integration pipeline with you today as a real-world application of data ingestion with StreamSets Data Collector. I’ve included videos that show various elements of the pipeline in action for automating data integration.
Use Case: Integrating MySQL with the Marketo REST API
In common with many companies, StreamSets uses Salesforce for customer relationship management, and Marketo for marketing automation. My challenge, as de facto data engineer for the StreamSets product and marketing teams, was to build a pipeline to read new activations from MySQL, search Marketo for an existing lead, merge the existing lead data with the newly provided data, create or update the lead in Marketo as appropriate, and, finally, add the lead to a campaign. Marketo, in turn, can then take appropriate actions such as writing the lead to Salesforce or sending the customer a welcome email.
It took me less than an afternoon to achieve all that with Data Collector, most of which I spent reading the Marketo REST API documentation.
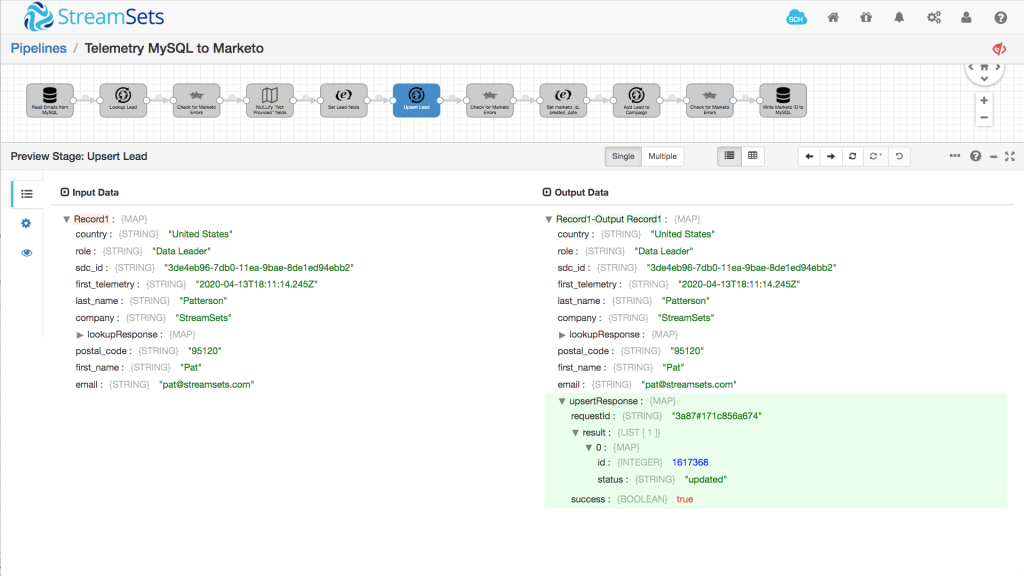
Reading Lead Data from MySQL
It was easy to use Data Collector’s JDBC Query Consumer origin to read rows from the registration table in MySQL. Here’s a simplified version of the query I used:
SELECT t1.email, t1.first_name, t1.last_name, t1.company, t1.country country, t1.postal_code postal_code, t1.role role FROM sdc_registration t1 LEFT JOIN sdc_sent_to_marketo t2 ON t1.email = t2.email WHERE t2.email IS NULL;
The first thing to notice is that I’m joining the sdc_registration table (t1) with the sdc_sent_to_marketo table (t2). Our activation system writes to t1; my pipeline writes email addresses to t2 after it’s done interacting with Marketo.
Note that this is an anti-join – I’m joining on t1.email = t2.email, but applying the condition, WHERE t2.email IS NULL. In English, this means, “Give me the rows from t1 with email addresses that are not in t2“.
I configured the JDBC Query Consumer to repeat the query every ten minutes. I could have used the MySQL Binary Log origin to obtain a feed of database changes (a technique known as change data capture, or CDC), but the CDC configuration is more complex and there was no requirement for near real-time response. Periodic SQL queries are easy to implement, and give us exactly the data we need.
Looking up Leads via the Marketo REST API
The requirements for this task stated that I could only enrich the data in Marketo, not overwrite it, so I needed my pipeline to look up leads in Marketo by email, retrieving first name, last name etc for any leads that already exist.
Marketo’s Lead Database API makes this a snap – I configured an HTTP Client processor to fetch the relevant fields via an HTTP GET:
You’ll notice my extensive use of runtime parameters in the pipeline configuration. Runtime parameters allowed me to collect the pipeline configuration in one spot, making it easy to change database URLs for different environments, and reuse configuration across multiple pipeline stages.
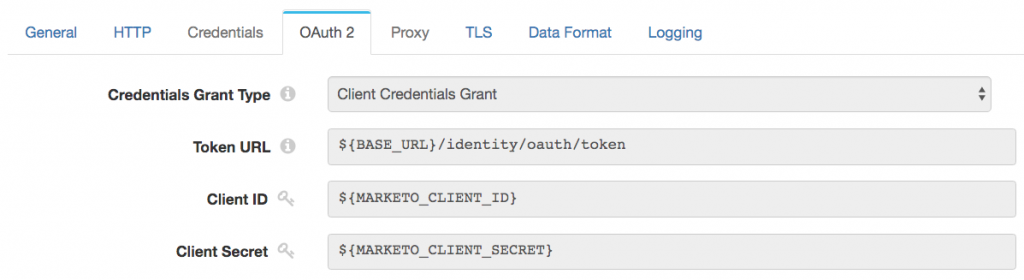
In common with many similar APIs, Marketo’s REST APIs are authenticated with the OAuth 2.0 client credentials grant type, colloquially known as ‘2-legged’ OAuth 2.0. The OAuth 2.0 protocol defines mechanisms to obtain access tokens for APIs. The client credentials grant type allows client apps to exchange long-lived credentials (client id and secret) for a short-lived access token. Client apps then present the access token (also known as a ‘bearer token’) in an HTTP header with each API access. You define a custom service in Marketo to obtain the necessary client id and secret to configure the HTTP Client Processor.
Marketo’s access tokens have a lifetime of one hour. API calls made with an expired access token return an error, in response to which the client app must obtain a new access token and retry the API call. Data Collector’s HTTP stages manage the OAuth token flow, including expiration and refresh, automatically.
After I’d finished the remainder of the pipeline, and let it run for an hour or so, I noticed a wrinkle in Marketo’s REST API implementation. Typically, on receiving a call containing an expired access token, an API will return a response with HTTP status code 401, ‘unauthorized’, and some additional detail in the response body. Marketo’s REST API returns HTTP status code 200, ‘success’, and the error details, like this:
{
"requestId": "12345#123456789ab",
"success": false,
"errors": [
{
"code": "601",
"message": "Access token invalid"
}
]
}
This means that the HTTP Client Processor is unable to handle token expiration, since the HTTP status code is just the same as a successful API call. The result was that downstream pipeline stages were not receiving the data they expected, and the pipeline logged all subsequent records as errors. Worse, the pipeline had no way to automatically recover, since the HTTP Client Processor could not recognize the access token expiry and request a new one.
Custom API response handling
The answer was to use a script evaluator to implement custom logic to test for access token expiry and take appropriate action. You can implement custom logic with Jython (a flavor of Python that runs on the Java Virtual Machine), JavaScript or Groovy. I tend to use Groovy as its syntax is very close to Java, there’s easy integration with existing Java code, and the Groovy Evaluator typically performs better than its JavaScript or Groovy equivalents.
Here’s my Groovy script to detect the expired token and throw an appropriate error:
import com.streamsets.pipeline.api.StageException
import com.streamsets.pipeline.api.ErrorCode
outputField = 'lookupResponse'
records = sdc.records
for (record in records) {
if (! record.value[outputField]['success'] &&
"601".equals(record.value[outputField]['errors'][0]['code'])) {
throw new StageException(
new ErrorCode() {
public String getCode() { return "MARKETO_01" }
public String getMessage() { return "Marketo API call failed: " + record.value[outputField]['errors'][0]['message'] }
}
)
}
// Write a record to the processor output
sdc.output.write(record)
}
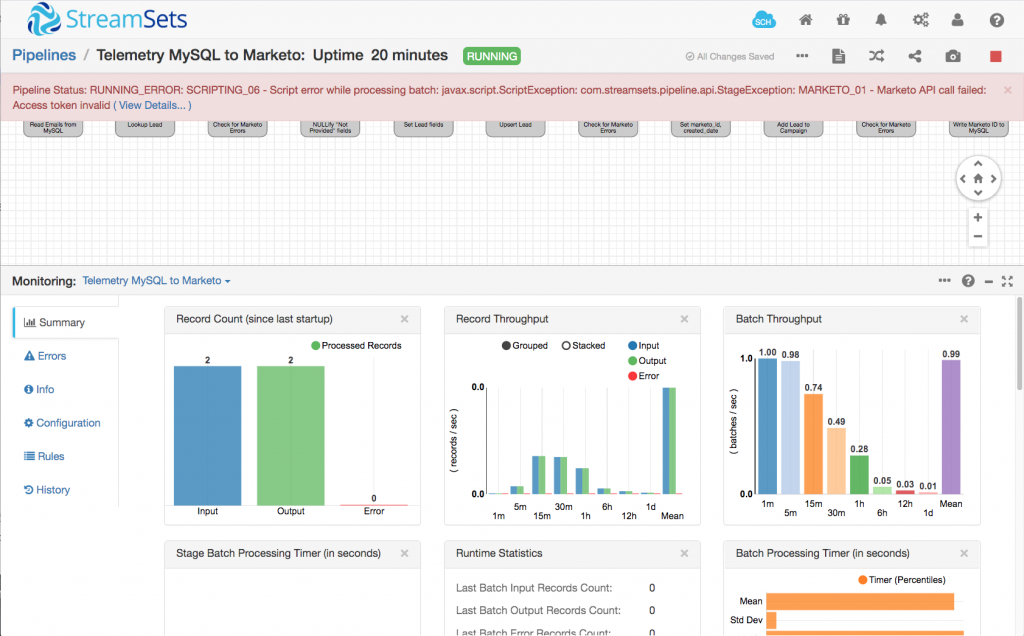
The script is pretty simple: for each record, if success is false, and the error code is 601, it throws a StageException with an appropriate message. This has the effect of stopping the pipeline, which is exactly what we want, since we can configure the pipeline to automatically restart, allowing the HTTP Client processor to obtain a new access token and continue making API requests:

Here is my pipeline soon after a restart – as you can see, the StageException is clearly displayed in the UI.
The pipeline history records the sequence of events – the pipeline is down for about 2 seconds:
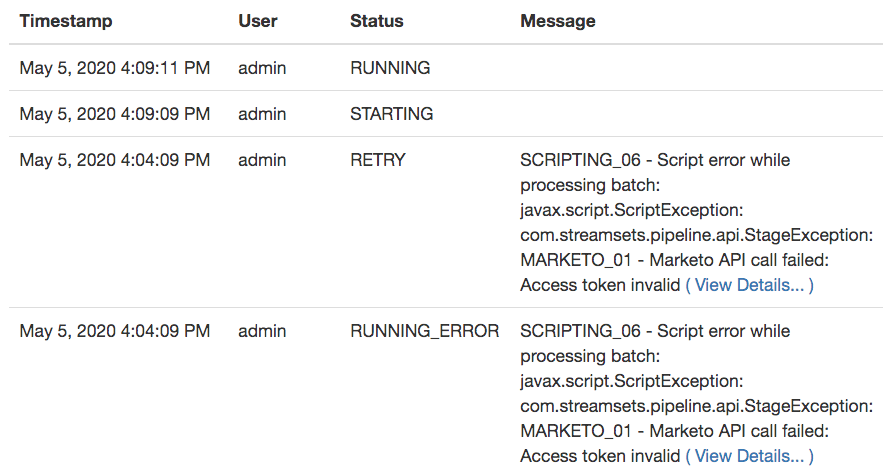
Note that no data is lost during the pipeline restart. The records in the current batch are simply reprocessed when the pipeline resumes. The pipeline’s interaction with Marketo is idempotent – we can repeat the lookup, create/update, add-to-campaign operations multiple times with no difference in the overall function.
Wrangling Data with Field Mapper
I soon discovered that Marketo returned Not Provided in some fields where it had no data. To make the merge logic easier, I configured a Field Mapper to replace Not Provided with NULL in the lookup response:
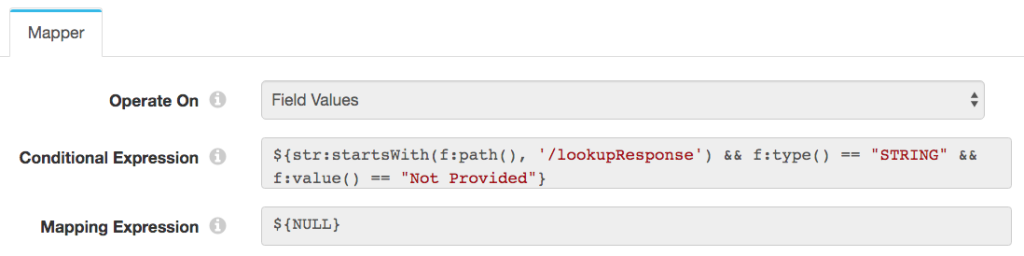
Merging Data with Expression Evaluator
Now I have both the row from the MySQL query and the lead data (if any) from Marketo in the record, I can merge the data, with an Expression Evaluator. The rule is simple – if there is data in a field from Marketo, I should use it. Otherwise, I should use the data from MySQL. Looking at ‘first name’, I set the /first_name field to the expression:
${record:valueOrDefault('/lookupResponse/result[0]/firstName', record:value('/first_name'))}
This says, set /first_name to the value from Marketo, in /lookupResponse/result[0]/firstName, if there is one, otherwise keep the value from MySQL.
Repeating this for each field merges the data:
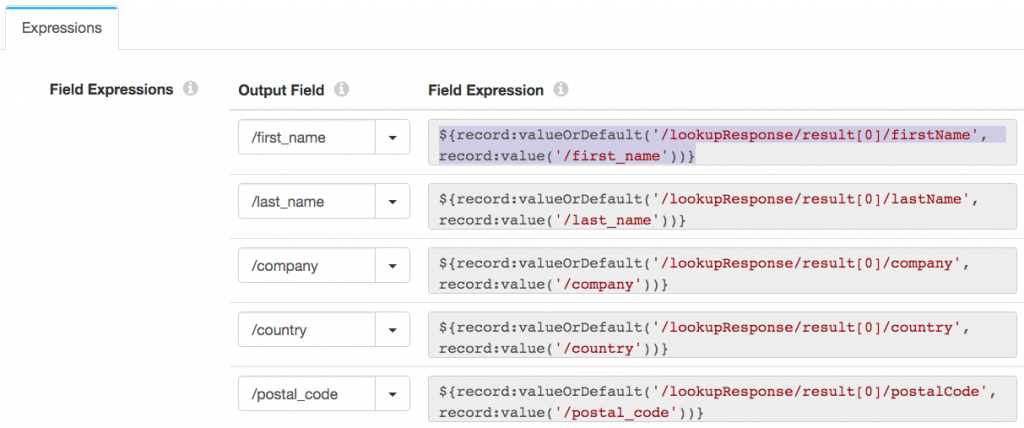
Note that, if the lead was not found in Marketo, all of the /lookupResponse/result[0] fields will be missing, so the data from MySQL will be used.
Creating and Updating Leads in Marketo
Now I have my record in good shape, I can create a new lead in Marketo, or update an existing one, as appropriate. I could have used a Stream Selector to send records along different processing paths depending on whether or not the lead was found in Marketo, but I found a simpler solution. Marketo’s Lead Database API supports a number of different actions in a Lead request – createOnly to create a lead with the given data, updateOnly to update an existing lead, indexed by its email address, and createOrUpdate. This last action creates a new lead if one does not exist, otherwise it updates the existing lead. This combined operation is often known as an ‘upsert’. Just what we’re looking for!
I used the HTTP Client processor to POST the lead data to the relevant URL:
Again, I used a Groovy Script Evaluator to check for token expiry.
The upsert API call returns the lead ID, so I used another Expression Evaluator to move it to a more convenient location and also to add a timestamp to the record:

Adding Leads to a Marketo Campaign
The final interaction with Marketo is to add the lead to a campaign, representing the fact that the lead was created or updated as a result of a product activation. The HTTP Client processor configuration is straightforward:
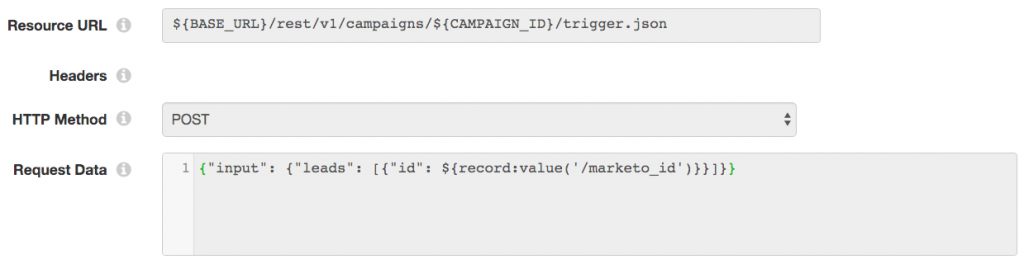
Updating the MySQL Database
Now that we have completed Marketo processing, we use the JDBC Producer destination to write the email address and timestamp to a MySQL table, sdc_sent_to_marketo, so that it is excluded from the next query:
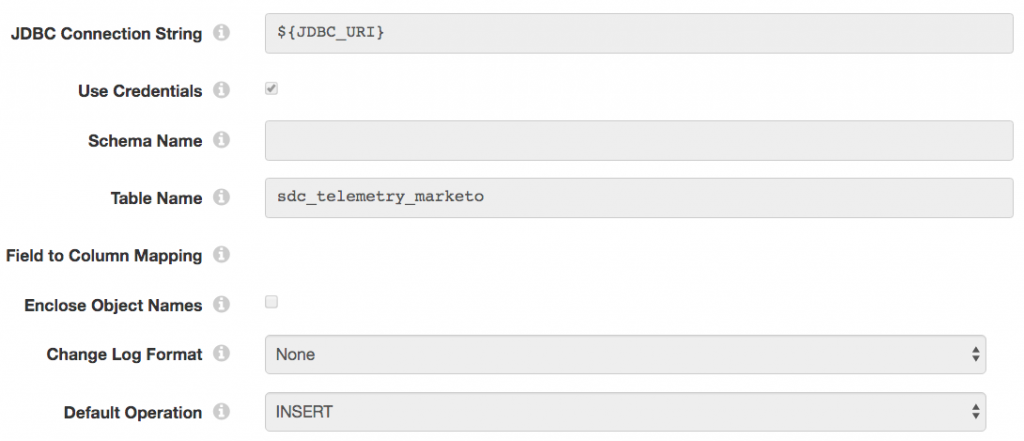
Note that no field-to-column mapping is required since the record field names correspond to the MySQL column names – the JDBC Producer matches them up automatically.
Using the sdc_sent_to_marketo table meant that I could leverage the database to track processed records, and, by simply truncating the table, I could easily reprocess all the data as I refined my pipeline.
Here’s a short video of my production pipeline in action. You’ll notice that some of the configuration is different from the explanation here – I left out some details that aren’t relevant to the main use case.
Conclusion
It actually took me longer to write this blog post than it did to create my data pipeline. It’s been running for about a week now, restarting every hour or so, processing data pretty much 24/7. StreamSets Data Collector’s HTTP Client stages, with their OAuth 2.0 support, make it easy to integrate with the vast majority of REST APIs. Get started today!