 Maryann Agofure is a Cloud engineer and technical writer who loves fried plantains. She’s currently on a cloud data engineering journey to gain a deeper understanding of data pipelines for better analysis, hence her interest in data orchestration, and seeking ways to grow her knowledge with big data tools. Her job as a Technical writer also helps her research and build on her already existing knowledge and skills.
Maryann Agofure is a Cloud engineer and technical writer who loves fried plantains. She’s currently on a cloud data engineering journey to gain a deeper understanding of data pipelines for better analysis, hence her interest in data orchestration, and seeking ways to grow her knowledge with big data tools. Her job as a Technical writer also helps her research and build on her already existing knowledge and skills.
Data Never Sleeps 5.0 reports that the amount of data generated by users daily amounts to over two quintillions (2,000,000,000,000,000,000). Companies can perform analysis and draw actionable insights to make profitable business decisions thanks to this data. Healthcare, retail, e-commerce, and industrial sectors use big data to further their goals and drive business decisions.
However, data must undergo some processing and analytics before its utilization. A data pipeline represents a series of data processing steps that help move data between a source and a destination. The data source may be from multiple origins like applications, websites, and destinations may include data warehouses, data lakes, etc. Each processing step plays an essential role in the final data quality, hence the need for companies and data engineers to establish effective data pipeline processes.
Effective data pipeline processes also allow for:
- Faster operations. With an effective pipeline method, steps in the processing phase are easily replicated and applied with each growing process instead of authoring one from scratch.
- Increased confidence in data quality. According to Gartner research, organizations lose over $9.7 million per year to poor data quality. With a carefully established process and monitoring in place to handle the data processing journey and catch and fix errors, companies can trust the quality of their final data output.
- Effective data management. Establishing an organized data flow ensures processes are maintained and data is easily accessible and managed.
Handling Data Workflows in the Past
Before data orchestration, the data workflow was a manual process. For example, data entry clerks could be responsible for manually loading data into a database, or data engineers were running scheduling cron jobs manually. However, this method relied heavily on manual labor and had the following limitations:
- Human errors
- Complexity in workflow
- Increased engineering time to set up and execute
- Data security issues
This practice led to poor data quality leading to poor business decisions. Additionally, as the quantity of data increased, it became harder to scale and more labor-intensive.
A Modern Approach: Data Orchestration Pipelines
Data orchestration describes the process of automating the data pipeline process. It is a data operations solution that involves automating the process of data collection, transformation, and analytics. Before data orchestration, data engineers had to create, schedule, and manually monitor the progress of data pipelines. With a data orchestration solution, engineers automate each step in the data workflow.
Here are some benefits of data orchestration:
- Faster decision making. By automating each stage, data engineers and analysts have more time to perform and draw actionable insights, hastening the decision-making process.
- Reduced room for error. A common pitfall associated with manual scheduling in the past was human-prone errors. Programming the entire data pipeline process eliminates the room for such errors.
- Increased visibility and enhanced data quality. Data orchestration helps break down data silos and makes data more available and accessible for analytics. Also, because each step in the data orchestration process executes in a streamlined manner and catches errors at each stage, companies can trust the quality of their data.
Building a Data Orchestration Stack
A data stack represents a collection of technologies, with each specializing in a step of the data journey. Data stacks ensure a free flow of data with each step in the data workflow. Hundreds of technologies are now available to help move, manage, and analyze data more efficiently. When building a data orchestration stack, here are some things to consider:
- The data flow. These tools help move, transform, and manipulate your data along the data journey from its source to its destination.
- The metadata layer. This considers the structure of your data like its schema, statistics like runtime, and data quality metrics. Metadata insights are important because they keep data updated and help with auditing and detecting errors along the data workflow.
- The DevOps/DataOps layer. The DevOps tooling layer considers the authoring, testing, and deployment tools used to build and manage your organization’s data flow.
Read more on how these layers can help you decide on your modern data stack tools.
A Data Orchestration Pipeline in Action
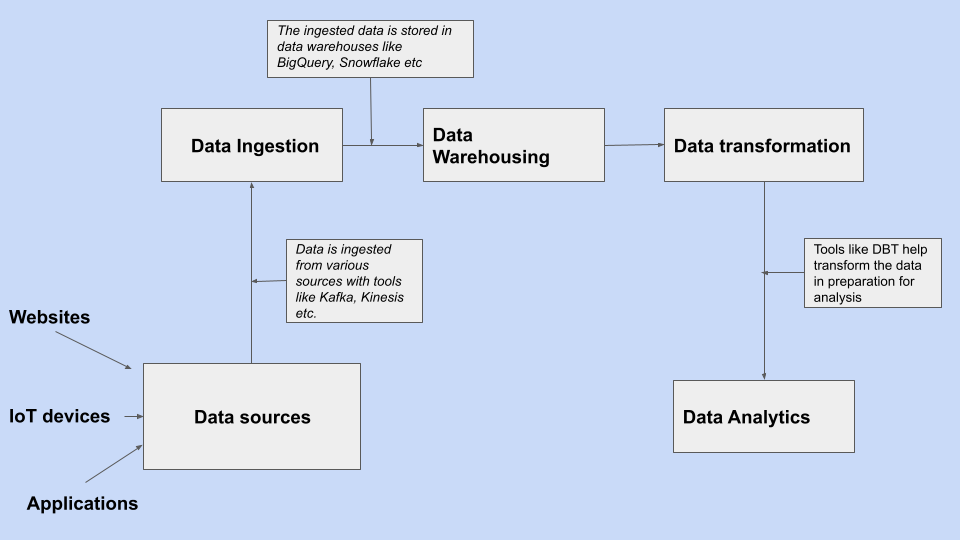
Picture a health tech organization looking to make more use of its data. A modern data stack and how each technology functions along each step of the data journey may look like this:
- Cloud tools like Amazon Kinesis and Kafka are data ingestion tools that help transport data from various sources to a target destination for analysis and transformation. StreamSets also sits in this space and can help engineering teams build for Kafka and Kinesis in a graphical environment, according to their preferences but their DataOps solution offers much more than data ingestion. Data ingestion sources include web and mobile applications, social media, and Internet of Things (IoT) devices. With Kinesis and Kafka, companies can collate and stream massive amounts of datasets in real-time. For example, an e-commerce company can pull data from its web application, social media, and app campaigns. Efficient data pipelines that help stream this data to storage locations like data warehouses ensure a better working process.
- Ingestion tools help load these data into data warehouses. Data warehouses help perform extensive scale analysis. Amazon Redshift, Snowflake, and Google BigQuery are highly scalable data warehouses that can perform analysis on massive datasets to gain insights through analytical dashboards and operational reports to help make business decisions.
- The data loaded into the warehouse needs to undergo transformation and cleaning in preparation for analysis. This transformation may involve renaming columns or aggregating data. Data Build Tools (DBT) is an SQL command-line tool that helps data engineers and analysts transform their data and build data models for further analysis. StreamSets transformer tool for Spark also provides powerful pipelines for stream processing operations.
- Analytics tools like Power BI help analyze and visualize analytics results by creating interactive dashboards to deliver better insights for business decisions.
- Full-featured data integration tools like StreamSets enable you to design, build, deploy, and manage your data workflow with its DataOps platform solution.
Summary
Companies view data as the real gold in today’s world of business. Data insights can help make critical business decisions in an organization. However, data must be processed and analyzed before usage. Hence, the need for data pipelines to guide the entire data journey.
Data engineers and analysts use data pipelines to better manage the data workflow from its origin or storage to its destination for analysis or insights. However, before data orchestration, data engineers manually configured each data pipeline process, making it prone to errors and slower operations.
Adopting a modern data stack that helps perform each pipeline process creates a more streamlined and efficient operation and eliminates unhealthy data from your workflow. Configuring a data stack comes with its challenges, but specific tools help ease the engineering workload by providing accessible data integration platforms. Learn more on how organizations like StreamSets help teams build innovative data pipelines and can help your engineering team effectively do more with your data.
