The speed of change in today’s business environment is staggering. Customer needs and business trends are ever-evolving; regulations, technologies, and even cloud service provider preferences within an organization can change in an instant. Any one of these can wreak havoc on your data pipeline management and result in hours of rework and debugging. Get the basics of data pipeline automation.
Data Pipeline Automation: The Challenges of Traditional Data Pipelines and ETL Tools
Building and debugging traditional data pipelines or ETL pipelines can take a significant amount of time and leave data pipelines offline. Even a small change to a row or a table can mean hours of rework to update each stage then debug and deploy the new data pipeline.
“Data drift” – unplanned, unexpected, and unending changes to data – can also mess with data analysis. It can take months to uncover and fix the hidden breakages caused by drift.
Finally, since traditional data pipelines are coded for specific frameworks, processors, and platforms, any change needed can mean weeks or months of rebuilding and testing before you get them back online.
The problem is well-known and so is the solution: an approach that leverages the idea of DataOps and automating as much as possible when it comes to data pipelines.
The Power of Data Pipeline Automation and Reusable Fragments
With StreamSets DataOps Platform, pipelines are easily set up and operated continuously with very little manual intervention. One way to maintain uptime and decrease complexity is through the use of pipeline fragments: a stage or set of connected stages that you can use and reuse across pipelines to reduce duplication.
With reusable pipeline fragments, you can make updates to running pipelines with just 1 second of downtime. StreamSets quickly shuts down and migrates the pipeline to the version that has the newest fragment, and then starts it up again exactly where it left off in the previous run.
3 Use Cases for Pipeline Fragments
1. Pull data from new data sources with origin fragments
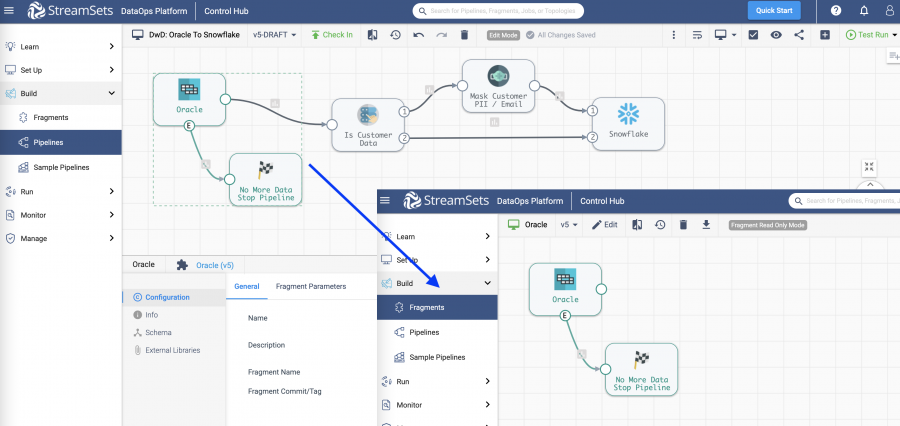 Imagine you’ve been pulling data into your pipeline from an on-premises Apache Kafka instance. Due to a company policy of moving to managed services, your pipelines now need to point to a Kafka-compatible messaging service running in the cloud.
Imagine you’ve been pulling data into your pipeline from an on-premises Apache Kafka instance. Due to a company policy of moving to managed services, your pipelines now need to point to a Kafka-compatible messaging service running in the cloud.
With pipeline fragments, it’s as easy as updating your origin fragment; instead of having to rewrite the business logic repeatedly, you make the change in one place and simply propagate it to the pipelines that depend upon that logic.
Instead of asking each data engineer to go through 5 different steps to add the new source, you can manage the whole process centrally with just a couple of clicks.
2. Reuse transformation logic with processor pipeline fragments
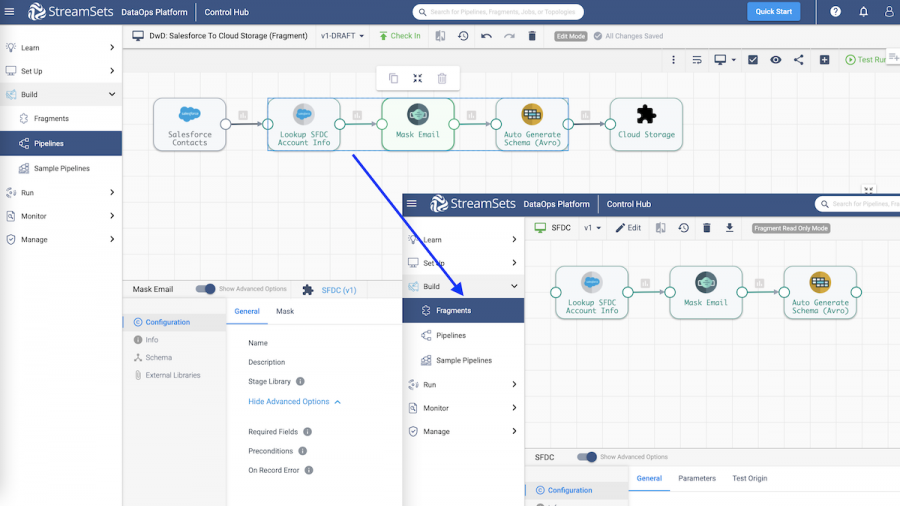
For example, to use the same set of processing logic for all pipelines that migrate Salesforce contact data to cloud storage, you can create a pipeline fragment that includes the processors you want to use, such as the Field Masker processor to mask sensitive string data. You can even include runtime parameters to change configuration values in each pipeline that uses the fragment. After you publish the fragment, you add it to the pipelines as needed, allowing you to reuse the processing logic and reduce configuration drift.
3. Change your cloud platform with destination pipeline fragments
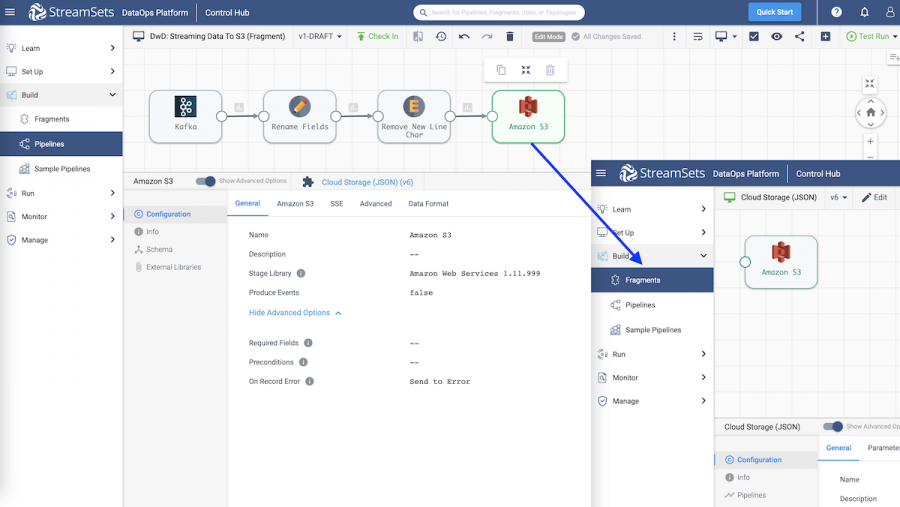
Let’s say Vic, your data platform administrator, has decided you’re moving from Google Cloud Platform to AWS (or vice versa – we love them both!) because he has determined that it will save the company money.
Instead of asking each data engineer to rewrite all of their pipelines (yikes!), Vic can manage the migration with reusable pipeline fragments. Pipelines that make use of the fragments can be updated quickly without the need for anyone else to even be aware of it. Now that’s flexibility!

Automated Pipelines Are Built for Change
In a world where change is constant, pipelines need to deliver real-time data and be able to be changed in real-time. By using smart data pipeline tools and pipeline fragments make that real-time change and data pipeline automation success possible.
Try them out yourself with StreamSets, a fully cloud-based, all-in-one DataOps platform. Sign up now and start building pipelines for free!
With StreamSets you can:
- Quickly build, deploy, and scale streaming, batch, CDC, ETL and ML pipelines
- Handle data drift automatically, keeping jobs running even when schemas and structures change
- Deploy, monitor, and manage all your data pipelines – across hybrid and multi-cloud – from a single dashboard