Guest post by Rishi Jain, Technical Support Engineer III, StreamSets.


In this blog post, you’ll learn the recommended way of enabling and using kerberos authentication when running StreamSets Transformer, a modern data transformation engine, on Hadoop clusters.
Generally speaking, the –proxy-user argument to spark-submit allows you to run a Spark job as a different user, besides the one whose keytab you have. That said, the recommended way of submitting jobs is always to use the –principal and –keytab options. This allows Spark to both keep the tickets updated for long running applications, and also seamlessly distribute the keytab to any nodes spinning up an executor.
It is possible to use –proxy-user with Transformer and the way we can achieve this is via k5start. This tool takes care of obtaining a ticket from the KDC (like kinit), but it also refreshes the token periodically based on the parameters, similar to what SecurityContext in StreamSets Data Collector. However, unlike SecurityContext, it writes to a ticket cache and keeps that cache updated as tickets expire, so that child processes (like spark-submit) can always get the latest version.
To enable different users to run transformer jobs on a Hadoop cluster, you must configure user impersonation.
In this blog, we will review the following two scenarios:
- Impersonation in transformer without Kerberos
- Impersonation in transformer with Kerberos
Before we jump into these scenario let’s review the prerequisites.
Transformer Proxy Users Prerequisites
When using a Hadoop YARN cluster manager, the following directories must exist:
- Spark node local directories
The Spark yarn.nodemanager.local-dir configuration parameter in the yarn-site.xml file defines one or more directories that must exist on each Spark node. The value of the configuration parameter should be available in the cluster manager user interface. By default, the property is set to ${hadoop.tmp.dir}/nm-local-dir. And the specified directories must:
- Exist on each node of the cluster
- Be owned by YARN
- Have read permission granted to the Transformer proxy user
- HDFS application resource directories
Spark stores resources for all Spark applications started by Transformer in the HDFS home directory of the Transformer proxy user. Home directories are named after the Transformer proxy user, as:
/user/<Transformer proxy user name>
Ensure that both of the following requirements are met:
- Each resource directory exists on HDFS
- Each Transformer proxy user has read and write permission on their resource directory
For example, you might use the following command to add a Transformer user, rishi, to a spark user group:
usermod -aG spark rishi
Then, you can use the following commands to create the /user/rishi directory and ensure that the spark user group has the correct permissions to access the directory:
sudo -u hdfs hdfs dfs -mkdir /user/rishi sudo -u hdfs hdfs dfs -chown rishi:spark /user/rishi sudo -u hdfs hdfs dfs -chmod -R 775 /user/rishi
Impersonation without Kerberos
As the user defined in the pipeline properties, Transformer uses the specified Hadoop user to launch the Spark application and to access files in the Hadoop system. This is the most straightforward and the simpler setup of the the two.
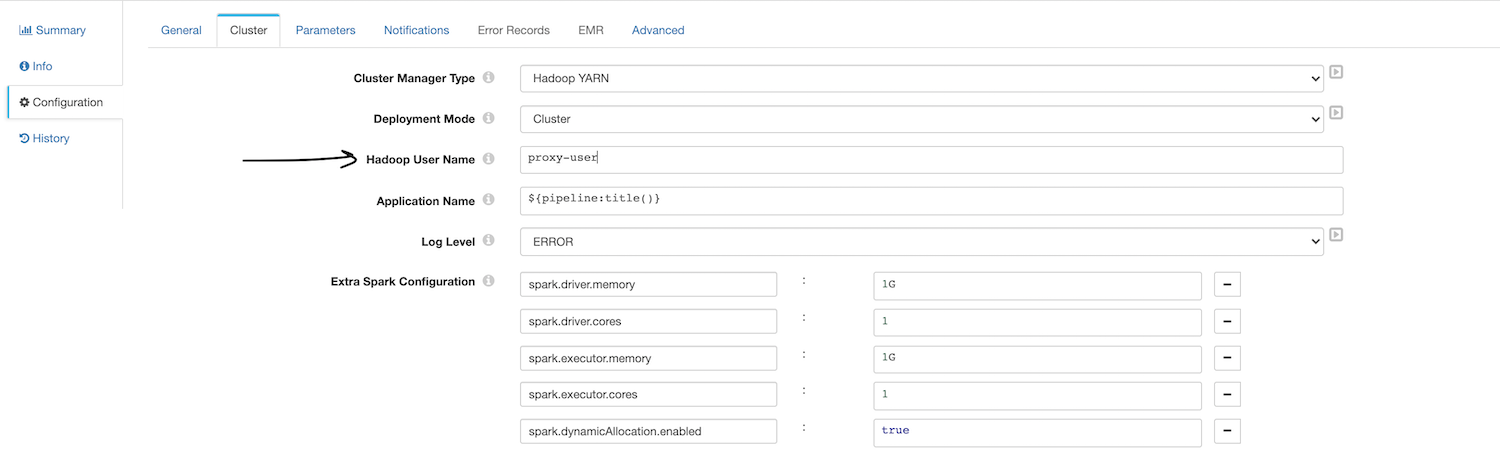
Impersonation with Kerberos
This is a bit more involved so let’s deep dive in and try to understand how this works. As shown below, Transformer provides two options to specify the keytab/principal.

- Properties file
When a pipeline uses the properties file as the keytab source, the pipeline uses the same Kerberos keytab and principal configured for Transformer in the configuration file, $TRANSFORMER_DIST/etc/transformer.properties. For information about specifying the Kerberos keytab in the Transformer configuration file, refer to Enabling the Properties File as the Keytab Source.
- Pipeline configuration
When a pipeline uses the pipeline configuration as the keytab source, you define a specific Kerberos keytab file and principal to use for the pipeline and store the keytab file on the machine where Transformer is installed. In the pipeline properties, you then define the absolute path to the keytab file and the Kerberos principal to use for that key.
Default Behavior
When using a keytab, Transformer uses the Kerberos principal to launch the Spark application and to access files in the Hadoop system. Note: Transformer ignores the Hadoop user defined in the pipeline properties.
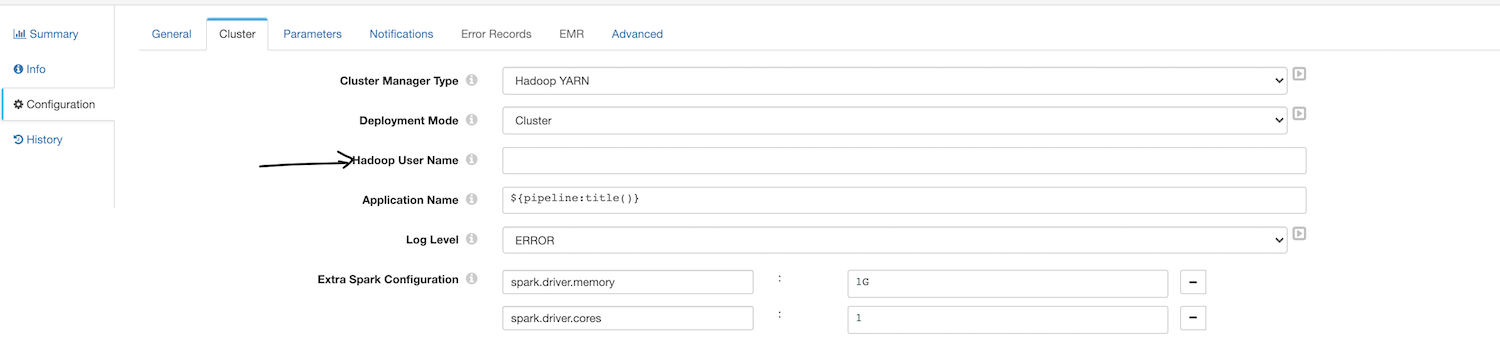
So now we know the default behavior and how to run a Transformer job as the logged in user — for example, rishi. And our end goal is that we want to run this job as a this user. For that, here are the changes we need to make:
- Enable the hadoop.always.impersonate.current.user property in the Transformer configuration file $TRANSFORMER_DIST/etc/transformer.properties.
- Before pipelines can use proxy users with Kerberos authentication, you must install the required Kerberos client packages on the Transformer machine and then configure the environment variables used by the K5start program.
Note: Spark recommends using a Kerberos principal and keytab rather than a proxy user. To require that pipelines be configured with a Kerberos principal and keytab, do not enable proxy users.
Let’s follow these steps:
- Install the following Kerberos client packages on the linux server where Transformer is installed:
- krb5-workstation
- krb5-client
- K5start, also known as kstart
#Add the epel repo to yum $ yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-6.noarch.rpm $ yum install kstart.x86_64
- Copy the keytab file that contains the credentials for the Kerberos principal on to the Transformer machine.
- Add the following environment variables to the Transformer environment configuration file. Note: Modify environment variables using the method required by your installation type.
| Environment Variable | Description |
| TRANSFORMER_K5START_CMD | Absolute path to the K5start program on the Transformer machine. |
| TRANSFORMER_K5START_KEYTAB | Absolute path and name of the Kerberos keytab file copied to the Transformer machine. |
| TRANSFORMER_K5START_PRINCIPAL | Kerberos principal to use. Enter a service principal. |

- Restart Transformer
Let’s Verify
Now that we have made all the necessary configuration updates and restarted Transformer, let’s make sure that the changes will take effect. To do that, follow these simple steps.
- Login with your desired proxy user in Transformer
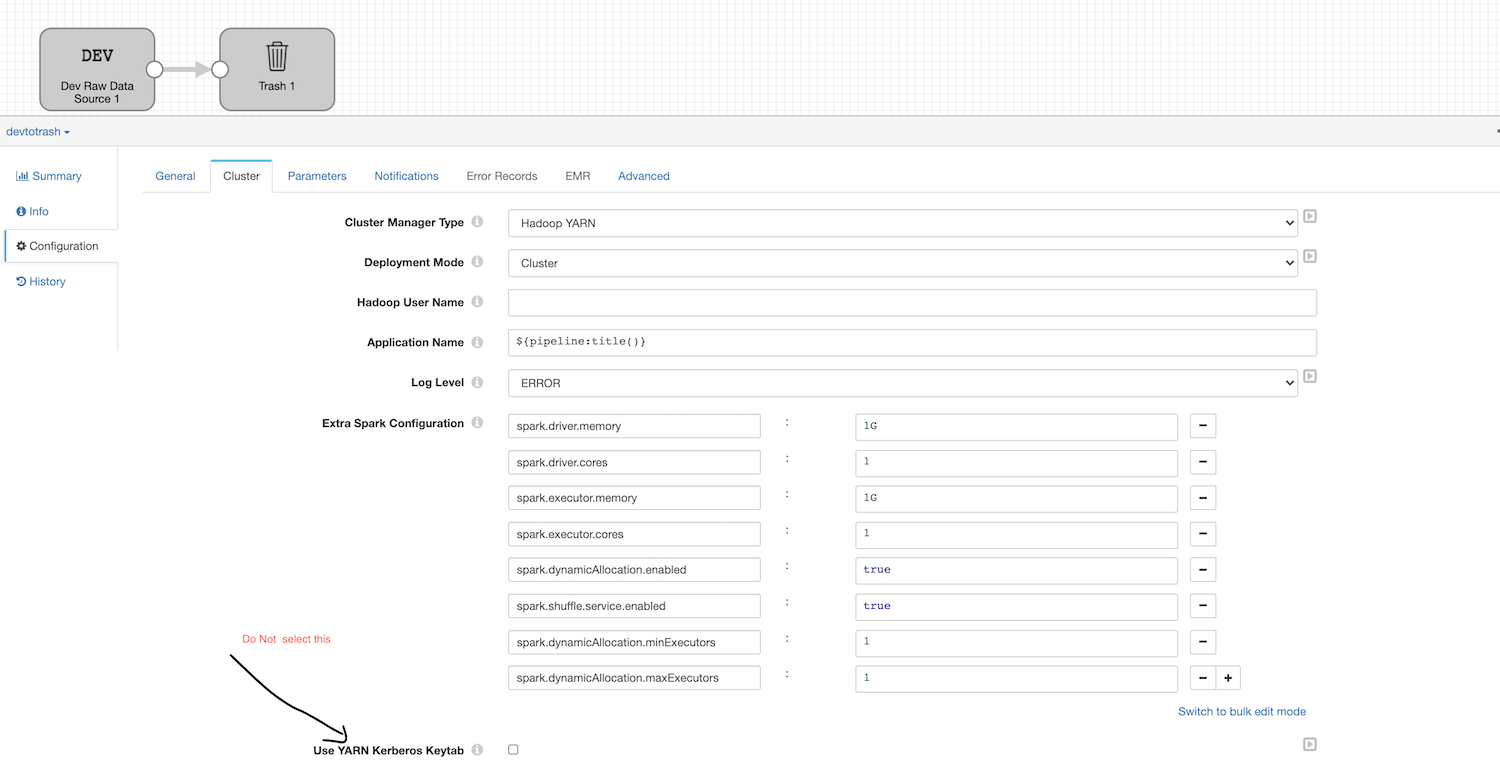
- Create a simple test pipeline. For example, Origin: Dev Raw Data Source and Destination: Trash
- Change Cluster Manager Type to Hadoop YARN
- Leave all the default settings and make sure Use YARN Kerberos Keytab in unchecked as highlighted below.
- Run the pipeline and check the corresponding job in YARN — you should see that that the job was submitted as your proxy user
That’s it!
Try It For Yourself!
In this blog post, you learned the recommended way of enabling and using kerberos authentication when running StreamSets Transformer, a modern transformation engine, on Hadoop clusters.
If you’d like to try it out for yourself, get started today by deploying it in your favorite cloud.