Salesforce Data Pipelines is a Salesforce add-on that allows users to enrich and transform Salesforce data without taking it outside of Salesforce. It requires a separate fee and has limitations around scale, concurrency, and the maximum amount of recipes or pipelines. The only endpoint available is back into Salesforce, so the enriched data cannot be used by other analytics systems or teams who do not have access to Salesforce.
If your organization has a use case that exceeds these limitations, this Salesforce add-on may not be sufficient for your organization’s needs.
Limits of Salesforce Data Pipelines
Exploring these limits may offer clarity when deciding when and if the Salesforce Data Pipeline add-on works for you. Salesforce documentation does a more thorough job of describing these limits than we will here. But, in broad strokes, as of the date of this publication, the limits to scale, concurrency, and maximum amount of pipelines seem to have the greatest impact. In terms of scale, there are limits to fields, objects, and rows. While these limits are generous, they exist, so processing large or frequently accessed data might not suit this add-on. By default, concurrency is set to 1, but up to 2 can be added. Finally, the maximum number of pipelines, or recipes, allowed by default is 20. More can be purchased.
The Hard Way To Enhance Your Salesforce Data Pipelines
Of course, data pipelines in and out of Salesforce can be configured and managed by hand with code. One example of this kind of integration could be a series of Python scripts developed to retrieve data from Salesforce and bring it into a centralized database, which can be transformed and then delivered back into Salesforce or to other platforms or data storage. Orchestration and management, in this case, could be managed using Airflow or some other orchestration tool. The main barrier to this type of integration is scalability. As this type of infrastructure grows, more and more experienced developers are required to maintain and scale.
4 Design Patterns To Level Up Salesforce Pipelines With StreamSets
An alternative to both the Salesforce Data Pipeline add-on and hand coding is data integration with StreamSets. SteamSets is a low-code platform that allows users to build and manage pipelines with a visual interface. This means that the power to scale is given back to the teams and people that understand the data the most, even if they aren’t the most experienced developers. There are many ways to integrate with Salesforce using StreamSets. Below are some patterns you can explore.
Design Pattern 1: Salesforce Destination – SOAP, Bulk API, or Bulk API 2.0
With StreamSets Salesforce origin/destination, you have the option to enable records to be written via the Salesforce Bulk API, by checking the Use Bulk API button or the SOAP API by leaving the box unchecked. This option is available no matter what the pattern.
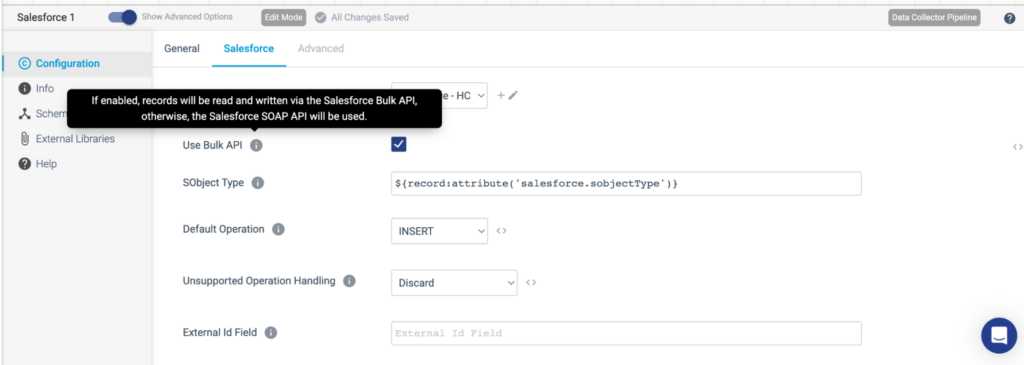
You also have the option to use the destination or origin for Bulk API 2.0. One might choose this option because the Salesforce Bulk API 2.0 origin can use multiple threads to process query result sets in parallel. If you recall, concurrency was a drawback to Salesforce data pipelines. Here, perhaps, is a suitable alternative.
Design Pattern 2: Salesforce CDC Into Snowflake
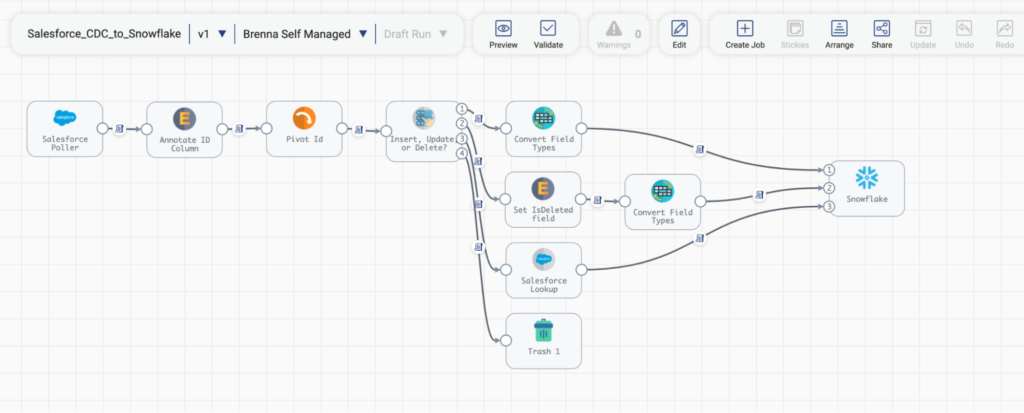
This design pattern takes data from Salesforce, transforms it, and, depending on whether the change detected is an insert, update, or delete, performs additional enrichment before sending it into Snowflake. Now this is a more complicated version of the much simpler pattern of taking data from Salesforce and sending it into Snowflake, which shows the extensibility of both this pattern and StreamSets as a tool.
The critical part of this pattern is the Stream Selector processor, which, as you can see in the screenshot below, is checking for the salesforce.cdc.change type of CREATE, DELETE, or UPDATE. Depending on the outcome of this check, this processor is responsible for funneling records onward for further processing.
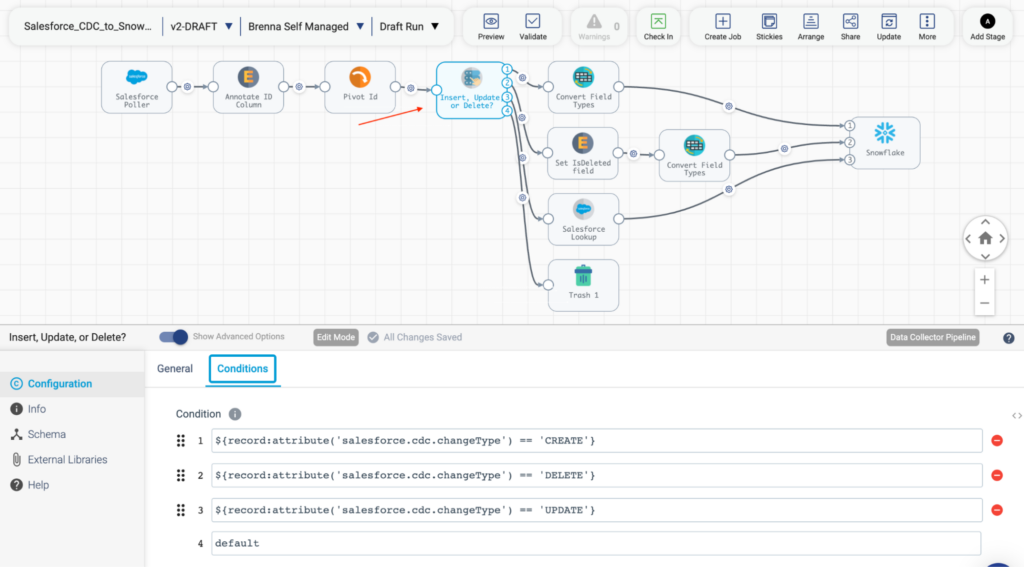
To try this pattern yourself, you can access this sample pipeline here.
Design Pattern 3: Reverse ETL Into Salesforce
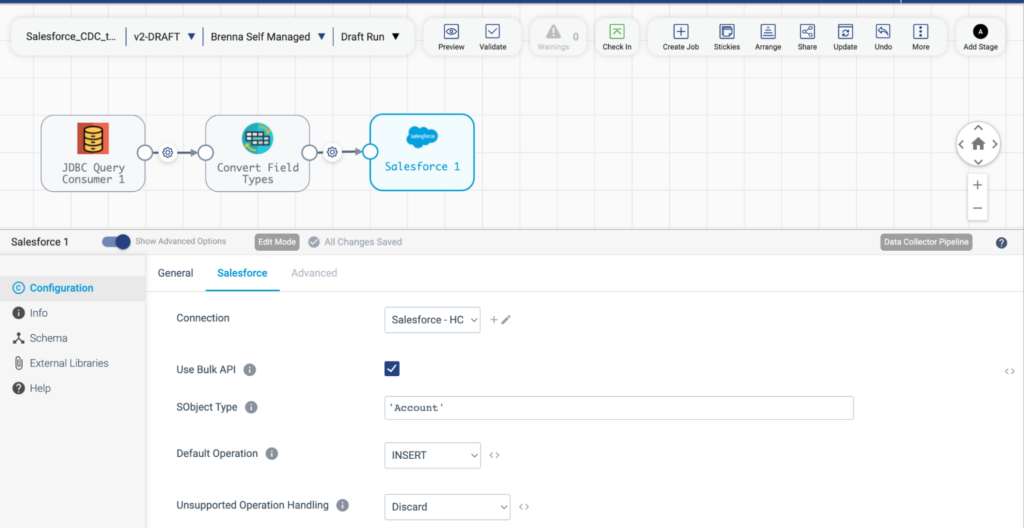
Reverse ETL is a pattern where data is taken from a centralized data store, like a database, and sent back into third-party platforms, in this case, Salesforce. In this reverse ETL pattern, data is taken from a MySQL database, lightly transformed, and sent into Salesforce.
Critical to this pattern is the SObject Type field. This field represents the Salesforce object to be written to and can be literal, such as in this case by indicating ‘Account’ or can be an expression.
The screenshot below also shows one method for storing connection details in a shared environment: Connections. This method allows StreamSets administrators to determine access by user or group, maintaining data governance while allowing resources to be shared.
Design Pattern 4: Salesforce to Salesforce
This pattern is actually the same as Salesforce Data Pipelines: taking data from Salesforce, transforming it, and then sending it back into Salesforce. The difference is that this is the only pattern available with the Data Pipelines add-on, whereas with StreamSets, many more are possible.
One element of this pattern worth highlighting is how the Salesforce origin accepts SOQL Queries. This syntax should be very familiar to Salesforce users and could make the transition from Salesforce native tools easier. Take a look at the below screenshot for a preview of how StreamSets handles SOQL for Salesforce to Salesforce pipelines.
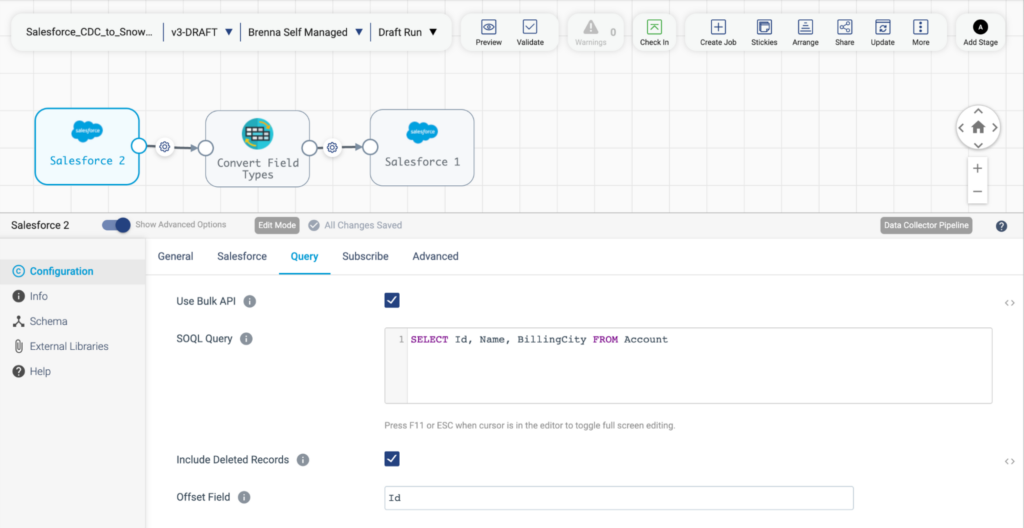
Design Pattern 5: Salesforce to a Database
Finally, this pattern delivers data from Salesforce into a MySQL database. Our JDBC Producer destination allows connection to any database that accepts a JDBC connection string. In this case, the JDBC connection is being used to connect to MySQL. This whitelisted approach to connections allows users the flexibility to connect to a broad range of data sources without waiting for specific branded connections to be developed. You can get started today with the tools you need already at your fingertips.
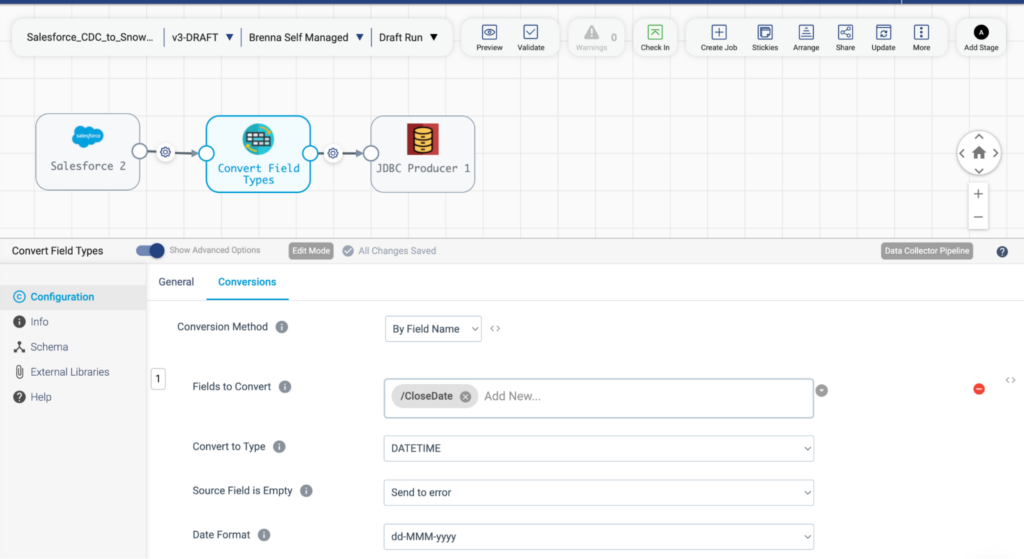
Another interesting element in this pattern is the transformation step. This field-type convertor takes a string called CloseDate and converts it to a DATETIME data type with a simple drop-down menu. Dates and times can be especially fiddly elements in data engineering, but with StreamSets, it’s just a drop-down menu with straightforward options.
Building Beyond the Pattern
You’ll have noticed threaded through all these design patterns are repeatable and familiar elements that are purposefully engineered to be easily understood. The visual backdrop for all these patterns is the same on purpose. No matter what pattern you use to connect to Salesforce or any other data source, the pipeline canvas is the same. This strategy allows for shorter development times, supports learning, and can help drive businesses forward by making data pipelines easier to build and maintain.
Start exploring these patterns and building on them to process and store Salesforce data. Join us in the community to discuss and expand on these and other pipeline patterns.
