Migrating your data workloads to AWS without redesign headaches — urban developer lore or critical capability for modern enterprises? In this blog we will investigate by building a data pipeline to Google Cloud Platform and then migrating the workload to AWS.
Moving clouds may sound like moving mountains. But your ability to move data quickly and reliably between clouds ensures you have the flexibility you need to provide business continuity. So can it be done? And at what cost? If you are using smart data pipelines for your data integration, this daunting task can be easy and practical — no re-writes required.
StreamSets Data Collector, a fast ingestion engine, enables migrating existing workloads of a data pipeline from one platform to another with just a few clicks.
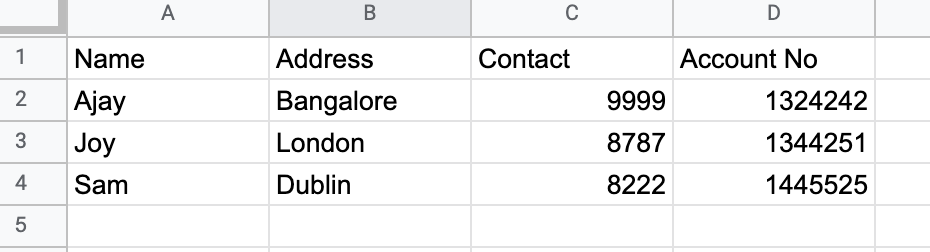
To demonstrate, in this two-part example, we’ll ingest, transform, and store sample bank customers’ data which includes their name, address, contact, and account number using two data pipelines
Pipeline #1: Google Cloud Storage Data Pipeline
In this data pipeline, here are the steps we will follow:
- Read the bank data (in the Excel format) from the Directory origin
- Change the data type of the Account number to STRING from Decimal by using the Field Type Converter
- Transform (mask) the Account No. due to security concerns
- Write to the Google Cloud Storage destination
Sample Data
Data Ingestion
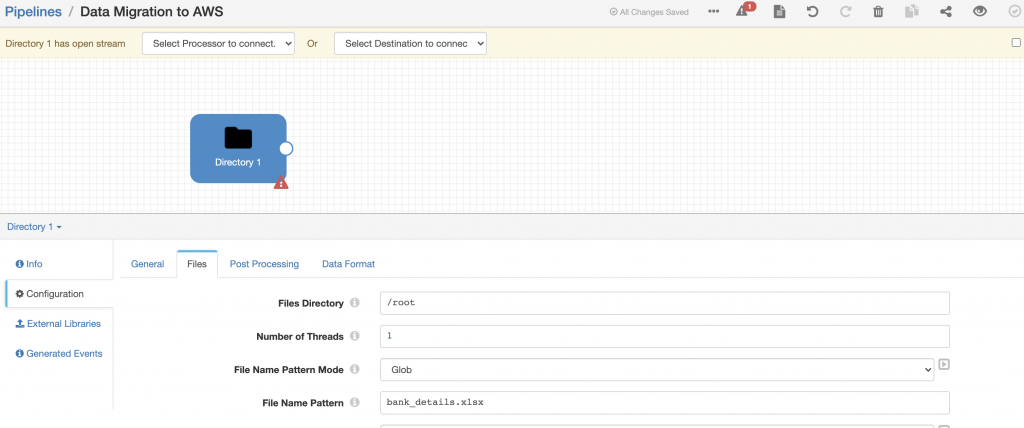
I created a new pipeline and added Directory origin. The key piece of configuration here is the Bank details file location, which we want to process, and the Data Format. In my case, the file location was /root/bank_details.xlsx and Data Format is Excel, but you’ll need to change this to match your location and Data Format.
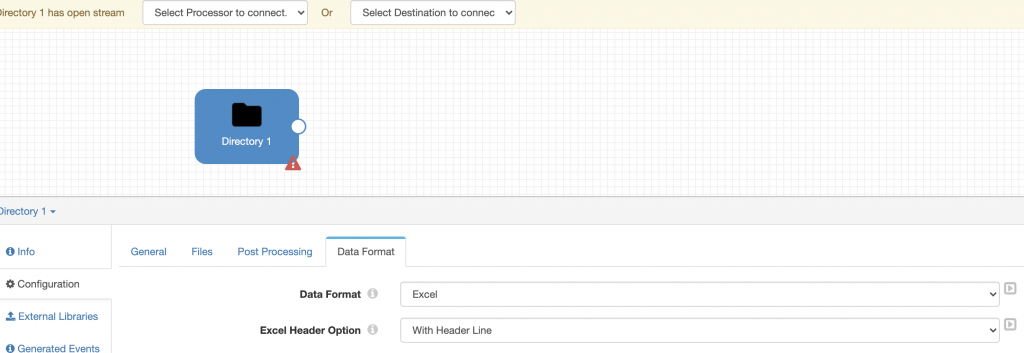
I used the default values for the remainder of the Directory origin – refer to the documentation for more information.
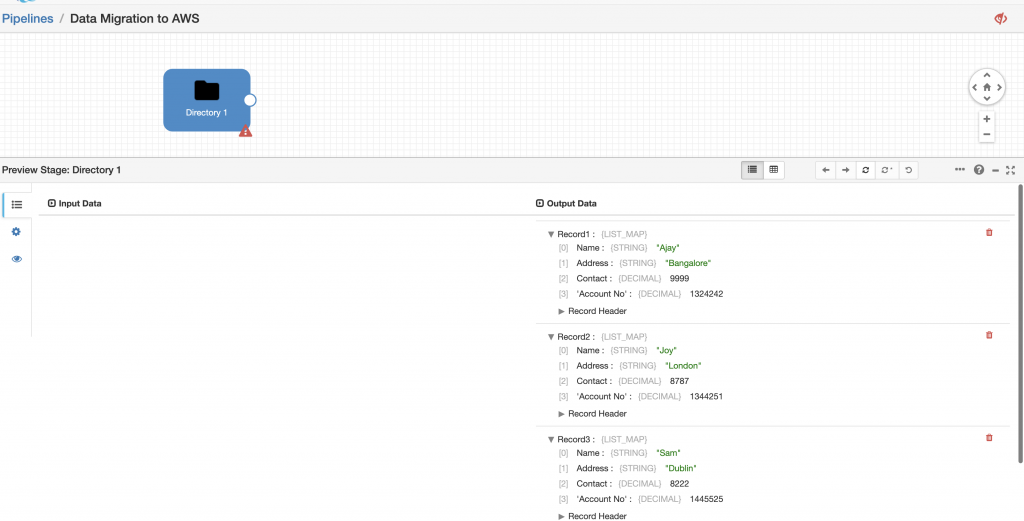
With the origin configured, I was able to preview data. I checked ‘Show Record/Field Header’ in Preview Configuration so I can examine the data as well as the record attributes as shown below.
Data Transformation
While loading data from origin to destination we often want to change some important information due to security concerns. Looking at the bank details, it has a column for Account No. with Data Type of Decimal. I don’t want this as DECIMAL; I want this as STRING and I want to mask the Account number with xxxx56 (I want to share only the last 2 digits).
I changed the Data Format using the Field Type converter. The key piece of configuration here is the Required Fields, which we want to change, so I gave the Account No.
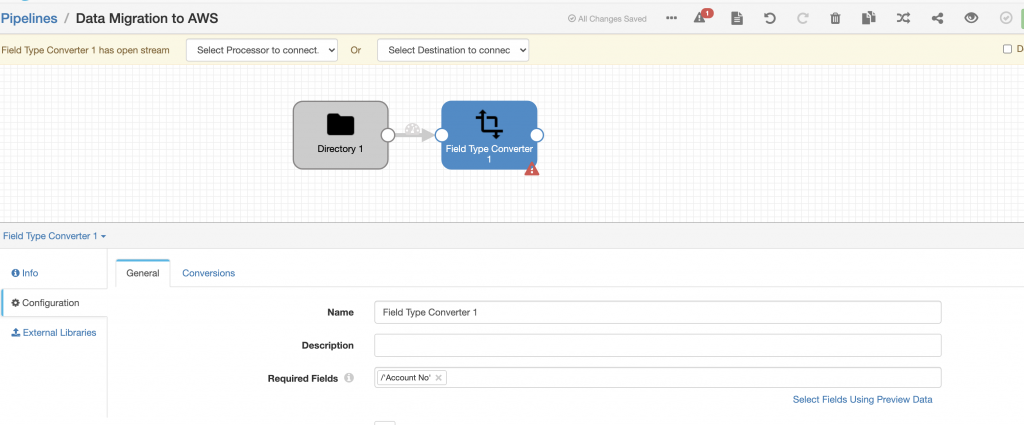
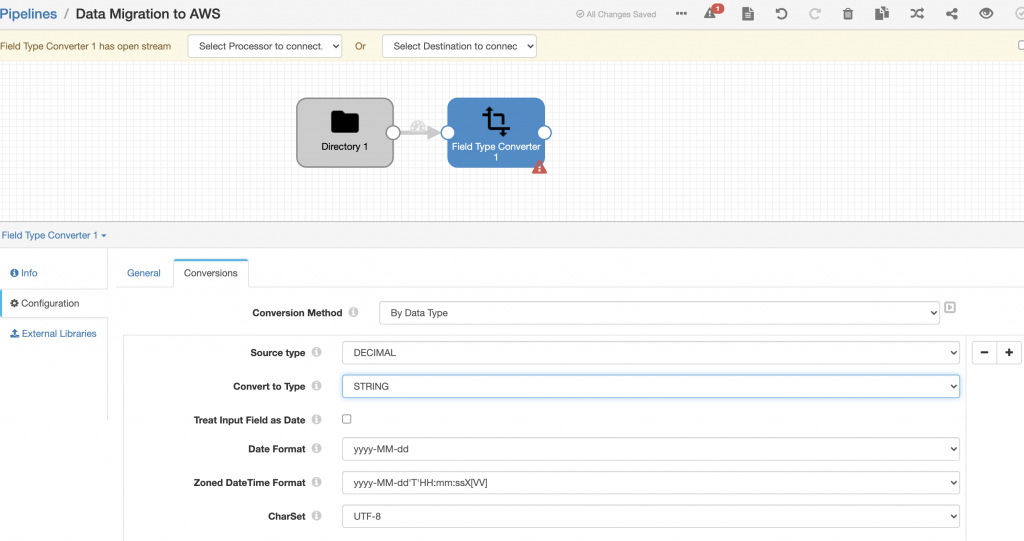
And then updated the conversion tab followed by the conversion method, source type, and convert to type.
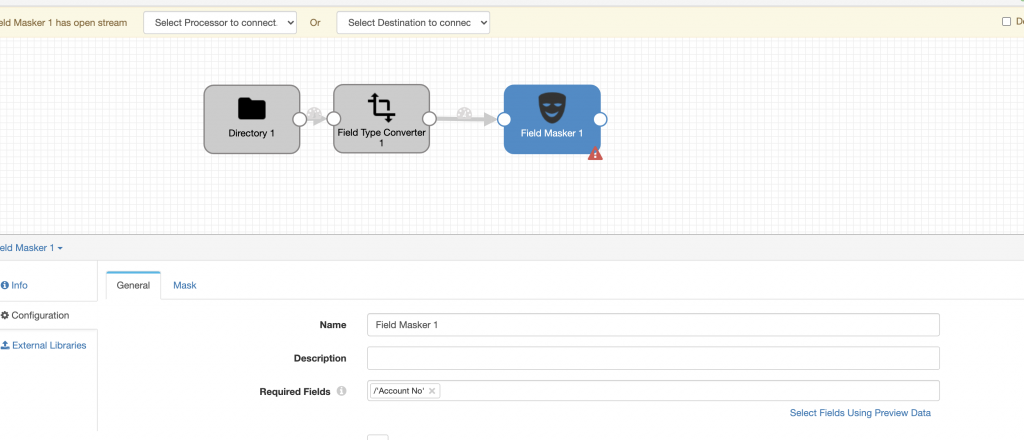
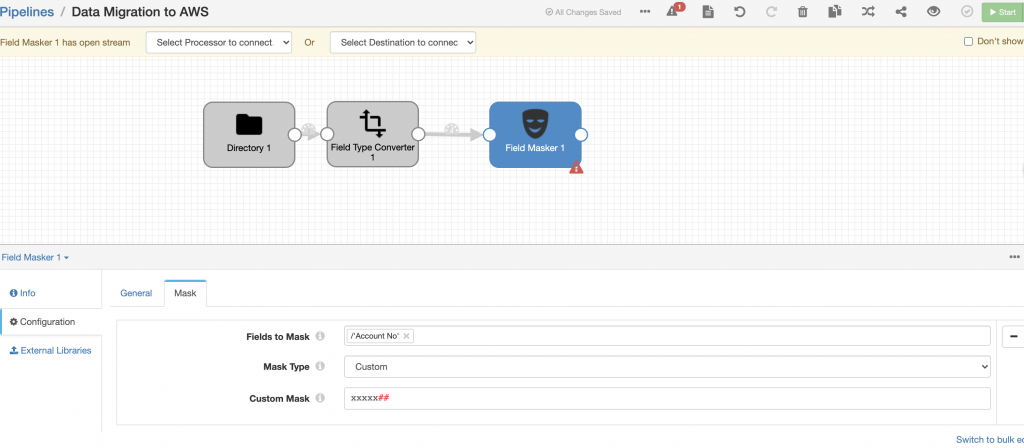
Then I used a Field Masker processor to mask the account number by setting the Required Field on the General tab and setting Field to Mask, Mask Type, and Custom Mask as shown below.
I then added Google Cloud Storage as a destination where I want to write the transformed data. The key piece of configuration here is the GCS bucket, data format, and Credentials. I updated the GCS tab with the name of the Bucket and the Common Prefix. On the Data Format tab, I selected Delimited with the header line.
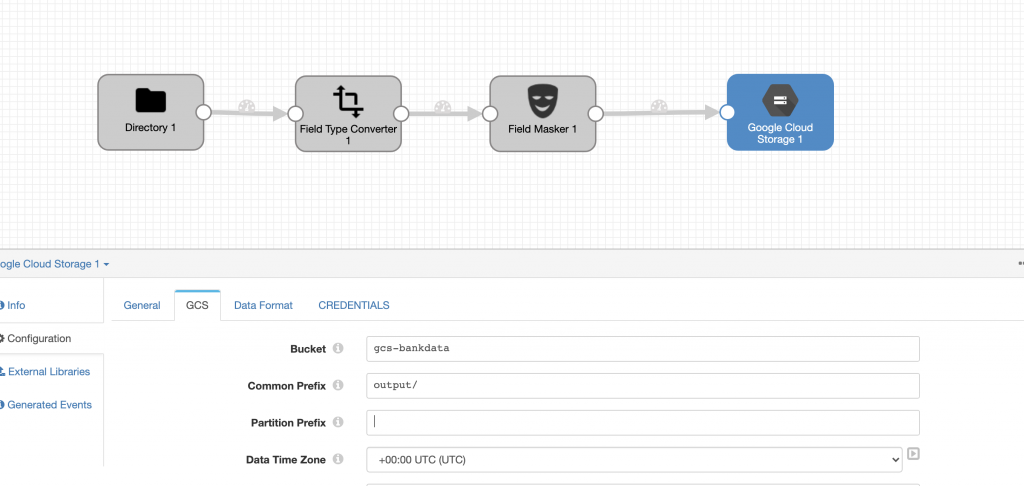
On the Credentials tab I entered the Project ID and provided my credentials.
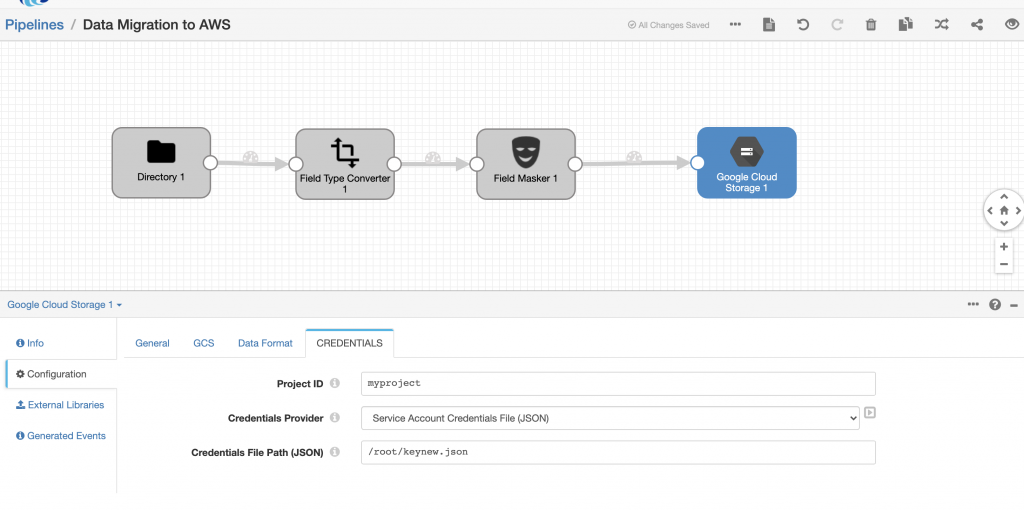
I used the default values for the rest of the GCS destination configuration – see the documentation for more information.
Pipeline Execution
Once my pipeline was configured, I was able to run it and see the data flow through the pipeline.
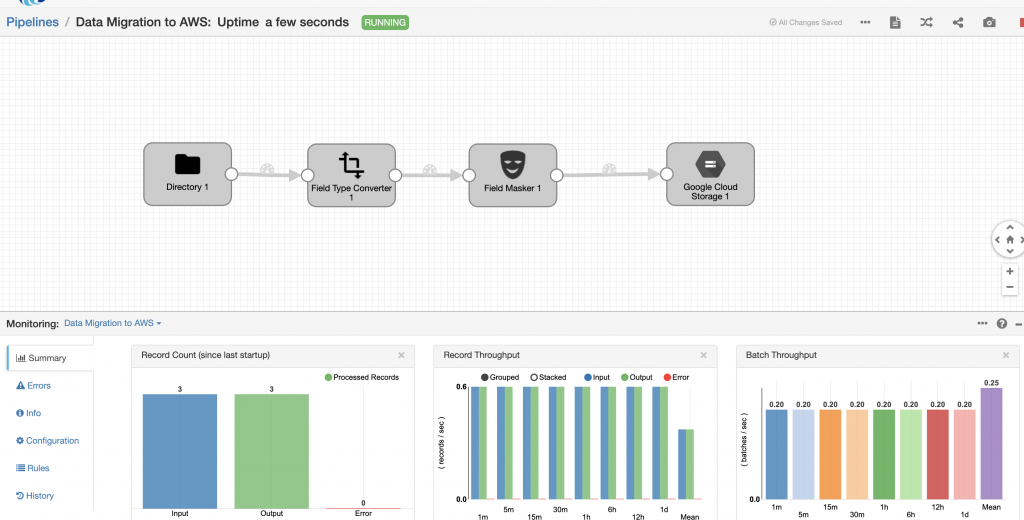
I confirmed that all the data had been ingested by examining the Google Cloud Storage bucket and downloading the file to verify the contents.
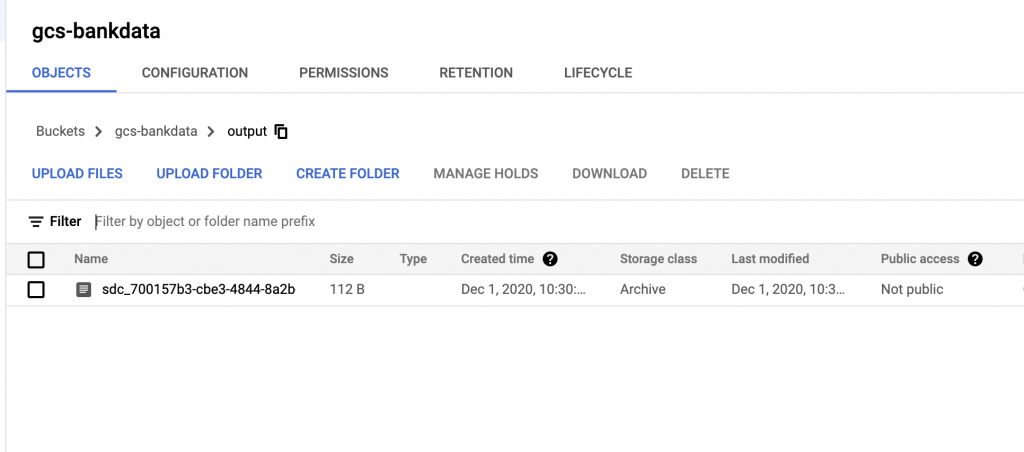
$ cat output_sdc_700157b3-cbe3-4844-8a2b-77d0e3f86ae5
Name,Address,Contact,Account No
Ajay,Bangalore,9999,xxxxx42
Joy,London,8787,xxxxx51
Sam,Dublin,8222,xxxxx25
Pipeline #2: Migrate Existing Workload to AWS S3
Now what if we wanted to migrate the workload to AWS instead of GCS? Do you think we’d have to rewrite everything and start from scratch? Well, thankfully the answer is no! All we would have to do is delete the GCS destination and add Amazon S3 destination — all with a few clicks in the UI.
Then the only thing remaining would be to configure the Amazon S3 destination as shown below.
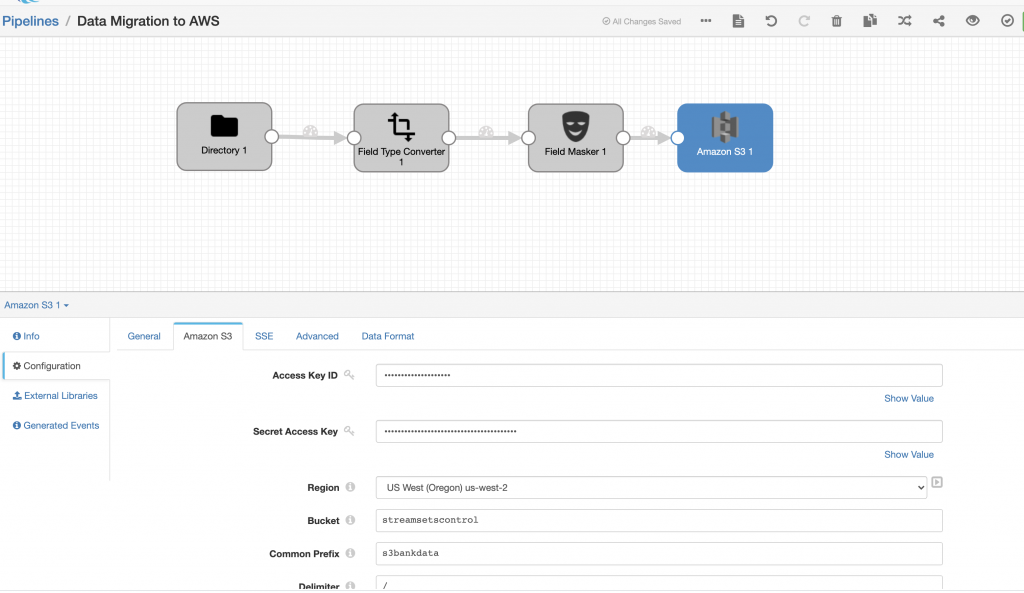
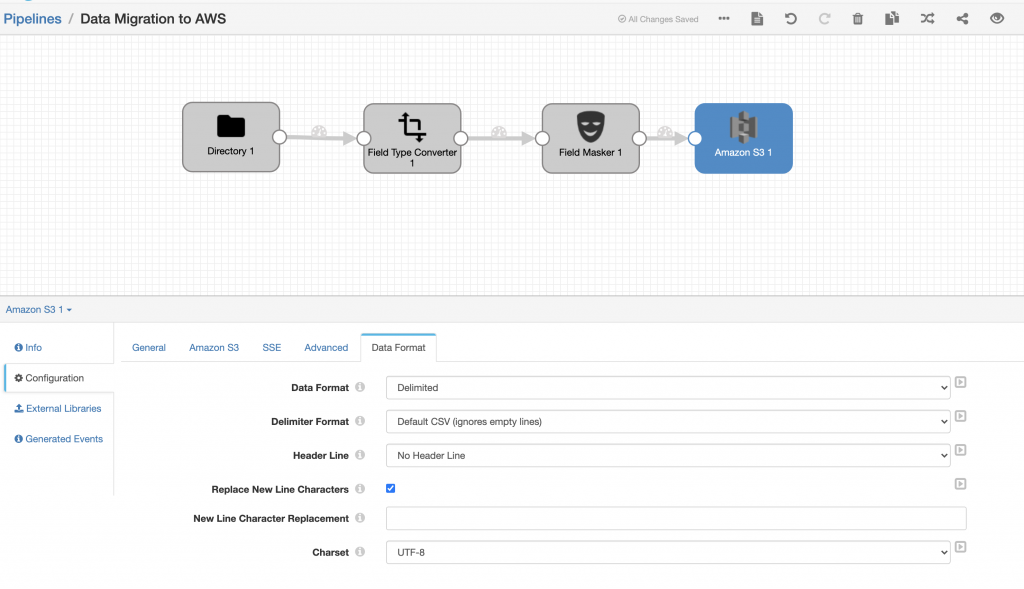
Once my pipeline was configured with the new AWS destination, I was able to run it and see the data flowing through into Amazon S3.
Pipeline Execution
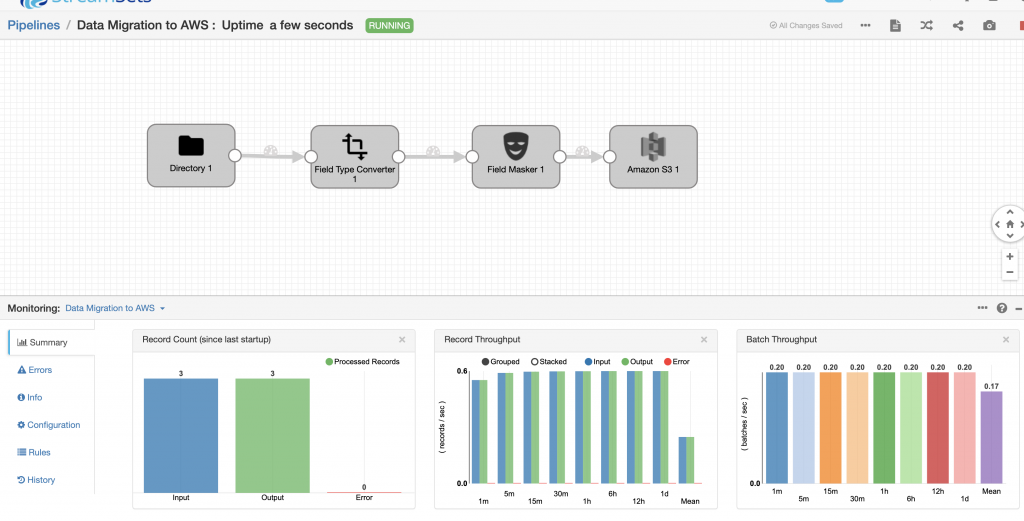
I confirmed that all the data had been ingested into AWS by downloading the output file from the Amazon S3 file and examining its contents.
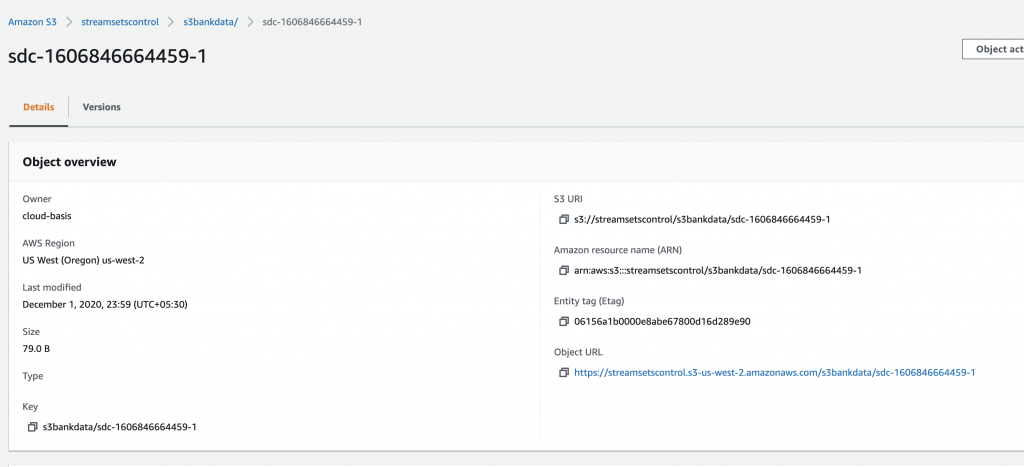
$ cat sdc-1606846664459-1
Name,Address,Contact,Account No
Ajay,Bangalore,9999,xxxxx42
Joy,London,8787,xxxxx51
Sam,Dublin,8222,xxxxx25
Busted: Migrating Workloads to AWS Does NOT Require Data Pipeline Re-writes
So that busts the myth that migrating workloads to AWS requires a data pipeline re-write. We built a data pipeline framework to ingest, transform, and store sample bank customers’ data on GCP and then validated that migrating workloads to AWS can be done without a pipeline redesign when you use smart data pipelines. You can transform data and then move those results between cloud platforms as your workload dictates. This means that data engineers can focus on building the pipeline that best fits the data without worrying about the implementation details.