This article is the first part of a three-part series, Conducting the Chaos of Data Drift. StreamSets’ automated drift detection, a piece of it’s patented Data Drift technology, allows users to reduce break-fix time by 90%.
In this first part of the series, we will be covering explicitly data drift as it pertains to files being pushed into Snowflake or other. This may seem trivial but as a lot of us know this is by far the most painful at a human, day-to-day level.
We’ll begin with a familiar story…
Your morning starts off so innocently. You’re in the groove and ready to tackle the day. You sign into your email and see a new request for a data extract. A new Amazon S3 Bucket has been created and files will be pushed there at various times every day. These files will be coming from multiple business units and will contain what looks to be standard updates.
The attachment in the email contains the file format for these files. A simple CSV format; so simple you think to yourself, “I can get this knocked out and start running tests before I finish my first cup of coffee”. And you do. You run the load, have the proper people on your team validate that the data was loaded correctly and, before you know it, your job is in production.
Just another job in your rear view and you’re off to bigger, more interesting projects. Or, at least that’s what you hoped for.
But, it never fails.
Somehow, some way, someone upstream makes an update to the application that’s generating those files and alarm bells start going off at all kinds of hours. Oh boy, data drift.
Where’s drift detection when you need it?
The next thing you know it’s 3AM and you’re online trying to debug what exactly happened.
For anyone that has had to carry a pager, the scenario you’re now in is unfortunately similar to how life once was. (For those of you who didn’t, lucky you, because it was just as bad as it sounds).
Finally, you get to one of the files that was being processed and there it is as clear as day. The columns are out of order, or even more unfortunately, someone has added additional columns.
Now the real fun begins…
Wouldn’t it be great if this was all just a bad dream? And instead, in reality, you’re processing those files and sending them downstream to Snowflake while you sleep with StreamSets, which has patented the ability to handle Data Drift, so your application just keeps on running… like nothing ever happened. Thank you world for automated drift detection.
So, how do you go about using this mystical magic that allows someone upstream to fiddle with the files without disrupting your slumber or binge watching?
This “magic” is already baked into the DNA of StreamSets. So, you no longer have to worry about the “I cannot guarantee the format” answer you get when asking the sender why this happened. Automated drift detection has you covered.
However, you do still need to configure your pipeline to make sure the data that you want, in the order that you want, ends up in the target, Snowflake for example, how you want. So, let’s get to it.
Want access to this pipeline and dataset? You can find them here on GitHub. And if you’d like to follow along, sign up for our free trial of StreamSets.
Building Your Pipeline with Automated Drift Detection
Let’s first take a look first at the completed pipeline. We’ll work our way from left to right. In this sample pipeline, I am utilizing the StreamSets Data Collector Engine to process these files from my source into my Snowflake Data Cloud.

First thing I need to do is use one of the following Origins out of the 60+ StreamSets offers today:
- Directory
- Amazon S3
- Google Cloud Storage
- Azure Data Lake Storage Gen 2
- SFTP / FTP / FTPS
For the purpose of this blog, I am using Directory to work with files locally.
Before we dive in, let’s take a quick look at the starting file structure and the current file structure after one of our fellow humans made the format change.
Starting File Structure
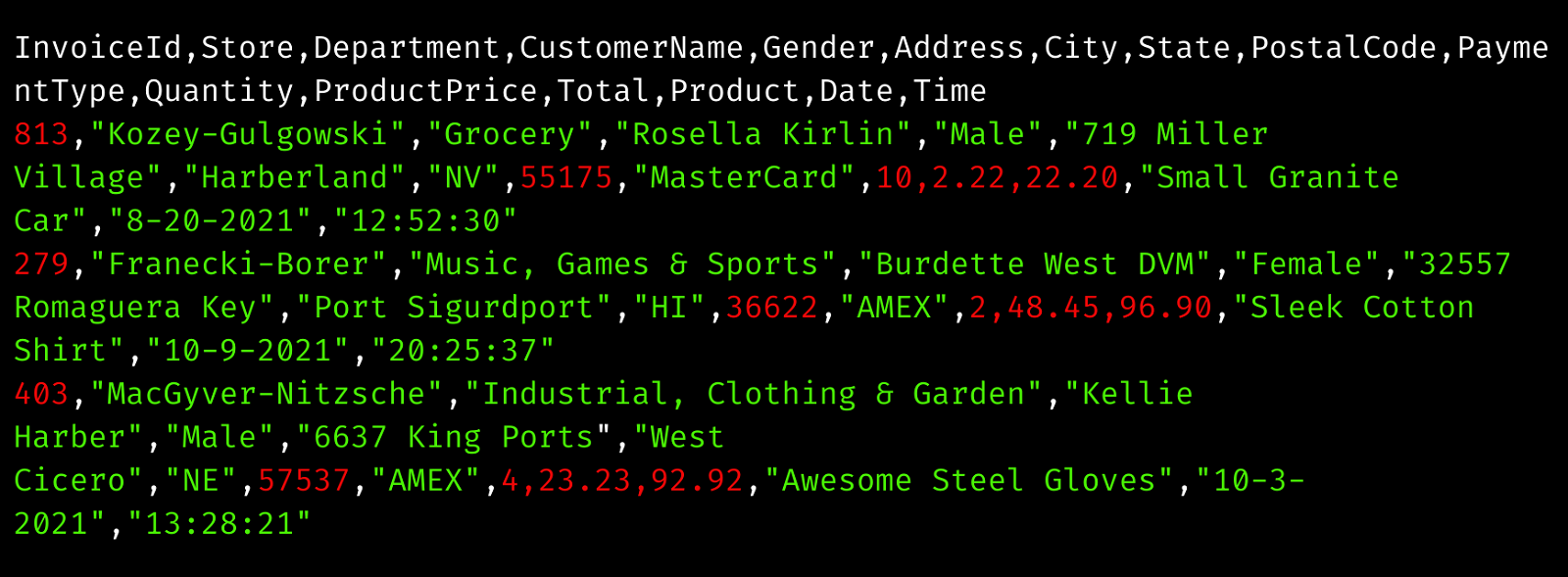
Current File Structure
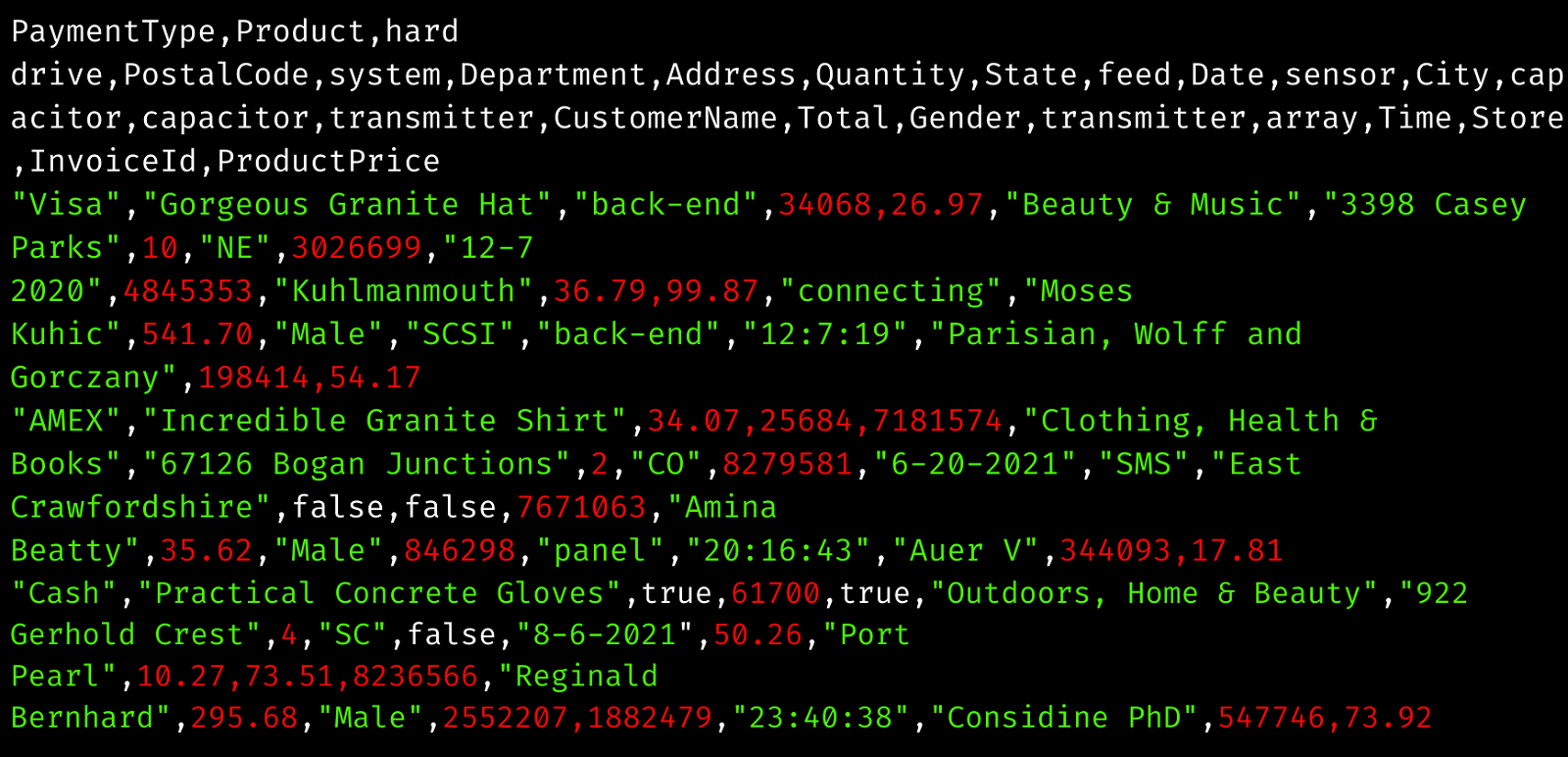
Now, let’s do this.
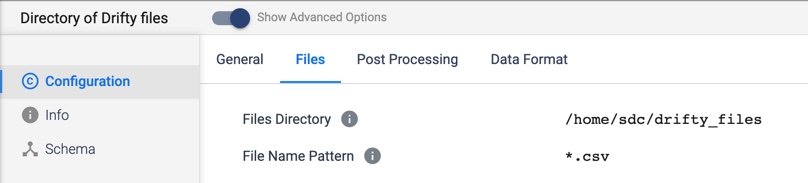
Directory (Origin Settings)
Files:
- Files Directory: The path to the root directory where your files will be stored
- File Name Pattern: Wildcard ‘*.csv’ so I grab every existing file that’s in the directory and any future files written at a later point in time.
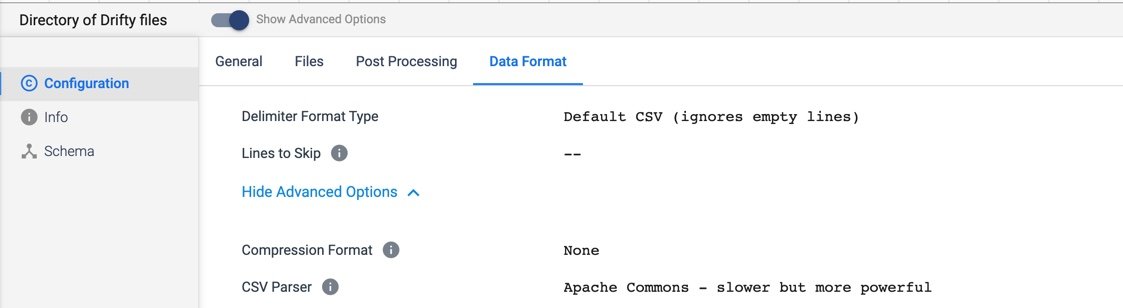
Data Format:
- Delimiter Format Type: Default CSV
- CSV Parser: Apache Commons (You could choose Univocity but I just selected the default)
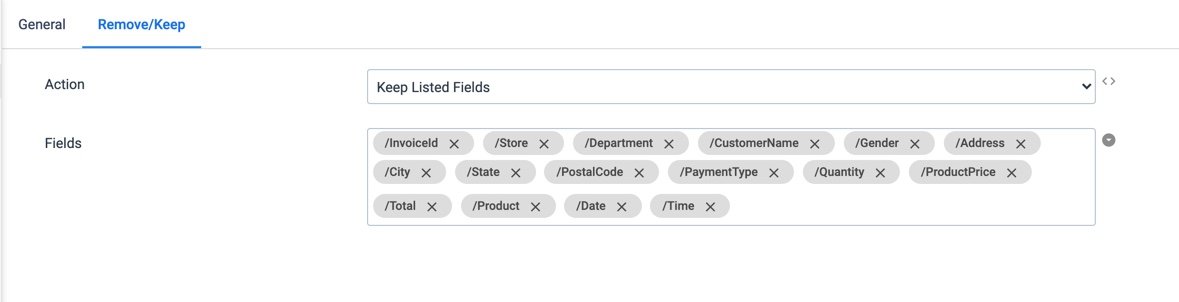
FieldRemover (Processor Settings): Keep Core Fields
StreamSets’ Field Remover processor is very powerful. In this pipeline, I am telling it what fields I want to process, meaning all others will be ignored.
With this configuration, if your source files come in with additional columns that may or may not be consistent between file generation, it doesn’t matter. Those added fields won’t make their way into your target nor into other downstream processors.
Here is a quick look at some of the features of Field Remover:
- Keep the listed fields and remove all other fields (this is the route I took)
- Remove the listed fields
- Remove any listed field that has a particular value:
- Null
- Empty string
- Specified constant

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
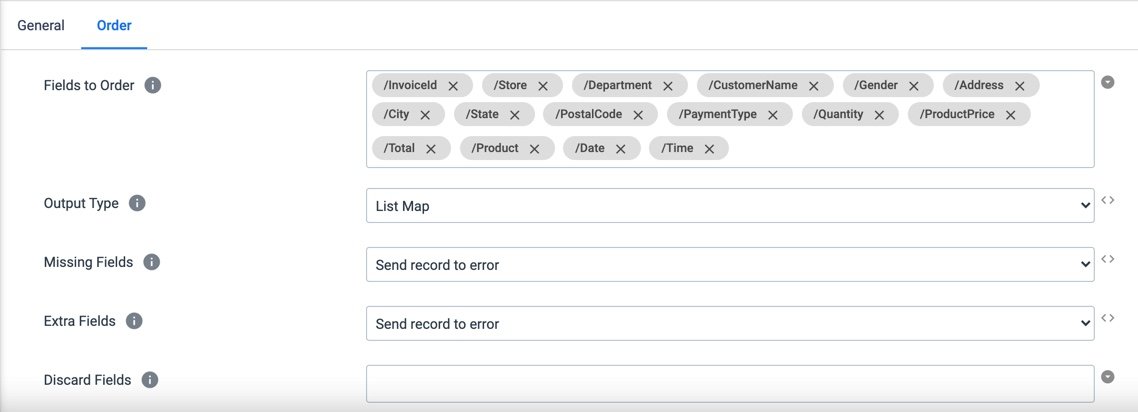
FieldOrder (Processor Settings): Order for Table
The Field Order processor allows you to tell the pipeline the order in which you want the fields to be processed downstream, in our case to Snowflake.
- Fields to Order: The fields can either be manually entered or you can pick them from the list once you run the Preview.
- Missing Fields: By default, StreamSets will Send record to error. Another option is to add a Default Value.
- Extra Fields: By default, StreamSets will Send record to error. Or, you can choose to Discard.
Note: If you do not need the auto-creation functionality I walked through above and do not have a preference of your tables being created in a certain order at your destination, StreamSets DataOps Platform does have the ability to handle Semantic Drift. In other words, even if the field order changes from file to file, it won’t affect the logic or flow of your pipeline to your destination.
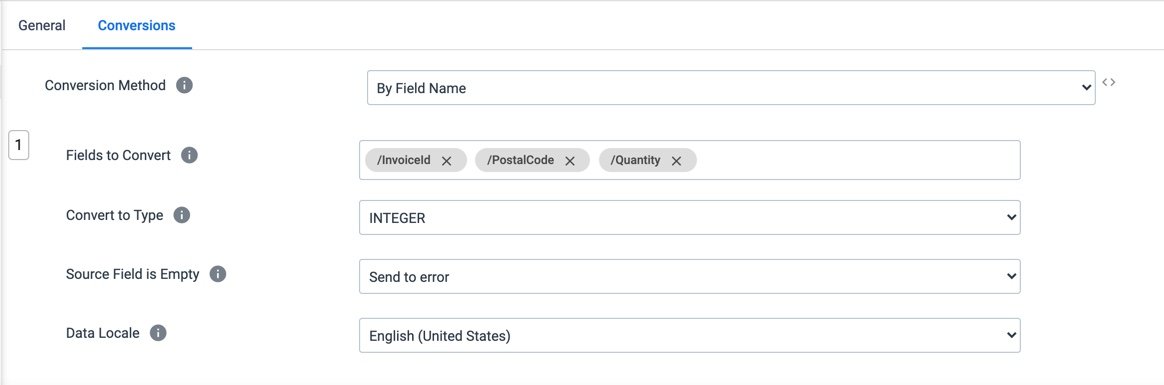
FieldTypeConverter (Processor Settings)
The Field Type Converter allows you to convert a single or list of fields to a particular Data Type. You can keep adding more conversions until you have all the fields set to the Data Types and formats you want.
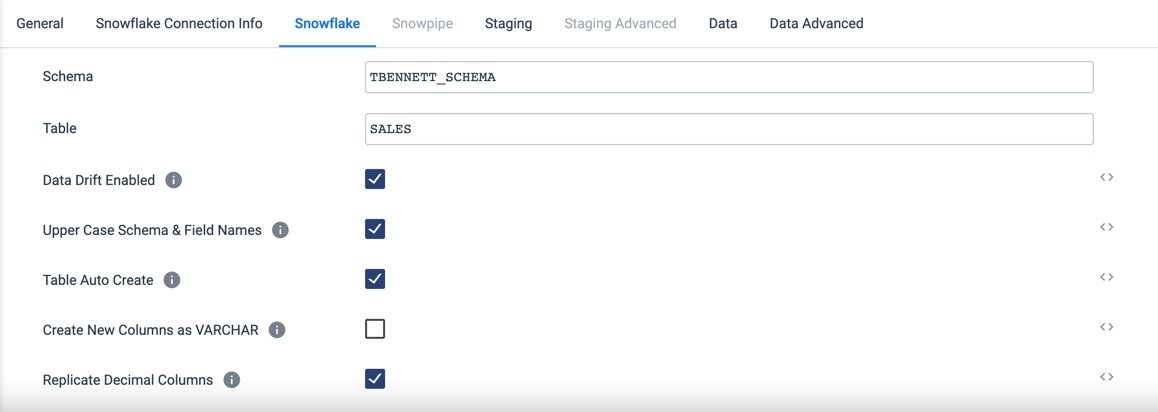
Snowflake (Destination & Drift Detection Settings)
And just like that, we are ready to load our data into Snowflake. I will not go into setting up connections, but I do want to touch base on two properties that you will find very useful. I know these hit home for me.
- Data Drift Enabled: If checked, will enable creating new columns in the table as they appear.
- With Data Drift detection enabled, new data fields can simply show up and the downstream team can decide if they want to utilize them or not. So, as new fields are added, you’ve just eliminated the need to update your job, go back through QA / Stage / Perf environments and then finally re-release into production. With this feature and many others included in StreamSets, our users reduce break-fix time by 90%.
- Table Auto Create: If checked, a Table will be created in the target environment if it does not already exist.
- How many times has a Table Create script been missed in a production deployment and then the job fails… in the middle of the night or heck, maybe even a weekend? Honestly, if I had to answer, I don’t think I could. It’s very frustrating. And we all know the last thing anyone wants to do is send that dreadful email, explaining why this happened and what will be done in the future to ensure it doesn’t happen again.
Data Drift Detection is Required by Modern Data Teams
Working with data is pure chaos these days, and it’s only getting more and more complex. With the consistent shifting of data formats, applications and versions of those applications that are generating data, it’s no wonder companies spend so much time just trying to make sense of it all.
Data is not only becoming more complex, but there is also a massive increase in workload being pushed to data teams. It’s no surprise that data drift detection has become a common practice to provide a massive uplift in efficiency. To put it simply, modern data teams require data drift detection in order to work in a way that meets business demands.
You can bring order to that chaos with StreamSets and its patented Data Drift detection capabilities. These capabilities are not just an afterthought in StreamSets and are instead part of the DNA of our platform.