One of the most exciting new capabilities of StreamSets DataOps Platform is its ability to dynamically provision Public Cloud VMs running Data Collector or Transformer for Spark engines.
Public cloud VMs running StreamSets engines can be deployed “just in time” to run jobs, and can be automatically torn down once those jobs complete. This technique can significantly reduce public cloud infrastructure costs as compared to deploying static, long-running VMs hosting StreamSets engines that are not fully utilized.
This blog post provides a dynamic provisioning example on AWS. We’ll use the StreamSets DataOps Platform SDK for Python to automate the process. This example could easily be ported to run on Azure or GCP with only a few minor changes.
Overview of the Dynamic Engine Deployment Process
Let me start by explaining the dynamic engine deployment process before I go into how you can run a script to implement it. Here’s an overview of what happens:
- A DataOps Platform Amazon EC2 Deployment is created and started. Its configuration specifies a single instance of Data Collector with a custom set of stage libraries and a unique engine Label.
- The process waits until the newly deployed Data Collector instance registers with DataOps Platform with the expected label.
- Once the new engine has registered with DataOps Platform, a job is configured and started. The job is assigned the same label as the engine that was just deployed to cause the job to run on that engine.
- The process waits until the job transitions to an Active Status and then waits for the job to complete.
- Once the job has completed, the process stops and deletes the deployment, which tears down the StreamSets Engine and the EC2 instance.
Monitoring a Dynamic Engine Deployment Process
While a dynamic engine deployment process is running, one can follow its progress in the StreamSets UI. For example, here we can see a deployment has been created and is in an Activating state:

The deployment’s details page provides a link to the underlying AWS Cloud Formation Template that is spinning up the AWS Autoscaling Group and EC2 Instance for the engine:
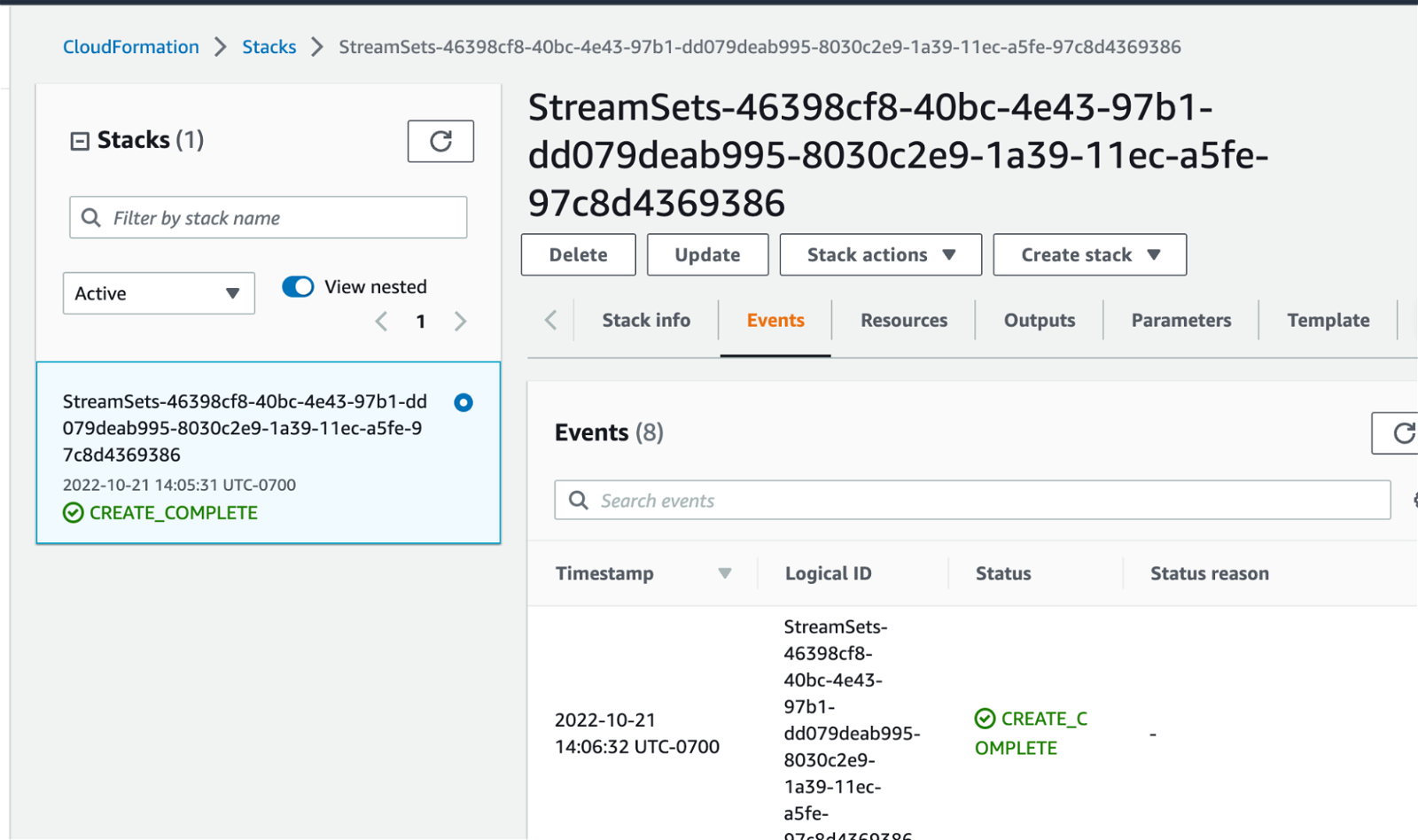
When the AWS deployment is complete, its status in Control Hub will transition to Active:

Shortly after the deployment transitions to an Active state, the engine should register with Control Hub, with the specified label:
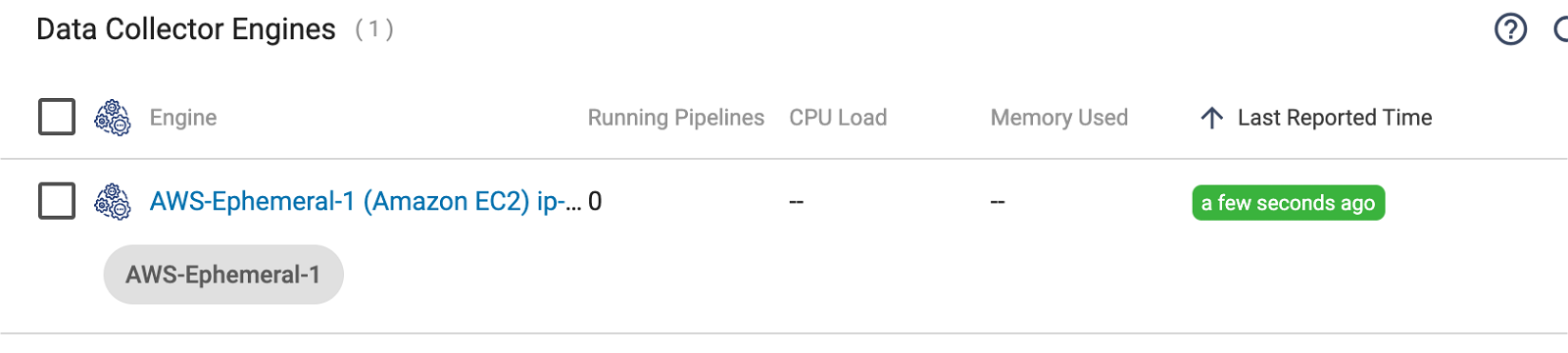 Once the engine has registered, the job should start and transition to an Active state:
Once the engine has registered, the job should start and transition to an Active state:

Once the job completes, the deployment should transition to a Deactivating state:

Once the deployment is in a Deactivated state, the engine will be deleted from the Control Hub’s engine list, and the deployment will be deleted from the Control Hub’s deployment list.
Job History
Job metrics and run history are saved by Control Hub even though the deployment and engine have been deleted:
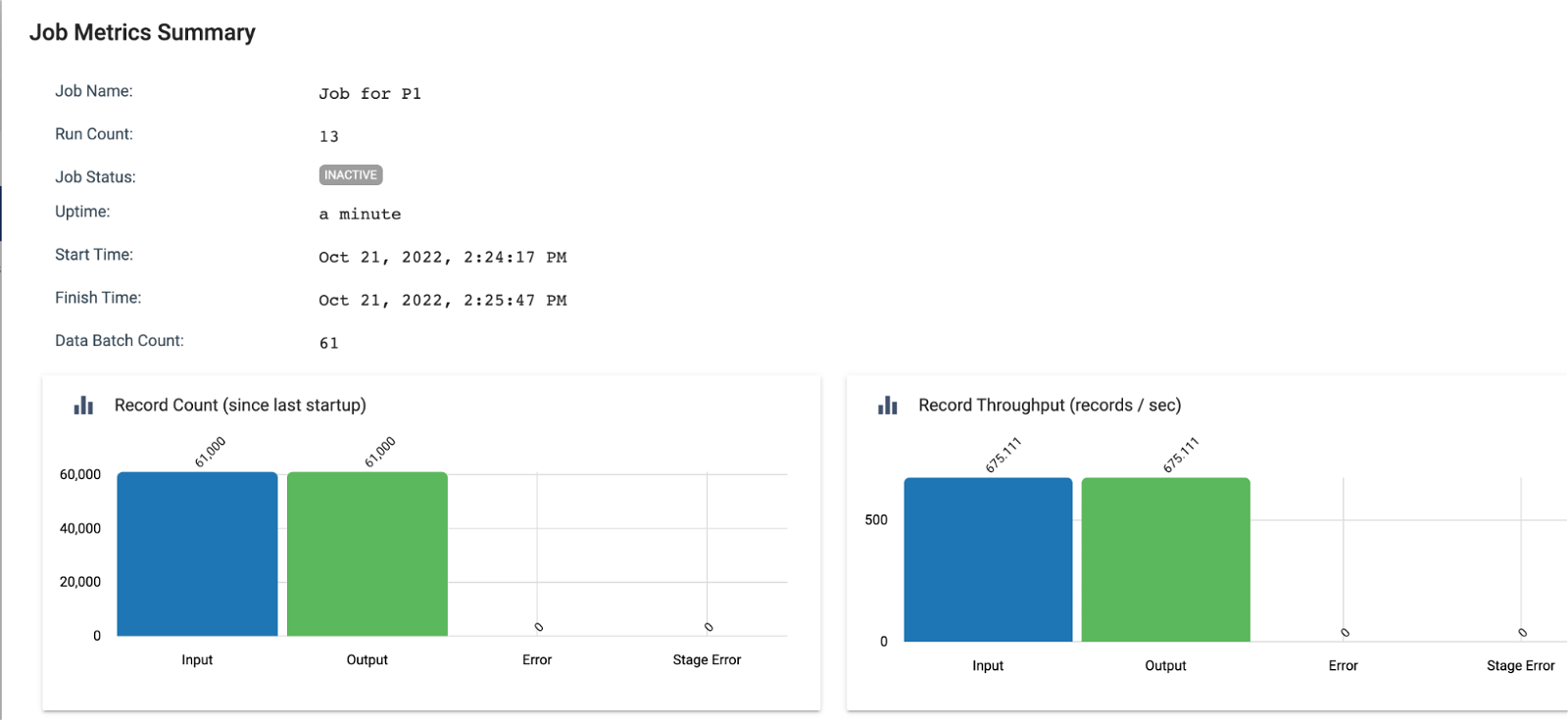
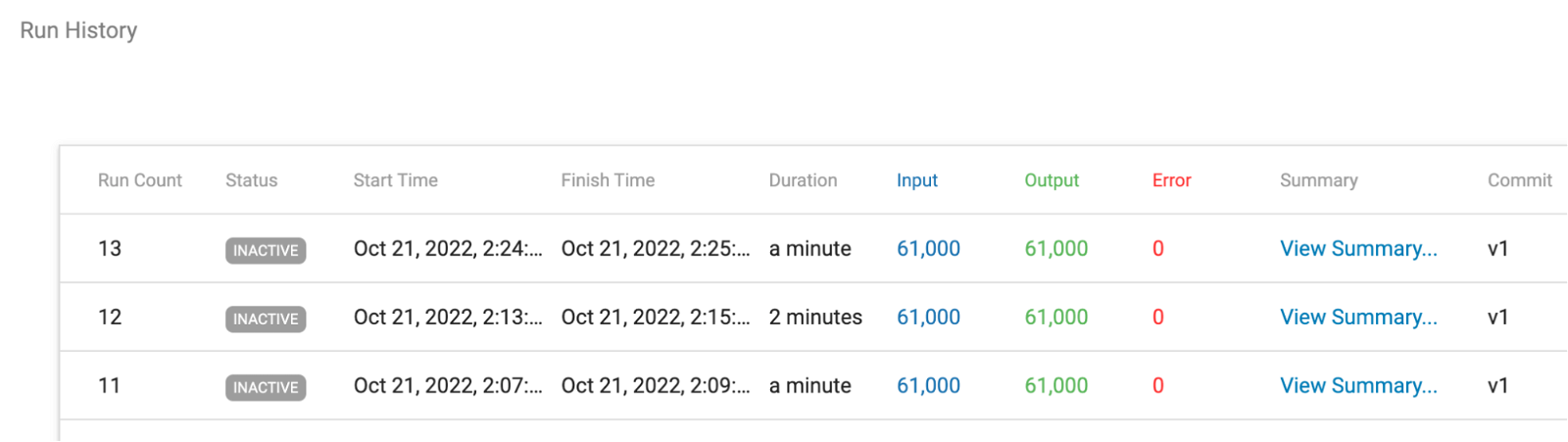
Now, Here’s How You Run the Dynamic Engine Deployment
A Python script that automates all of the steps above using StreamSets SDK is posted here.
Follow the steps below to run the script in your own environment. See the docs here and here for additional details.
Prerequisites
These are the prerequisites required to run the example script:
- A StreamSets DataOps Platform account with API Credentials
- An AWS Environment configured in your DataOps Platform in an Active state.
- Permissions to create and start deployments and to execute jobs
- A Python 3.4 or higher environment to run the script
- The StreamSets DataOps Platform SDK for Python module installed in your Python environment. See the installation instructions here.
- A StreamSets job to run on the engine.
Prepare the Script
Set values for the following variables at the top of the script. I have included some example settings from my own environment. As this is a Python script, string values should be quoted:
# CRED_ID -- Your DataOps Platform API Credential CRED_ID. CRED_ID = '<redacted>' # CRED_TOKEN -- Your DataOps Platform API Credential CRED_TOKEN CRED_TOKEN = '<redacted>' # The ID of the Job to run JOB_ID = '65705324-adc9-4cd2-937f-3f2cf63c7e82:8030c2e9-1a39-11ec-a5fe-97c8d4369386' # A Label that will be used to match the Job to the ephemeral SDC Instance LABEL = 'AWS-Ephemeral-1' # Your AWS Environment name AWS_ENVIRONMENT_NAME = 'aws' # The AWS SSH Key Name to set for the EC2 instances AWS_KEY_NAME = '<redacted>' # AWS Deployment tags AWS_DEPLOYMENT_TAGS = {'owner':'mark'} # The AWS Instance Profile ARN to use for the EC2 instances EC2_INSTANCE_PROFILE = 'arn:aws:iam::501672548510:instance-profile/146-ir' # EC2 Instance Type EC2_INSTANCE_TYPE = 'm4.large' # The number of EC2 Instances to spin up NUM_INSTANCES = 1 # Custom Stage Libs list. Include the stage libs your pipeline needs to run SDC_STAGE_LIBS = ['jython_2_7', 'jdbc'] # How long to wait for the Engine Deployment to complete MAX_WAIT_SECONDS_FOR_ENGINE_DEPLOYMENT = 60 * 5 # example for 5 minutes # Frequency to poll Control Hub for status POLLING_FREQUENCY_SECONDS = 30 # How long to wait for the Job to become Active MAX_WAIT_SECONDS_FOR_JOB_TO_BECOME_ACTIVE = 20 # How long to wait for the Job to complete MAX_WAIT_SECONDS_FOR_JOB_TO_COMPLETE = 60 * 10 # example for 10 minutes
If your job requires input parameter values, set them on line 167 of the script like this:
job.runtime_parameters = {"PARAM_1":"aaa","PARAM_2":"bbb"}
Run the Script
Here is example console output when running the script:
$ ./run-job-on-dynamic-engine-aws.py 2022-10-21 12:51:09 Connecting to Control Hub 2022-10-21 12:51:11 Found AWS environment named 'aws' 2022-10-21 12:51:11 Creating AWS Deployment named 'AWS-Ephemeral-1' 2022-10-21 12:51:12 Adding Stage Libraries to the Deployment: ['jython_2_7', 'jdbc'] 2022-10-21 12:51:13 Starting the AWS Deployment. This may take a couple of minutes... 2022-10-21 12:53:15 Waiting for Engine to register with Control Hub... 2022-10-21 12:53:45 Waiting for Engine to register with Control Hub... 2022-10-21 12:53:45 Engine has registered with Control Hub 2022-10-21 12:53:45 Getting Job with JOB_ID: '65705324-adc9-4cd2-937f-3f2cf63c7e82:8030c2e9-1a39-11ec-a5fe-97c8d4369386' 2022-10-21 12:53:46 Setting the Job's runtime parameters 2022-10-21 12:53:46 Setting the Job's label to 'AWS-Ephemeral-1' 2022-10-21 12:54:02 Starting Job... 2022-10-21 12:54:02 Job status is ACTIVE 2022-10-21 12:54:02 Waiting for Job to complete... 2022-10-21 12:54:02 Waiting for Job to complete... 2022-10-21 12:54:33 Waiting for Job to complete... 2022-10-21 12:55:03 Waiting for Job to complete... 2022-10-21 12:55:33 Waiting for Job to complete... 2022-10-21 12:56:03 Job completed successfully 2022-10-21 12:56:03 Job status is INACTIVE 2022-10-21 12:56:03 Stopping AWS deployment 2022-10-21 12:59:15 Deleting AWS deployment 2022-10-21 12:59:15 Done
Conclusion
This post shows how easy it is to use StreamSets DataOps Platform to run jobs on dynamically deployed engines, minimizing public cloud infrastructure costs. This approach is made possible by StreamSets’ cloud-native integration, elegant runtime binding between jobs and engines, and full-featured automation using the StreamSets SDK. Give it a try!
