This blog post concludes a short series building up a IoT sensor testbed with StreamSets Data Collector (SDC), a Raspberry Pi and Apache Cassandra. Previously, I covered:
- Part 1: Ingesting Sensor Data on the Raspberry Pi with StreamSets Data Collector
- Part 2: Retrieving Metrics via the StreamSets Data Collector REST API
- Part 3: Standard Deviations on Cassandra – Rolling Your Own Aggregate Function
To wrap up, I’ll show you how I retrieved statistics from Cassandra, fed them into SDC, and was able to filter out ‘outlier’ values.
Filtering in StreamSets Data Collector
It’s easy to use SDC’s Stream Selector to filter out records, sending them to some destination for further analysis. Recall from part 1, the Raspberry Pi is collecting temperature, pressure and altitude data and appending readings as JSON objects to a text file. Let’s define some static boundaries for expected readings. Since the sensor is located in my home office, I’m pretty sure it’s never going to read temperatures lower than freezing (0C) or higher than boiling (100C), so let’s make those our boundary conditions.
First, I’ll insert a Stream Selector between the File Tail origin and the Field Converter by selecting the stream (arrow) between them, choosing Stream Selector from the dropdown list of processors, and hitting the auto-arrange button to tidy things up:
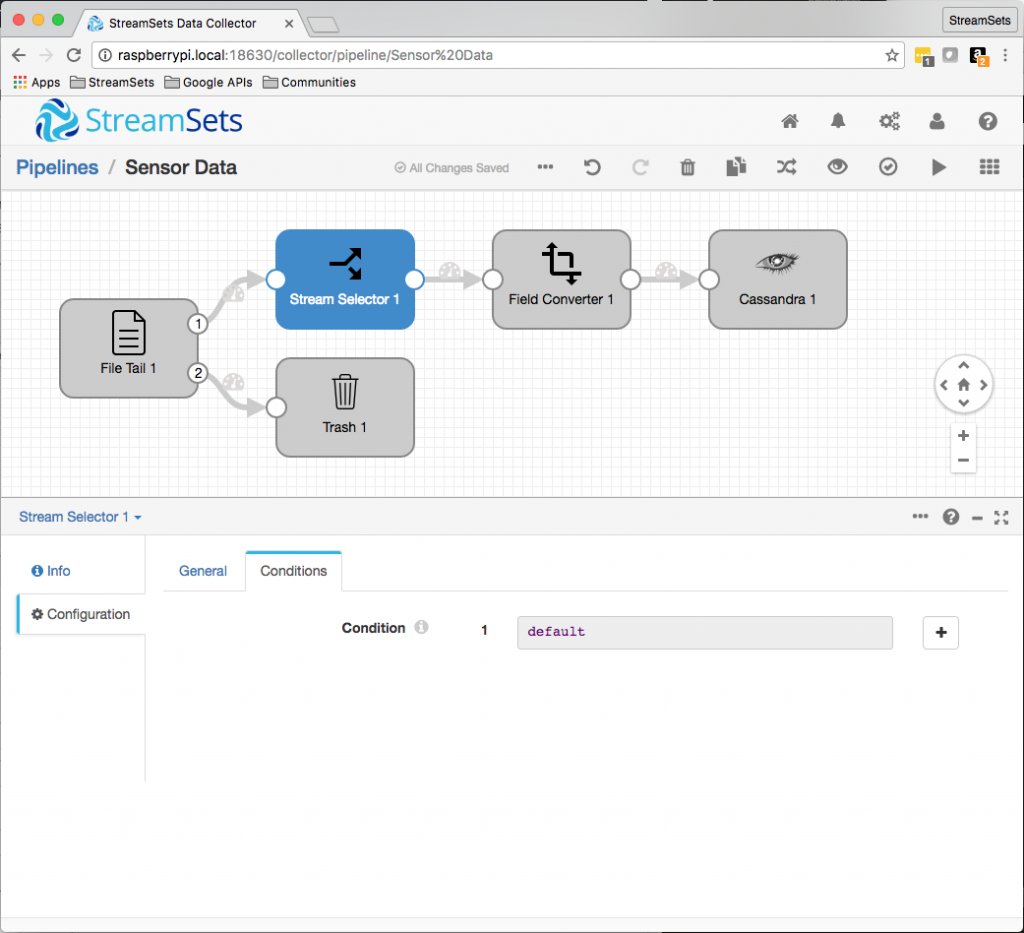
Now I’ll add a condition to filter my outlier readings out of the pipeline. Stream Selector uses SDC’s expression language to define conditions. The expression we need is simply ${record:value('/temp_deg_C') < 0 or record:value('/temp_deg_C') > 100}:
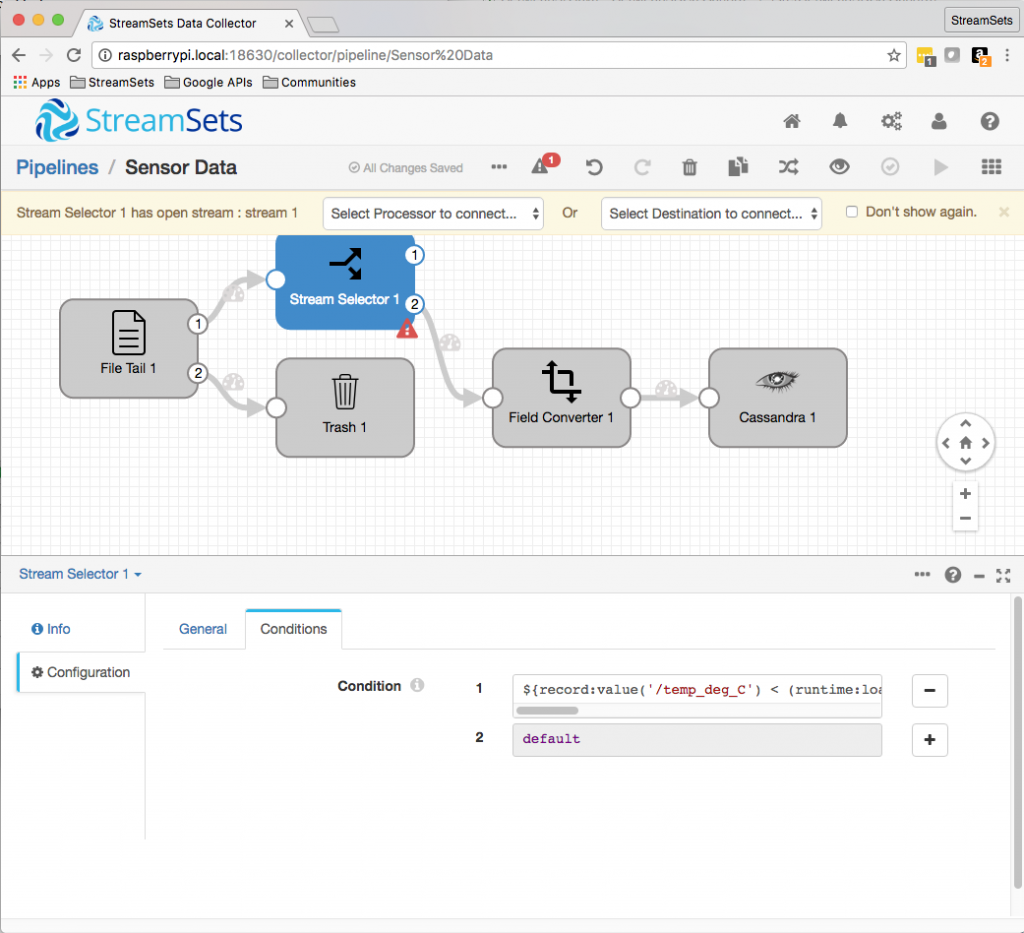
We need to send the outlier readings to their own store for later analysis. For simplicity, I’ll send JSON objects to a text file:
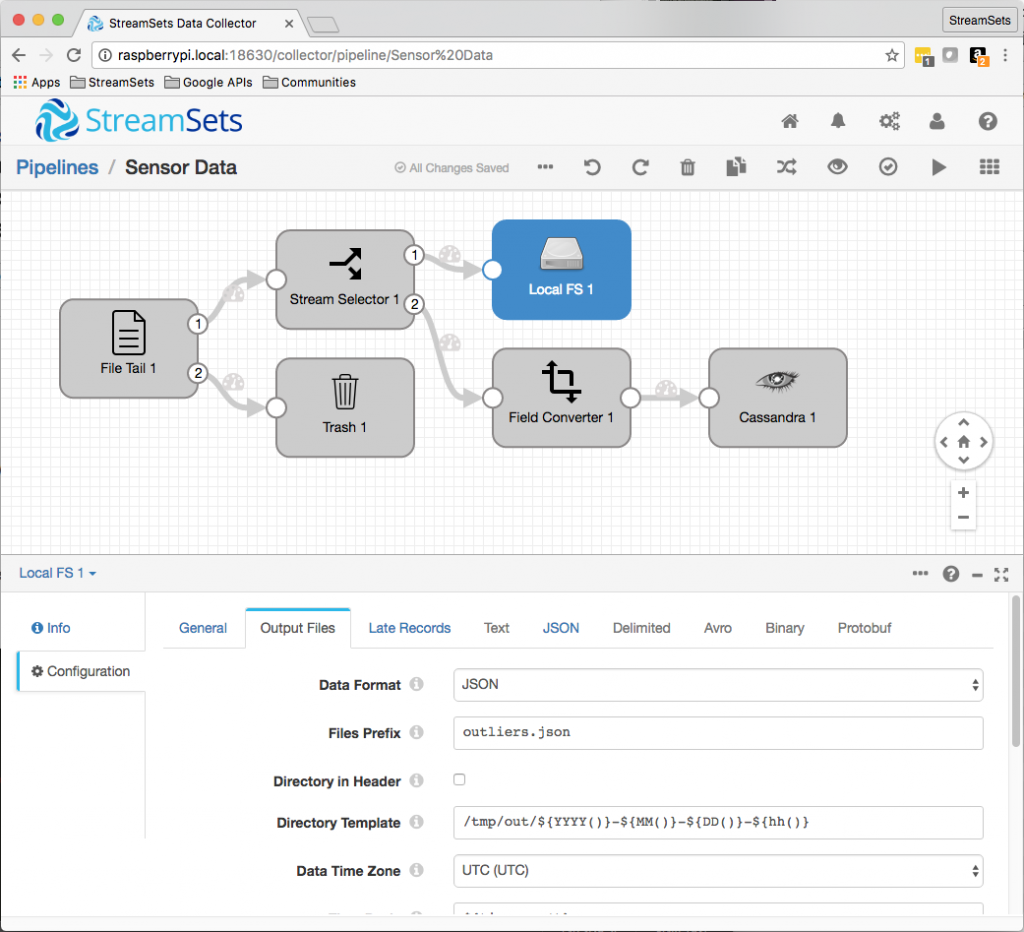
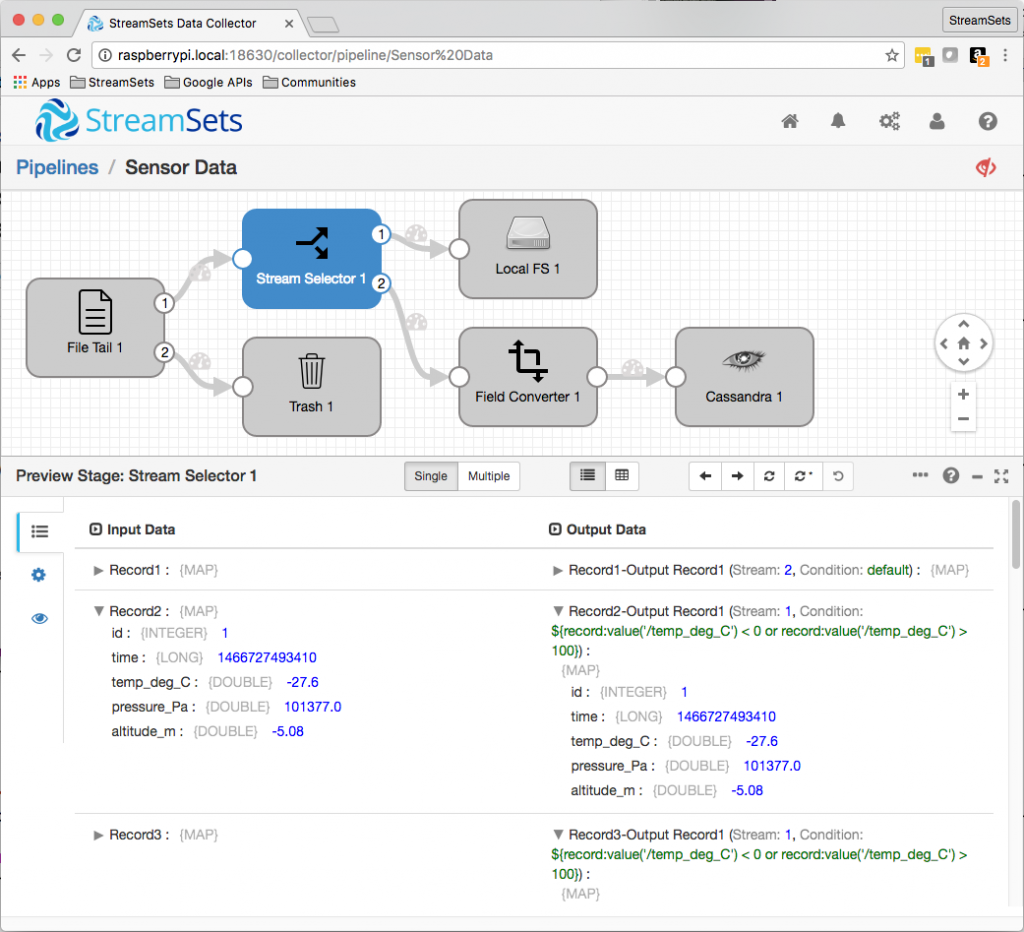
The sensor is appending JSON objects to a file that the pipeline is reading as its origin. It’s easy to backup that file, modify some readings at the top to fall outside our boundaries, and then use preview to check that they are correctly sent to the outlier file:
Dynamic Outlier Detection
Now we’re successfully filtering out readings based on static boundaries, let’s look at a more dynamic approach. The temperature in my home office fluctuates throughout the day and night. A reading of 15C (60F) might be commonplace in the middle of the night, but an outlier on a warm summer afternoon, and might indicate sensor failure, or some environmental problem.
In the last blog entry, I implemented a user defined aggregate (UDA) in Cassandra, giving me the ability to calculate the standard deviation across a set of values. As I explained then, a common way of detecting outliers is to flag readings that fall outside some range expressed in terms of the mean +/- some number of standard deviations (also known as ‘sigma’ or σ). For instance, assuming a normal distribution, 99.7% of values should fall within 3σ of the mean, while 99.95% of values should fall within 4σ.
Since temperature fluctuates throughout the day, I decided that ‘expected’ readings should fall within 4σ of the mean for the last hour, with anything outside that range being classed as an outlier. Let’s see the statistics for the past hour:
cqlsh:mykeyspace> select count(*), avg(temperature), stdev(temperature) from sensor_readings where time > '2016-08-17 18:11:00+0000' and sensor_id = 1; count | system.avg(temperature) | mykeyspace.stdev(temperature) -------+-------------------------+------------------------------- 337 | 24.85668 | 0.234314
So, with a mean of 24.86 and a standard deviation of 0.2343, I want any reading less than 23.92 or greater than 25.80 to be sent to the outliers file for further analysis.
Dynamic Configuration in StreamSets Data Collector
At this point, I knew how to get the statistics I needed from Cassandra, but how would I implement dynamic outlier detection in SDC? The REST API allows us to modify pipeline configuration, but that would require the pipeline to be stopped. Can we dynamically filter data without an interruption in data flow? Runtime Resources allow us to do exactly that.
A quick test illustrates the concept. We can create a pipeline using the Dev Raw Data Source origin, an Expression Evaluator, and the Trash destination. The Expression Evaluator will simply set a field on each record with the current content of the file:
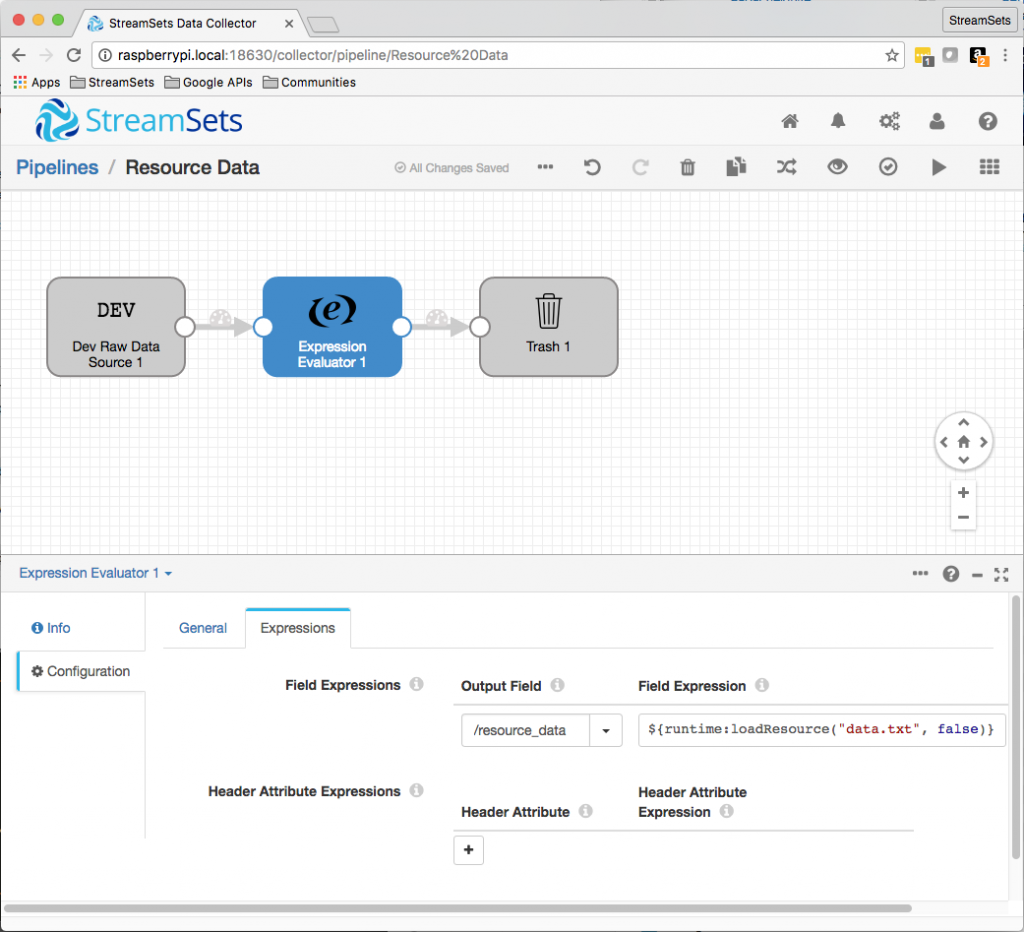
Now we can set the pipeline running, modify our resource file, and take snapshots to see the result:
Success – we are injecting data dynamically into the pipeline!
Reading Statistics from Cassandra
The final piece of the puzzle is to periodically retrieve mean and standard deviation from Cassandra and write them to files in the SDC resource directory. I wrote a Java app to do just that (full source in gist). Here is the core of the app:
// Use a PreparedStatement since we'll be issuing the same query many times
PreparedStatement statement = session.prepare(
"SELECT COUNT(*), AVG(temperature), STDEV(temperature) " +
"FROM sensor_readings " +
"WHERE sensor_id = ? " +
"AND TIME > ?");
BoundStatement boundStatement = new BoundStatement(statement);
while (true) {
long startMillis = System.currentTimeMillis() - timeRangeMillis;
ResultSet results = session.execute(boundStatement.bind(sensorId, new Date(startMillis)));
Row row = results.one();
long count = row.getLong("count");
double avg = row.getDouble("system.avg(temperature)"),
sd = row.getDouble("mykeyspace.stdev(temperature)");
System.out.println("COUNT: "+count+", AVG: "+avg+", SD: "+sd);
try (PrintWriter writer = new PrintWriter(resourceDir + "mean.txt", "UTF-8")) {
writer.format("%g", avg);
}
try (PrintWriter writer = new PrintWriter(resourceDir + "sd.txt", "UTF-8")) {
writer.format("%g", sd);
}
Thread.sleep(sleepMillis);
}
The app is very simple – it creates a PreparedStatement to query for statistics on sensor readings within a given time range, periodically executes that statement to get the count, mean and standard deviation, displays the data, and writes the mean and standard deviation to two separate files in SDC’s resource directory.
We want to filter outliers more than 4 standard devations from the mean, so let’s modify our Stream Selector to use the following expression as its filter:
${record:value('/temp_deg_C') < (runtime:loadResource("mean.txt", false) - 4 * runtime:loadResource("sd.txt", false)) or record:value('/temp_deg_C') > (runtime:loadResource("mean.txt", false) + 4 * runtime:loadResource("sd.txt", false))}
Now we can restart the pipeline, and any incoming records with anomalous temperature values will be written to the outlier file. Here’s the pipeline in action:
Conclusion
We’ve covered a lot of ground over the course of this series of blog entries! We’ve looked at:
* Running SDC on the Raspberry Pi to ingest IoT sensor data
* Using the SDC REST API to extract pipeline metrics
* Creating a User Defined Aggregate on Cassandra to implement standard deviations
* Dynamically filtering outlier data in an SDC pipeline
Over the course of a few hours, I’ve built a fairly sophisticated IoT testbed, and learned a lot about both SDC and Cassandra. I’ll be presenting this content in a session at the Cassandra Summit next month in San Jose: Adaptive Data Cleansing with StreamSets and Cassandra (Thursday, September 8, 2016 at 1:15 PM in room LL20D). Come along, say hi, and see the system in action, live!