Splunk is the tool-of-choice for many enterprises mining insights from machine-generated data such as server logs, but one problem with the default tools is that there is no way to filter the data as it is fed into Splunk. It’s easy to fill Splunk with redundant or irrelevant data, driving up costs without adding value.
StreamSets Data Collector has long been able to write data to Splunk using its HTTP Client destination, but the recently released version 3.4.0 of Data Collector introduces a new Splunk destination, making it easier than ever to write only the necessary data to Splunk. In this blog post we’ll review one of the primary use cases for Splunk ingest – cybersecurity – and see how Data Collector enables more efficient data integration.
Cybersecurity with the StreamSets DataOps Platform
Here’s a high level cybersecurity architecture for collecting logs from a variety of systems and sending them to both Splunk and one or more cloud or on-premise data stores for analysis by tools such as Spark and Impala:
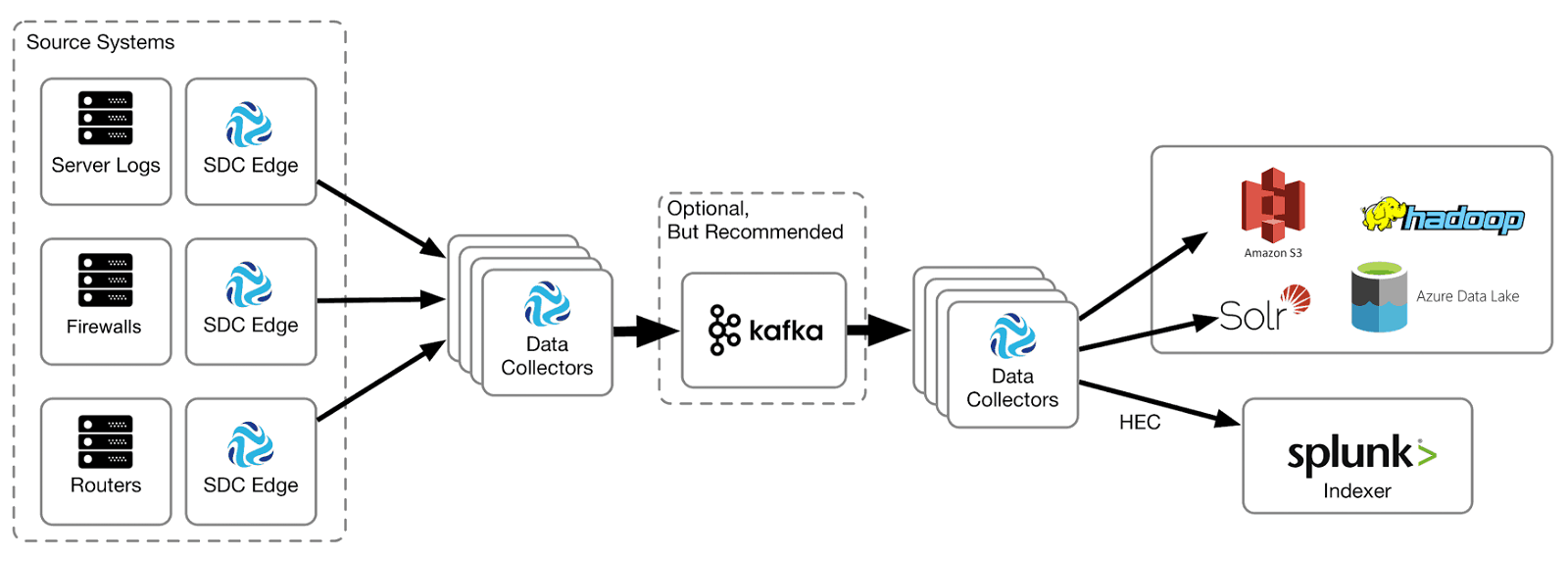
In the architecture, StreamSets Data Collector Edge is deployed to collect logs from Windows and Linux servers, and network equipment such as firewalls and routers. Data Collector Edge sends log records to a cluster of Data Collector instances which feed a Kafka topic, allowing flexibility in buffering the incoming data. A second cluster of Data Collectors reads from Kafka and archives all incoming log data to the enterprise data vault while sending a filtered stream of data to the Splunk HTTP Event Collector (HEC).
Filtering raw event data en route to Splunk is key to implementing an efficient architecture – this blog post explains how events often contain redundant and irrelevant data, and how the StreamSets DataOps Platform allows you to getting the most out of your storage and budget.
StreamSets Data Collector Splunk Destination
The new Splunk destination sends a batch of records at a time to the Splunk HEC in exactly the same way as the HTTP Client destination, but is configured by simply specifying the Splunk API endpoint and HEC token:
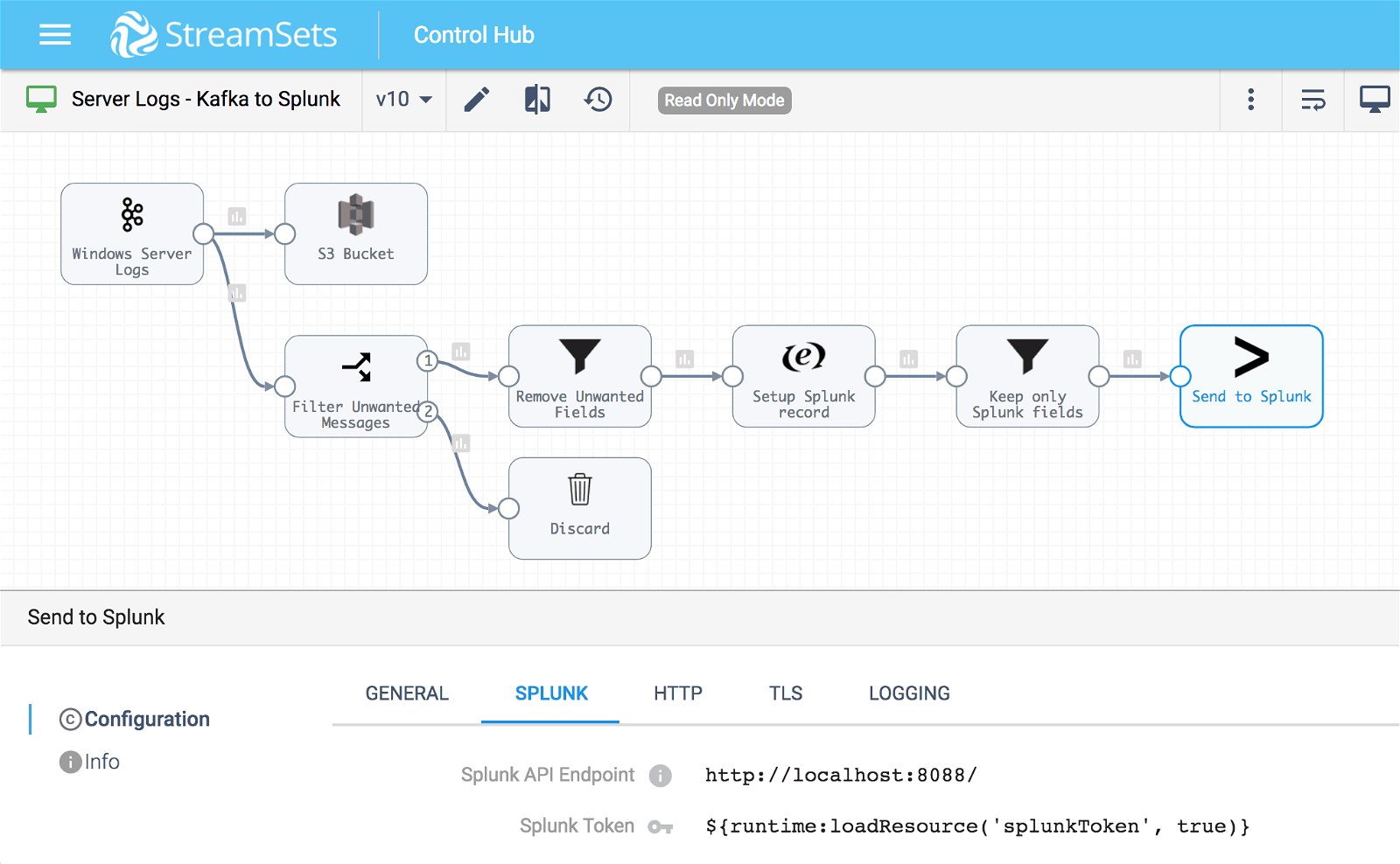
You can specify the HEC token directly, or load it from a resource file or credential store using the appropriate expression. The Splunk destination uses the Splunk API endpoint and HEC token to connect and authenticate to the HEC.
Conclusion
The StreamSets DataOps Platform puts you in control of the event data that you send to Splunk. StreamSets Data Collector’s new Splunk destination integrates with credential store for secure storage of Splunk credentials, and makes sending event data to Splunk easier than ever.
To try this out yourself, download our open source StreamSets Data Collector including a free Getting Started Session or contact us to arrange a StreamSets Control Hub trial.