![]() Many StreamSets customers use Splunk to mine insights from machine-generated data such as server logs, but one problem they encounter with the default tools is that they have no way to filter the data that they are forwarding. While Splunk is a great tool for searching and analyzing machine-generated data, particularly in cybersecurity use cases, it’s easy to fill it with redundant or irrelevant data, driving up costs without adding value. In addition, Splunk may not natively offer the types of analytics you prefer, so you might also need to send that data elsewhere.
Many StreamSets customers use Splunk to mine insights from machine-generated data such as server logs, but one problem they encounter with the default tools is that they have no way to filter the data that they are forwarding. While Splunk is a great tool for searching and analyzing machine-generated data, particularly in cybersecurity use cases, it’s easy to fill it with redundant or irrelevant data, driving up costs without adding value. In addition, Splunk may not natively offer the types of analytics you prefer, so you might also need to send that data elsewhere.
In this blog entry I’ll explain how, with StreamSets Control Hub, we can build a topology of pipelines for efficient Splunk data ingestion to support cybersecurity and other domains, by sending only necessary and unique data to Splunk and routing other data to less expensive and/or more analytics-rich platforms.
Limitations in Using Splunk Forwarders
Currently, most organizations use Splunk Universal and Heavy Forwarders to send unparsed data and parsed event records to the Splunk Indexer for later search and analysis. Unfortunately, event records may contain large amounts of redundant and irrelevant data, not only obscuring useful information, but consuming Splunk storage and driving up costs.
You can use StreamSets to reduce your Splunk spend while also making data available to other analytics platforms with more efficient Splunk data ingestion.
Cybersecurity with StreamSets Control Hub
Here’s a high level cybersecurity architecture for collecting logs from a variety of systems and sending them to both Splunk and one or more cloud or on-premise data stores for analysis by tools such as Spark and Impala:
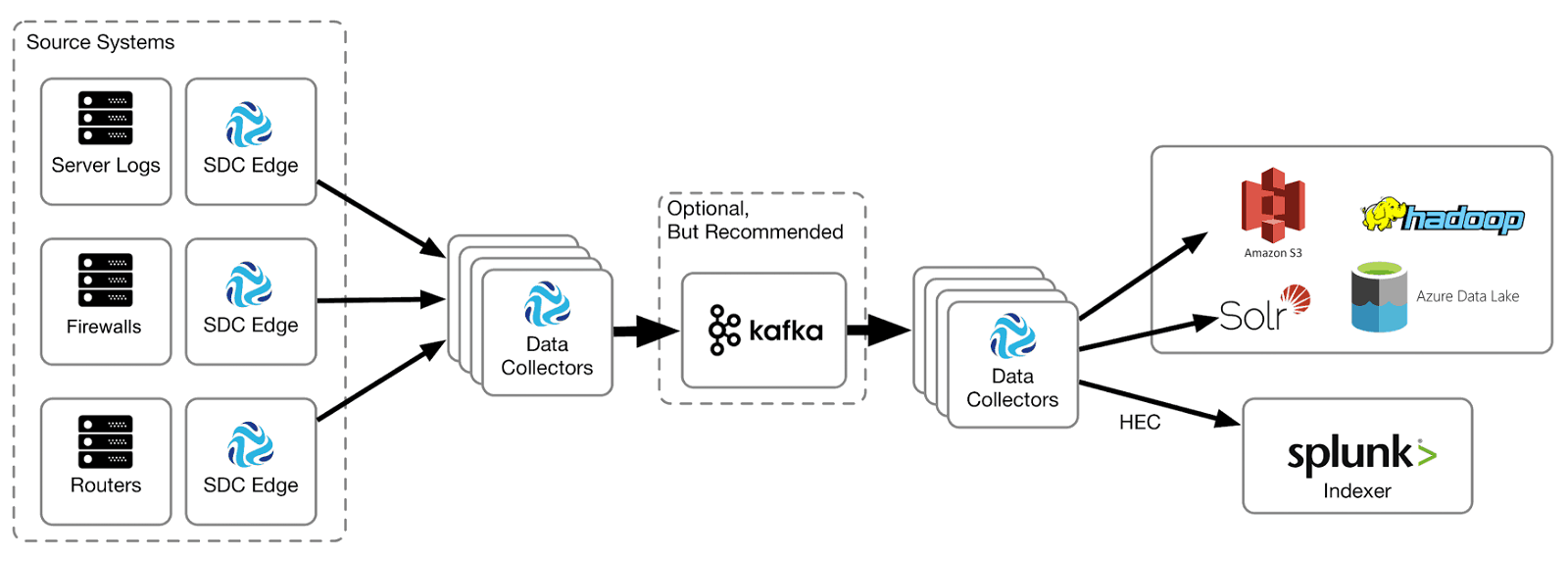
In the architecture, StreamSets Data Collector Edge is deployed to collect logs from Windows and Linux servers, and network equipment such as firewalls and routers. Data Collector Edge sends log records to a cluster of Data Collector instances which feed a Kafka topic, allowing flexibility in buffering the incoming data. A second cluster of Data Collectors reads from Kafka and archives all incoming log data to the enterprise data vault while sending a filtered stream of data to the Splunk HTTP Event Collector.
Why Filter Log Data?
Let’s look at a typical Windows Event Log record, formatted as JSON:
{
"Category": 13826,
"ComputerName": "Rivendell",
"DataLength": 0,
"DataOffset": 374,
"EventId": 4799,
"Length": 380,
"LogName": "Security",
"Message": "NO_RES_MSG: Backup Operators Builtin S-1-5-32-551 S-1-5-18 ELROND$ WORKGROUP 0x3e7 0x29c C:\\Windows\\System32\\svchost.exe",
"MsgStrings": [
"Backup Operators",
"Builtin",
"S-1-5-32-551",
"S-1-5-18",
"ELROND$",
"WORKGROUP",
"0x3e7",
"0x29c",
"C:\\Windows\\System32\\svchost.exe"
],
"NumStrings": 9,
"RecordNumber": 4625,
"Reserved": 1699505740,
"ReservedFlags": 0,
"SourceName": "Microsoft-Windows-Security-Auditing",
"StringOffset": 152,
"TimeGenerated": 1457244181,
"TimeWritten": 1457244181,
"UserSidLength": 0,
"UserSidOffset": 152
}
Much of this data is redundant or irrelevant. The Message field is simply a concatenation of the contents of the MsgStrings array. Fields such as DataLength, DataOffset, UserSidLength and UserSidOffset are essential for navigating the binary log file, but carry no useful information regarding the event. There are also fields such as Reserved and ReservedFlags that hold the exact same values for every event in the log.
Removing the redundant and irrelevant data, then, we can see that we only really need to send about half of the original event record to Splunk:
{
"Category": 13826,
"ComputerName": "Rivendell",
"EventId": 4799,
"LogName": "Security",
"MsgStrings": [
"Backup Operators",
"Builtin",
"S-1-5-32-551",
"S-1-5-18",
"ELROND$",
"WORKGROUP",
"0x3e7",
"0x29c",
"C:\\Windows\\System32\\svchost.exe"
],
"RecordNumber": 4625,
"SourceName": "Microsoft-Windows-Security-Auditing",
"TimeGenerated": 1457244181,
"TimeWritten": 1457244181
}
In addition, we can apply conditions to filter out entire records if we decide, for example, that we only want events from Microsoft-Windows-Security-Auditing, discarding events from other sources, further reducing the payload hitting Splunk and incurring costs.
Filtering Events in StreamSets Control Hub
It’s straightforward to build a pipeline in Control Hub to read event log records from Kafka, send them all to a cloud or on-premise data store, and filter the data before forwarding it to the Splunk HTTP Event Collector:
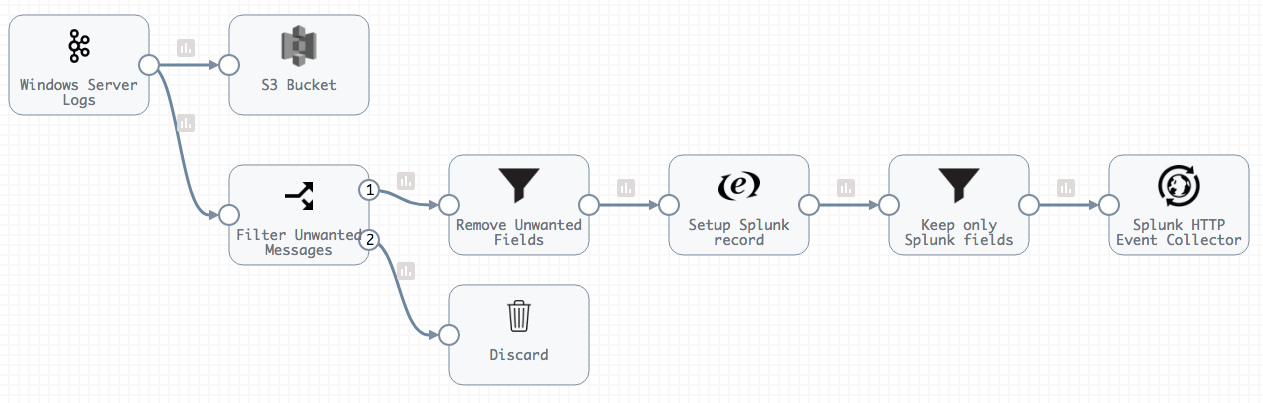
This short video walks through the architecture, with a focus on the filtering operation:
Conclusion
Filtering events before sending them to Splunk not only makes your storage and budget go further, it makes it easier to see the relevant information without extraneous data.
To try this out yourself, download our open source StreamSets Data Collector including a free Getting Started Session or contact us to arrange a StreamSets Control Hub trial.