![]() Apache Avro is widely used in the Hadoop ecosystem for efficiently serializing data so that it may be exchanged between applications written in a variety of programming languages. Avro allows data to be self-describing; when data is serialized via Avro, its schema is stored with it. Applications reading Avro-serialized data at a later time read the schema and use it when deserializing the data.
Apache Avro is widely used in the Hadoop ecosystem for efficiently serializing data so that it may be exchanged between applications written in a variety of programming languages. Avro allows data to be self-describing; when data is serialized via Avro, its schema is stored with it. Applications reading Avro-serialized data at a later time read the schema and use it when deserializing the data.
While StreamSets Data Collector (SDC) frees you from the tyranny of schema, it can also work with tools that take a more rigid approach. In this blog, I’ll explain a little of how Avro works and how SDC can integrate with Confluent Schema Registry’s distributed Avro schema storage layer when reading and writing data to Apache Kafka topics and other destinations.
Apache Avro
Avro is a very efficient way of storing data in files, since the schema is written just once, at the beginning of the file, followed by any number of records; contrast this with JSON or XML where each data element is tagged with metadata. Similarly, Avro is well suited to connection-oriented protocols, where participants can exchange schema data at the start of a session, and exchange serialized records from that point on. Avro works less well in a message-oriented scenario, since producers and consumers are loosely coupled and may read or write any number of records at a time. To ensure that the consumer has the correct schema, it must either be exchanged ‘out of band’ or accompany every message. Unfortunately, sending the schema with every message imposes significant overhead – in many cases the schema is as big as the data, or even bigger!
Confluent Schema Registry
Confluent Schema Registry (CSR) addresses this issue by allowing applications to register and retrieve Avro schemas, each uniquely identified by a schema ID. Now a Kafka producer can send data accompanied by the schema ID, and, on reading the message, Kafka consumers can retrieve the schema from CSR and use it in deserializing the data. The net effect is that schemas are passed ‘by reference’ rather than ‘by value’. Read Gwen Shapira’s CSR blog entry to learn more.
Avro and CSR in Action
Let’s use SDC and Avro to write some messages, and the Kafka command line tools to read them. We’ll easily see the difference that passing schema data by reference makes to message size.
Here’s my pipeline, a variation on the Taxi Tutorial pipeline presented in the SDC documentation:
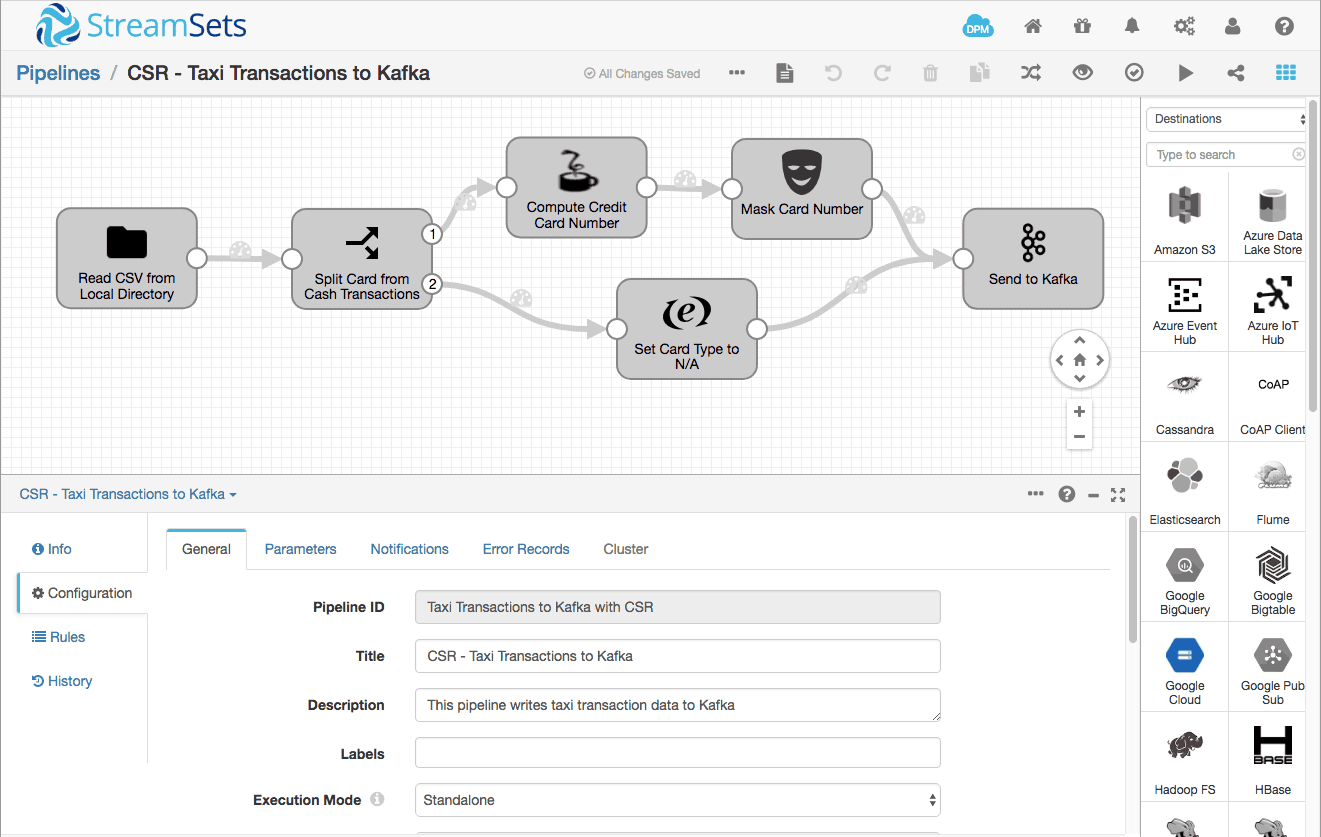
Let’s look at the Kafka Producer configuration in a little more detail:
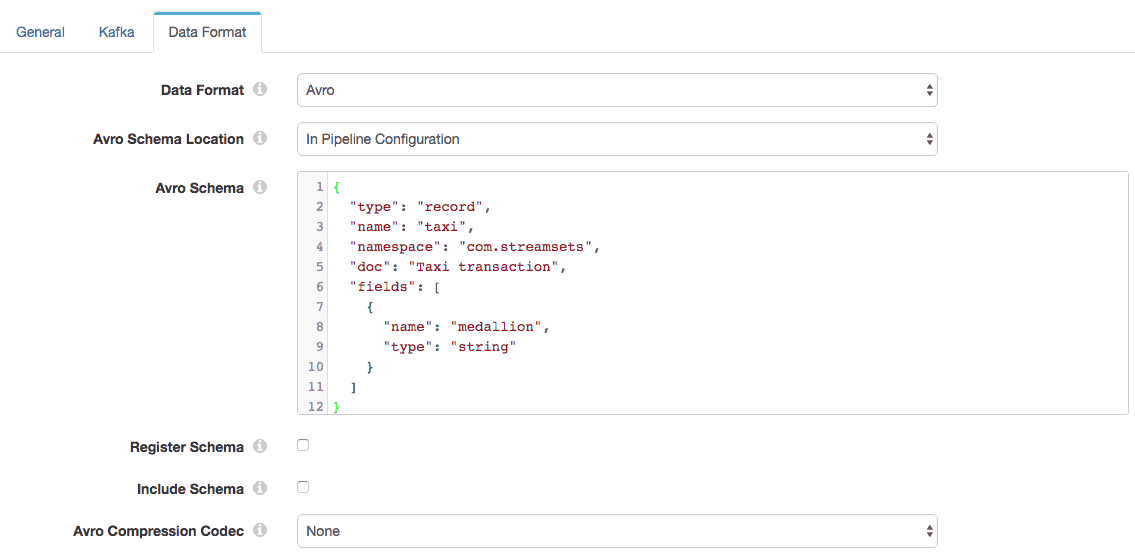
I’ve defined a very simple Avro schema that includes just the taxi’s medallion number in the transaction, so we can easily see the data and schema in each message. SDC includes a Schema Generator processor that automatically generates an Avro schema based on the structure of a record, writing the schema into a record header attribute. Since I wanted a very small subset of the record’s fields in this case, I defined a simple Avro schema manually. I’ll cover the Schema Generator in a future blog post.
Running the pipeline on a few records produces the following output in the Kafka command line consumer:
@F6F7D02179BE915B23EF2DB57836442D @BE386D8524FCD16B3727DCF0A32D9B25 @E9FF471F36A91031FE5B6D6228674089 @89D227B655E5C82AECF13C3F540D4CF4 @0BD7C8F5BA12B88E0B67BED28BEA73D8
Avro is a binary format, and the consumer is just showing text, but we can see that there is minimal overhead in each message – just one byte, that shows up as the @ character before the actual data.
In this scenario, the producer and consumer would have to agree on the schema out of band, since it is not transmitted on the wire. Now let’s enable Include Schema in the Kafka Producer and run the pipeline again on the same data. Here’s the output:
Objavro.schema?{"type":"record","name":"taxi","namespace":"com.streamsets","doc":"Taxi transaction","fields":[{"name":"medallion","type":"string"}]}avro.codenull???er??^???-??{?B@F6F7D02179BE915B23EF2DB57836442D???er??^???-??{?
Objavro.schema?{"type":"record","name":"taxi","namespace":"com.streamsets","doc":"Taxi transaction","fields":[{"name":"medallion","type":"string"}]}avro.codenull-0??2?\????VtB@BE386D8524FCD16B3727DCF0A32D9B25-0??2?\????Vt
Objavro.schema?{"type":"record","name":"taxi","namespace":"com.streamsets","doc":"Taxi transaction","fields":[{"name":"medallion","type":"string"}]}avro.codenull?NF<?cp?ޭB@E9FF471F36A91031FE5B6D6228674089?NF<?cp?ޭ
Objavro.schema?{"type":"record","name":"taxi","namespace":"com.streamsets","doc":"Taxi transaction","fields":[{"name":"medallion","type":"string"}]}avro.codenullY?37MA?v3?B?V?B@89D227B655E5C82AECF13C3F540D4CF4Y?37MA?v3?B?V?
Objavro.schema?{"type":"record","name":"taxi","namespace":"com.streamsets","doc":"Taxi transaction","fields":[{"name":"medallion","type":"string"}]}avro.codenullO?)$8N?Wde?Ov?B@0BD7C8F5BA12B88E0B67BED28BEA73D8O?)$8N?Wde?Ov?
Wow! We can see straight away that the schema is sent with each message, and the schema overhead is several times the message size! Recall that in a message-oriented scenario, when we don’t agree the schema up front, we need to include the schema with each message, since the producer doesn’t know when the consumer might be reading messages, or how many it may read at a time.
So – how can we transmit schemas efficiently from the producer to the consumer? This is where CSR comes into play. CSR has a simple REST API that allows consumers to register Avro schemas, receiving a unique schema ID for each one. Now the producer can include the schema ID with each message, and the consumer can use that to retrieve the schema from CSR and correctly deserialize the message.
In SDC’s Kafka Producer, I change Avro Schema Location from In Pipeline Configuration to Confluent Schema Registry, set the Schema Registry URL and Schema ID, and disable Include Schema:
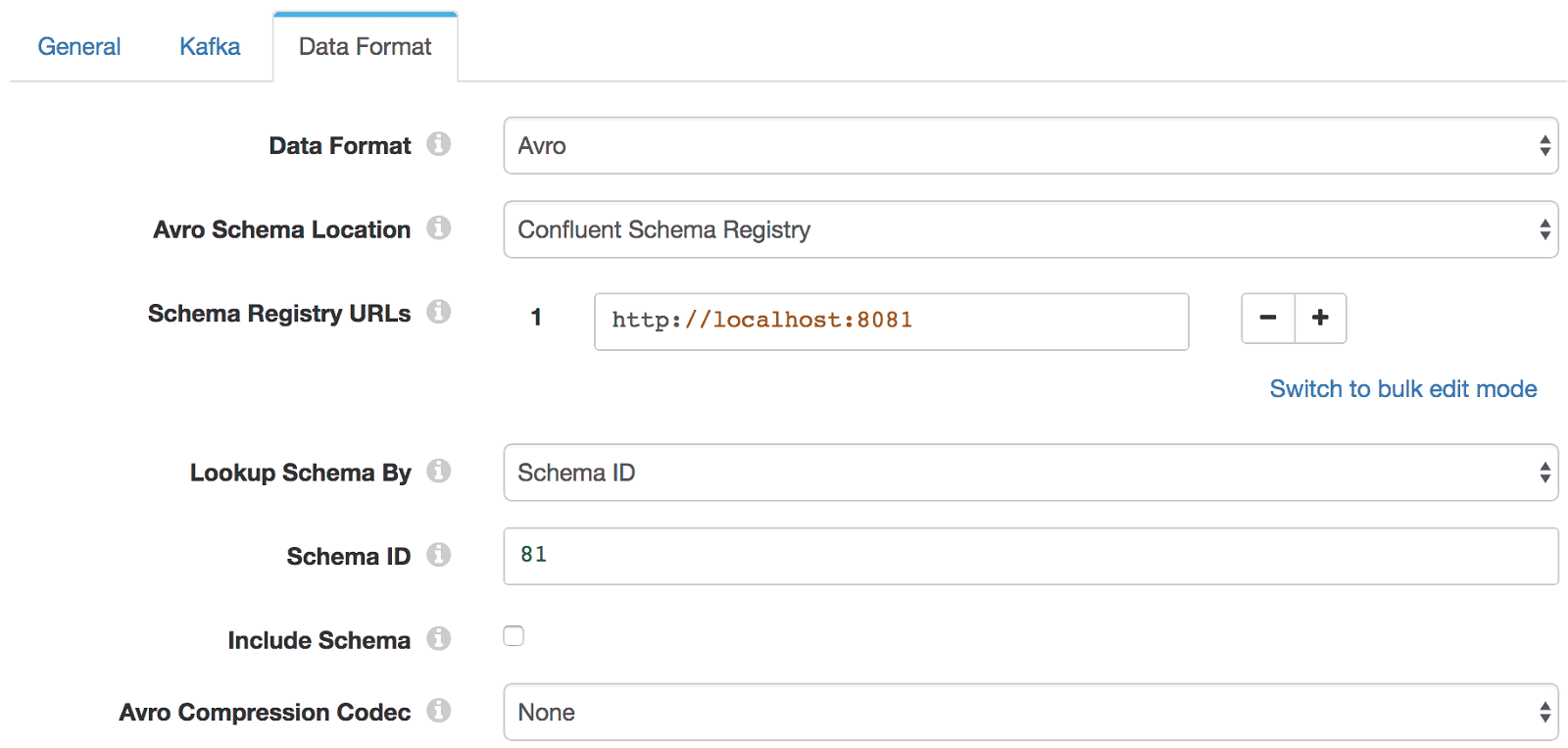
Now the Kafka Producer will simply include the schema ID with each message. Again, let’s see the data as received by the consumer:
@F6F7D02179BE915B23EF2DB57836442D @BE386D8524FCD16B3727DCF0A32D9B25 @E9FF471F36A91031FE5B6D6228674089 @89D227B655E5C82AECF13C3F540D4CF4 @0BD7C8F5BA12B88E0B67BED28BEA73D8
We can see that the schema overhead is gone from the message. At this point, let’s switch to the Kafka Avro Console Consumer and see what it makes of the data:
{"medallion":"F6F7D02179BE915B23EF2DB57836442D"}
{"medallion":"BE386D8524FCD16B3727DCF0A32D9B25"}
{"medallion":"E9FF471F36A91031FE5B6D6228674089"}
{"medallion":"89D227B655E5C82AECF13C3F540D4CF4"}
{"medallion":"0BD7C8F5BA12B88E0B67BED28BEA73D8"}
Since this consumer is CSR- and Avro-aware, it recognizes the schema ID, downloads it from CSR, deserializes the message and displays it with the correct field name.
We can use CSR’s REST API to retrieve the schema from the command line:
$ curl -s http://localhost:8081/schemas/ids/1 | jq -r .schema | jq .
{
"type": "record",
"name": "taxi",
"namespace": "com.streamsets",
"doc": "Taxi transaction",
"fields": [
{
"name": "medallion",
"type": "string"
}
]
}
So far so good, but you might be asking yourself, “Couldn’t the producer and consumer just agree that they’re using that schema, and not even bother sending the schema ID in each message?”
Schema Evolution
They could do that, but including the schema ID allows the schema to evolve over time. Avro defines a set of rules that allow schema evolution, so, when the schema changes, the producer can register the new one, include the new schema ID with each message, and the consumer will be able to retrieve the new schema and deserialize messages appropriately.
Here’s the new schema, with ID 81. All I did was add another string field to the message. Note that we have to supply a default value for the new field, to satisfy Avro’s rules on backward compatibility – existing data must be readable under the new schema.
$ curl -s http://localhost:8081/schemas/ids/81 | jq -r .schema | jq .
{
"type": "record",
"name": "taxi",
"namespace": "com.streamsets",
"doc": "Taxi transaction",
"fields": [
{
"name": "medallion",
"type": "string"
},
{
"name": "hack_license",
"type": "string",
"default": ""
}
]
}
In SDC, I just update Schema ID in the Kafka Producer, rerun the pipeline, and the Kafka Avro consumer sees the new field:
{"medallion":"F6F7D02179BE915B23EF2DB57836442D","hack_license":"088879B44B80CC9ED43724776C539370"}
{"medallion":"BE386D8524FCD16B3727DCF0A32D9B25","hack_license":"4EB96EC9F3A42794DEE233EC8A2616CE"}
{"medallion":"E9FF471F36A91031FE5B6D6228674089","hack_license":"72E0B04464AD6513F6A613AABB04E701"}
{"medallion":"89D227B655E5C82AECF13C3F540D4CF4","hack_license":"BA96DE419E711691B9445D6A6307C170"}
{"medallion":"0BD7C8F5BA12B88E0B67BED28BEA73D8","hack_license":"9FD8F69F0804BDB5549F40E9DA1BE472"}
Conclusion
Apache Avro is a compact, row-oriented message format that allows us to exchange data in an efficient manner. In a message-oriented setting, though, with decoupled producers and consumers, schema overhead becomes significant. Referencing schema by ID dramatically reduces message size, and thus network traffic, while allowing schemas to evolve dynamically. StreamSets Data Collector supports Confluent Schema Registry when sending Avro-serialized data via Kafka, giving you the benefits of Avro’s compact data representation while removing schema overhead and allowing evolution.
I presented this content at Kafka Summit 2017 in San Francisco – view slides and video from that presentation.