The StreamSets DataOps Platform was architected to scale to the largest workloads, particularly when working with continuous streams of data from systems such as Apache Kafka or Apache Pulsar. As well as the ability to scale Kafka, the platform offers a number of deployment options, allowing you to trade off complexity, performance, and cost. This blog entry explains how to scale StreamSets Data Collector Engine to handle massive message throughput with Kafka and StreamSets, as recently presented in the webinar, Five Ways to Scale Kafka.
The Throughput Challenge
Any data pipeline running in StreamSets Data Collector Engine has a maximum throughput capacity in messages per unit time. Each message, or batch of messages, takes some amount of time to be processed in the pipeline – longer time to process implies lower message throughput.
Above the maximum throughput capacity, the pipeline cannot keep up with the flow of incoming messages, and back pressure is applied in the form of messages buffering in the Kafka topic. In the short term, this is not necessarily a problem – if the flow of messages into the Kafka topic falls over time, then the pipeline will be able to catch up. Where older messaging technologies struggled to manage back pressure, Kafka’s robust persistent storage has made it a fixture in many data architectures.

If the pipeline’s throughput falls below the message arrival rate indefinitely, then messages will be buffered in Kafka for increasing amounts of time, increasing latency, the amount of time required for a message to reach its eventual recipient, and ultimately overflowing Kafka’s storage.
If the message arrival rate is more than a single pipeline can handle, how do we scale the pipeline to handle more throughput? There are a variety of directions we can take.
1. Scale Kafka Vertically – Deploy a Bigger Box
The simplest, but often least cost-effective, option is to simply run Data Collector on a more powerful machine. You can enable concurrent message consumption in Kafka by partitioning the Kafka topic; Data Collector’s Kafka Multitopic Consumer origin can then take advantage of additional processors and memory to run several consumer threads in parallel. Kafka will distribute messages across the partitions, and the load will be shared between the consumer threads.
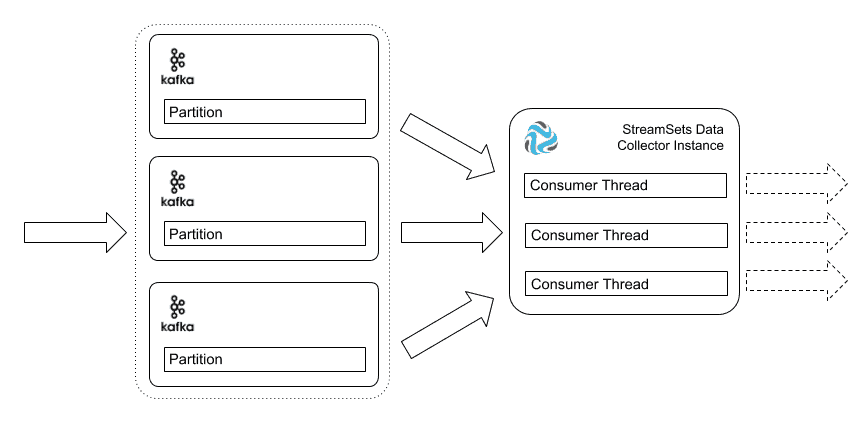
Note that the number of partitions and the number of consumers does not have to be equal. If the number of consumers is less than the number of partitions, then Kafka will automatically assign multiple partitions to one or more consumers. If there are more consumers than partitions, on the other hand, then some consumers will sit idle.
There are a couple of drawbacks with vertical scaling. One is that, to maximize throughput, you have to size the machine for the maximum expected load, even though the average load may be much less than the peak. In other words, your expensive big box could be mostly idle much of the time. Another drawback is that, with a single large machine, there is no fault tolerance. If the machine goes down, data stops flowing.
Scale Kafka Horizontally – Deploy More Boxes
A more flexible, and usually more cost-effective, strategy is horizontal scaling, again partitioning the Kafka topic, but this time running the pipeline on multiple Data Collector instances to scale Kafka horizontally.
There are a few options here, depending on the resources you have available. All of these options allow scaling with elasticity – the flexibility to add and remove capacity as requirements change over time – and can provide fault tolerance.
2. Manually Run Multiple Data Collectors
You can manually run the same pipeline on several data collectors. You will need to manually export the pipeline definition from the ‘design’ Data Collector instance, and import it into each ‘execution’ instance. Since all of the pipelines are configured with the same consumer group, Kafka will assign partitions to consumers, just as in case 1 above.
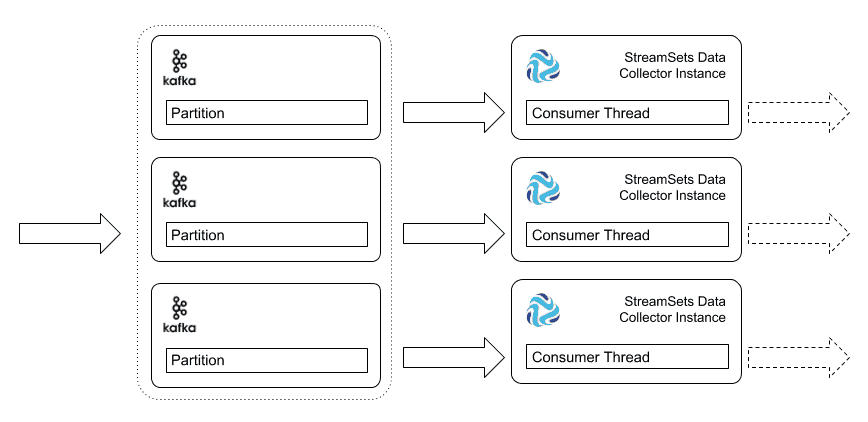
This approach is straightforward, but relies on the operator to distribute pipeline files to the Data Collector instances, and manually start and stop Data Collector instances as required.
If a single Data Collector instance goes down, Kafka will automatically assign its partition to a remaining instance; data keeps flowing, albeit at a slower rate, since fewer processing resources are available. When the operator starts the pipeline on Data Collector instance Kafka will rebalance the partitions across the consumers.

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
3. Run the Pipeline in Cluster Streaming Mode
If you are running a YARN or Mesos cluster, you can take advantage of Data Collector’s Cluster Streaming mode. Configure the pipeline’s execution mode as ‘Cluster YARN Streaming’ or ‘Cluster Mesos Streaming’, select a compatible Kafka origin, and Data Collector will submit the pipeline as a cluster application, requesting as many nodes as there are partitions in the Kafka topic. This is a fairly simple way to scale Kafka.
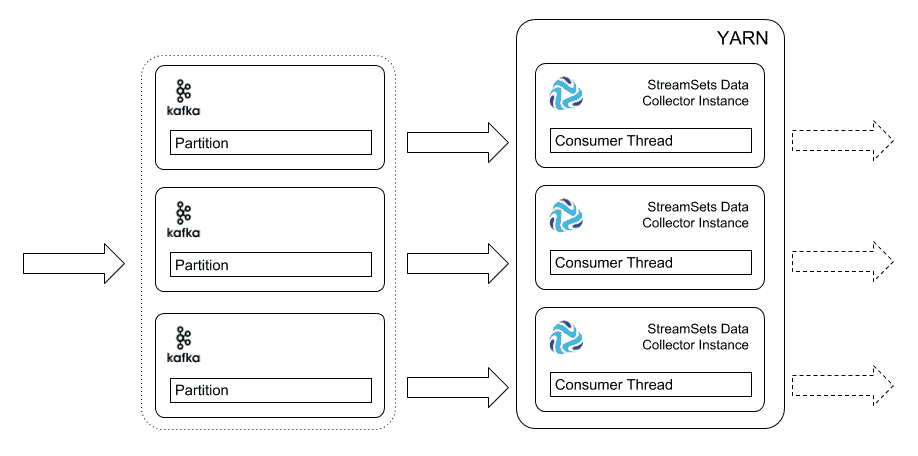
The advantage here is that Data Collector and the cluster platform are managing scaling for you. You don’t need to manually copy the pipeline definition between Data Collector instances, and, if the number of partitions changes, you can simply restart the pipeline to take account of the change with minimal service interruption, and, of course, no loss of data. Similarly, YARN takes care of restarting Data Collector in case of a node failure.
4. Use StreamSets Control Hub to Start Multiple Pipeline Instances
What can you do if you don’t want to manually manage Data Collector instances, but you don’t have a YARN or Mesos cluster? StreamSets Control Hub allows you to manage Data Collector instances and pipelines from a single user interface. A Control Hub job associates a pipeline with one or more labels, and lets you specify a maximum number of Data Collector instances to run the job.
When you start the job, Control Hub runs the pipeline on Data Collector instances with a corresponding label, up to the maximum number that you specified. Control Hub continuously monitors the Data Collector instances, so, if one goes offline, it will automatically assign the pipeline to another instance with a matching label.
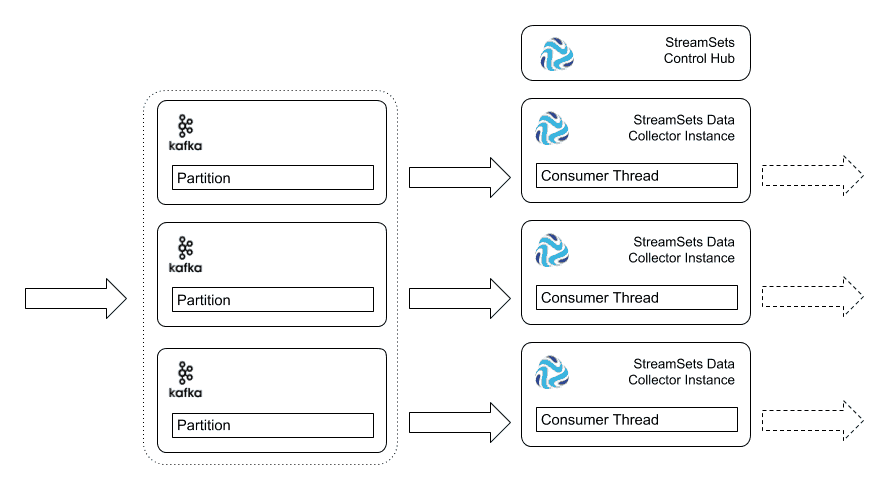
Control Hub provides similar automation to cluster streaming mode, but you do have to have a pool of Data Collector instances ready to run pipelines. Control Hub will also monitor the Data Collector instances; if one goes down, and failover is configured for the job, the pipeline will be assigned to another instance according to the job label.
5. Use StreamSets Control Hub with Kubernetes to Start Multiple Data Collector Containers On Demand
If you have a Kubernetes cluster, you can use Control Hub’s Kubernetes Control Agent to spin up Data Collector containers on demand. Kubernetes offers a more modern, flexible clustering environment than YARN or Mesos, and can be deployed in your data center, or via a cloud provider such as Google Kubernetes Engine or Azure Kubernetes Service.
You can customize the publicly available StreamSets Data Collector Docker image for your configuration requirements. For example, you might need to modify the Data Collector configuration files, install external libraries, or add custom stage libraries. Use Docker to customize the public Data Collector Docker image and then store the custom image in your private Docker repository.
The control agent communicates with Control Hub to automatically provision Data Collector containers in the Kubernetes cluster in which it runs. Provisioning includes deploying, registering, starting, scaling, and stopping the Data Collector containers. A logical group of Data Collector containers is termed a deployment – all Data Collector containers in a deployment are identical and highly available. When you start a deployment, the control agent deploys the Data Collector containers, creating a Kubernetes pod to host each Data Collector container. The agent also registers each Data Collector container with Control Hub.
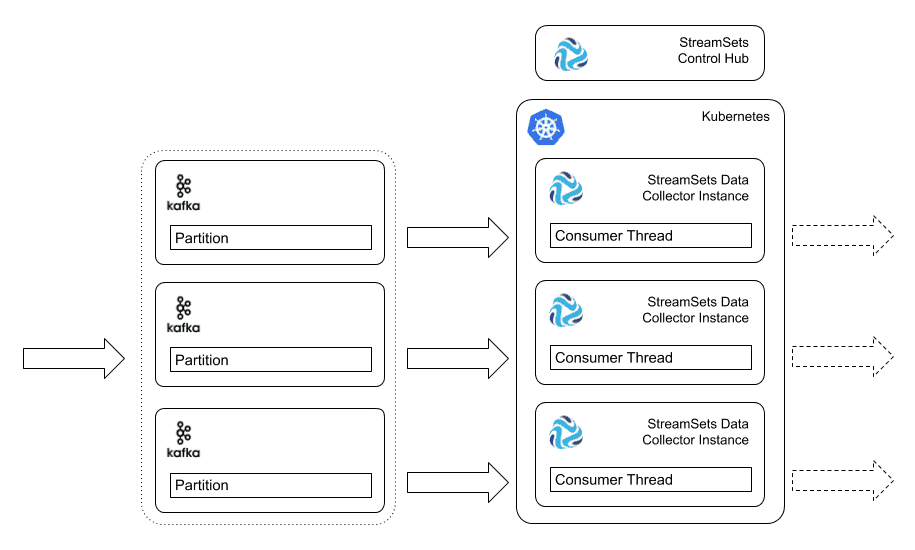
Although this solution sounds complex, once you have configured the control agent and deployment, Control Hub leverages Docker and Kubernetes to do the heavy lifting. It’s easy to scale Data Collector containers and update Data Collector containers to a new image with a different Data Collector version or different configurations. Failover is managed by Control Hub as in the previous case.
The Best of Both Worlds | Best Practices to Scale Kafka
The combination of StreamSets Control Hub, Docker and Kubernetes gives you the best combination of elasticity and flexibility. Watch the webinar, Five Ways to Scale Kafka, for more information and check out our Kafka solutions page for more resources.