 Jeff Schmitz has been working with big data for over a decade: at Shell, Sanchez Energy, MapR and, currently, as a senior solutions architect at MongoDB. Here, in a guest post reposted with permission from the original, Jeff shares his early experience with StreamSets Data Collector.
Jeff Schmitz has been working with big data for over a decade: at Shell, Sanchez Energy, MapR and, currently, as a senior solutions architect at MongoDB. Here, in a guest post reposted with permission from the original, Jeff shares his early experience with StreamSets Data Collector.
Now that I work for MongoDB I work with StreamSets quite a bit however a while back I was on a different journey at a customer site. We were struggling with picking an ETL tool. Many that we looked at were very pricey and required significant admin and resource time to manage. Luckily we found StreamSets…
StreamSets Data Collector allows you to set up a drag and drop ETL system within a few minutes. They offer a containerized (Docker) version, a tarball, or you can build manually from source if you wish. I strongly recommend using the Docker image. Data Collector has every origin and destination you can imagine, and processors in the middle for a wide variety of data transformations.
This really cool connected car demo utilizes a lot of the functionality, and should give you an idea what StreamSets looks like and feels like. We will step through building a more basic pipeline down below.
Pretty cool right? Lets build a basic pipeline using Data Collector now. The first step is to pull down the image from dockerhub… (this is assuming you have Docker installed)
jefferys-mbp:Desktop jefferyschmitz$ docker pull streamsets/datacollector Using default tag: latest latest: Pulling from streamsets/datacollector e20c4e30543a: Pull complete a5f9fc83acf6: Downloading [===========> ] 18.27MB/78.82MB 78a3db3b6dea: Download complete 14c4058c4e3b: Download complete c4cf8bd338cf: Downloading [==> ] 16.69MB/340MB d7bb309b44cf: Download complete 5c7a4ebae034: Download complete ae8b45618636: Download complete
Now that we have the Data Collector image you should be able to fire it up by running this command:
docker run --restart on-failure -p 18630:18630 -d --name streamsets-dc streamsets/datacollector dc
Now fire up your browser and cruise on over to http://localhost:18630/ and you should see a screen that looks like this:

Default username and password is admin / admin; this can be changed in the settings menu.
Once logged in you will see a pretty blank admin console. Let’s build a pipeline by clicking on “create new pipeline” in the upper left hand corner.
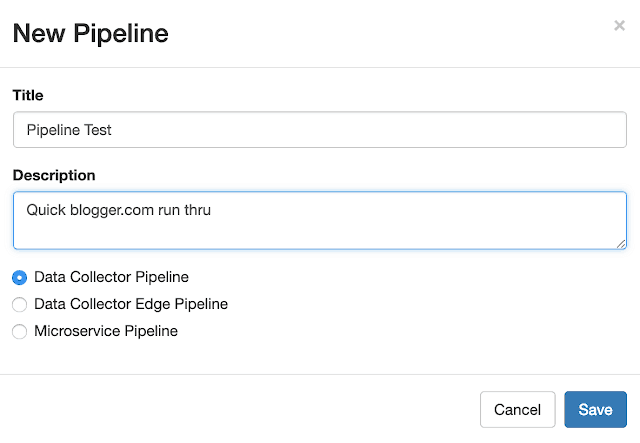
So we give a name and a description and off we go!
So now you will be presented with a screen that has no pipelines in it, so lets create a simple one. On the right side of the UI you will see a menu with Origins, Executors and Destinations. This is going to be the simplest pipeline you can create: we are going to select Origin and grab the SFTP widget and pull it into our pipeline creator. Then we are going to grab the Local FS destination and drag it over to the right of the SFTP origin then connect the two. The pipeline should look like this:
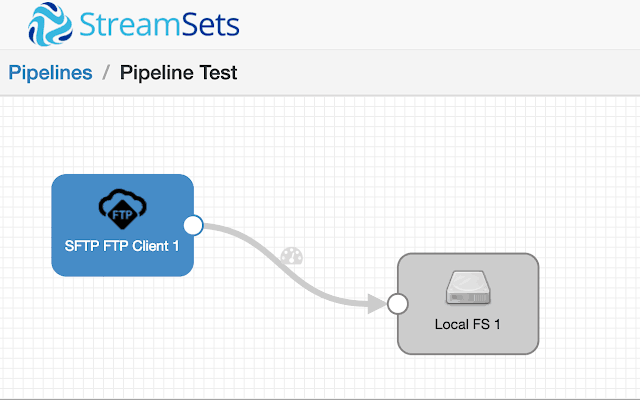
On the info line for both boxes make sure you fill out the proper configuration for each processing stage. Its pretty straightforward stuff like site url, password, data format – all must be filled out for each stage. You will see errors before running the pipeline if you missed something.
Once all your connections are setup, press the start button underneath the gears on the upper right hand side and data will start flowing from the SFTP client to the local FS.
StreamSets also has a great team behind the scenes that is quick to respond to feature requests with really fast turnaround times. Working with them is really a breath of fresh air!
Feel free to reach out to me with any questions you may have or contact StreamSets directly.
Happy Hacking!!!