![]() Updated November 29, 2021
Updated November 29, 2021
In a previous blog post, I explained how StreamSets Data Collector Engine (SDC) can work with Apache Kafka and Confluent Schema Registry to handle data drift via Avro schema evolution. In that blog post, I mentioned SDC’s Schema Generator processor; today I’ll explain how you can use the Schema Generator to automatically create Avro schemas.
We’ll use our old friend the Taxi tutorial pipeline as a basis, modifying it to write Avro-formatted data rather than a delimited data format. We’ll look at an initial native implementation, just dropping the Schema Generator into the data pipeline, then see how, with a little more work, we get a much better result.
Creating an Avro Schema
I’m starting with the basic Taxi tutorial pipeline. If you have not yet completed the tutorial, I urge you to do so – it really is the quickest, easiest way to get up to speed creating smart data pipelines.
For simplicity, let’s swap the Hadoop FS destination for Local FS, and set the data format to Avro. You’ll notice that we need to specify the Avro schema, somehow:
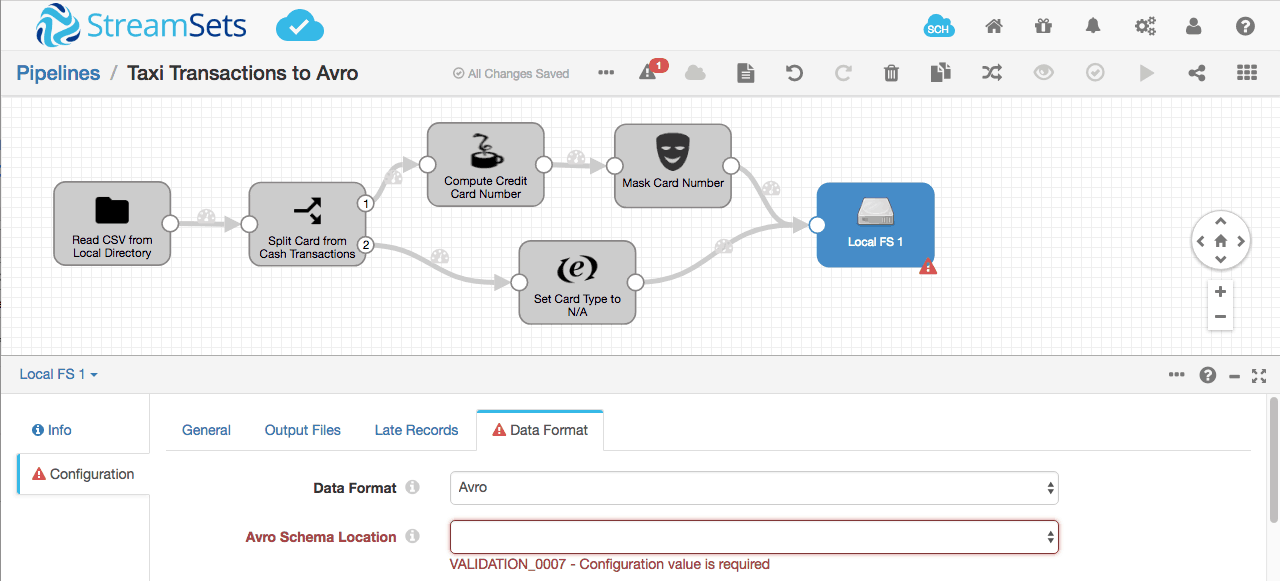
Let’s insert the Schema Generator processor just before the Local FS destination, and give the schema a suitable name:dzon
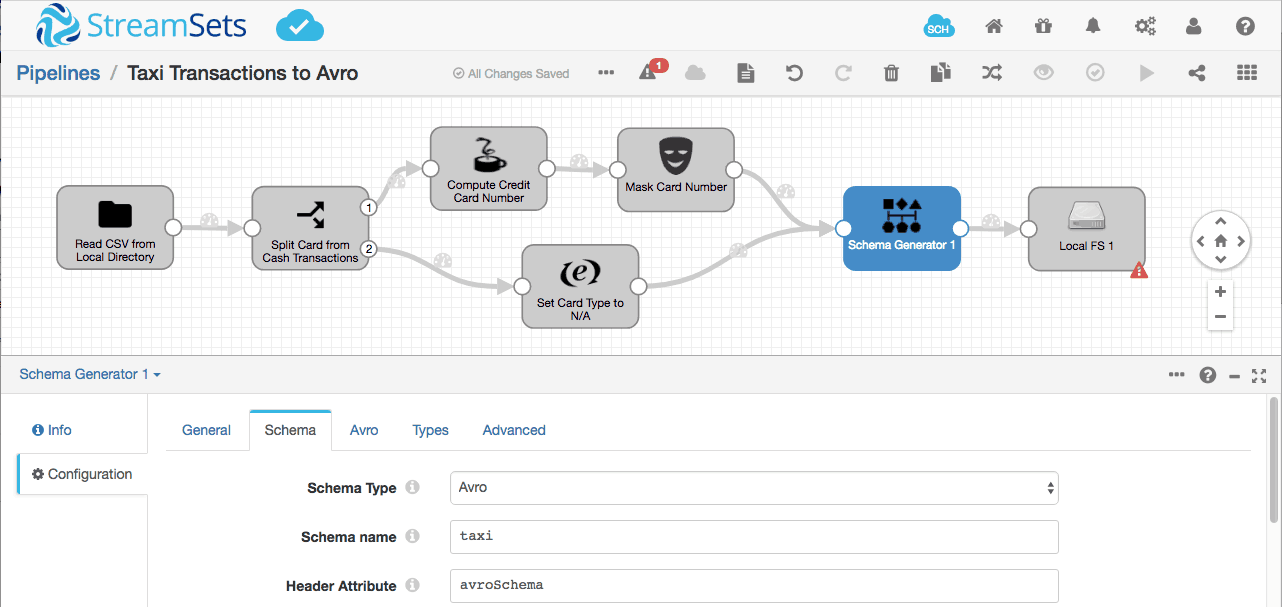
Notice that the Schema Generator processor puts the schema in a header attribute named avroSchema. We can now configure the Local FS destination to use this generated schema:
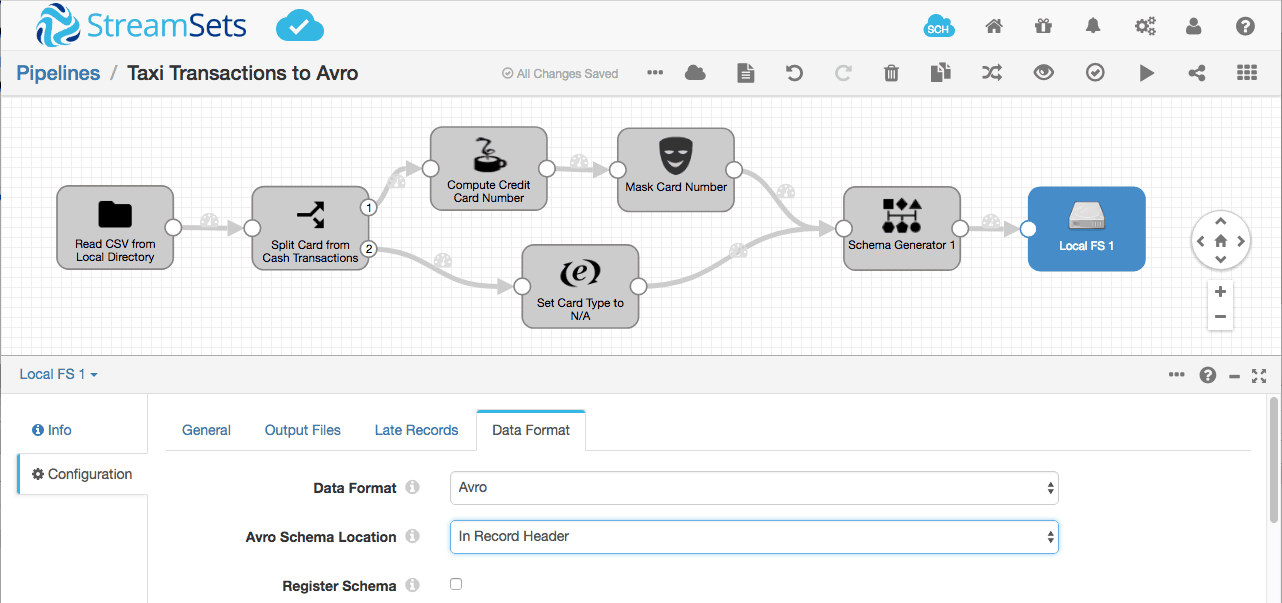
We can use preview to get some insight into what will happen when the pipeline runs. Preview will read the first few records from the origin, process them in the pipeline, but not, by default, write them to the destination. And enabling ‘Show Record/Field Header’ will allow us to see the Avro schema.
Preview is a great feature because when working with a diverse set of structured, semi-structured and unstructured data sources, it is imperative that you get a true sense of the data transformations at every stage. Not just to ensure data integrity and data quality, but also for debugging purposes. So phrases like “Garbage in, Garbage out”, “Fail fast, Fail often” and “Agile and Iterative development” are also applicable to creating smart data pipelines.
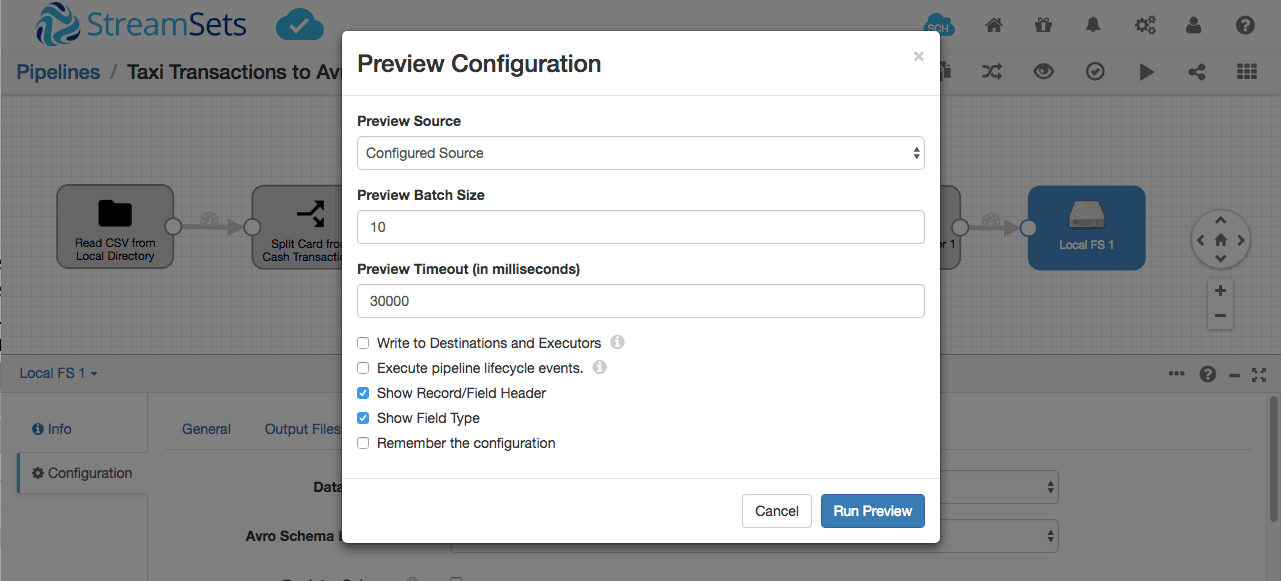
Selecting the Schema Generator and drilling into the first record, we can see the Avro schema:
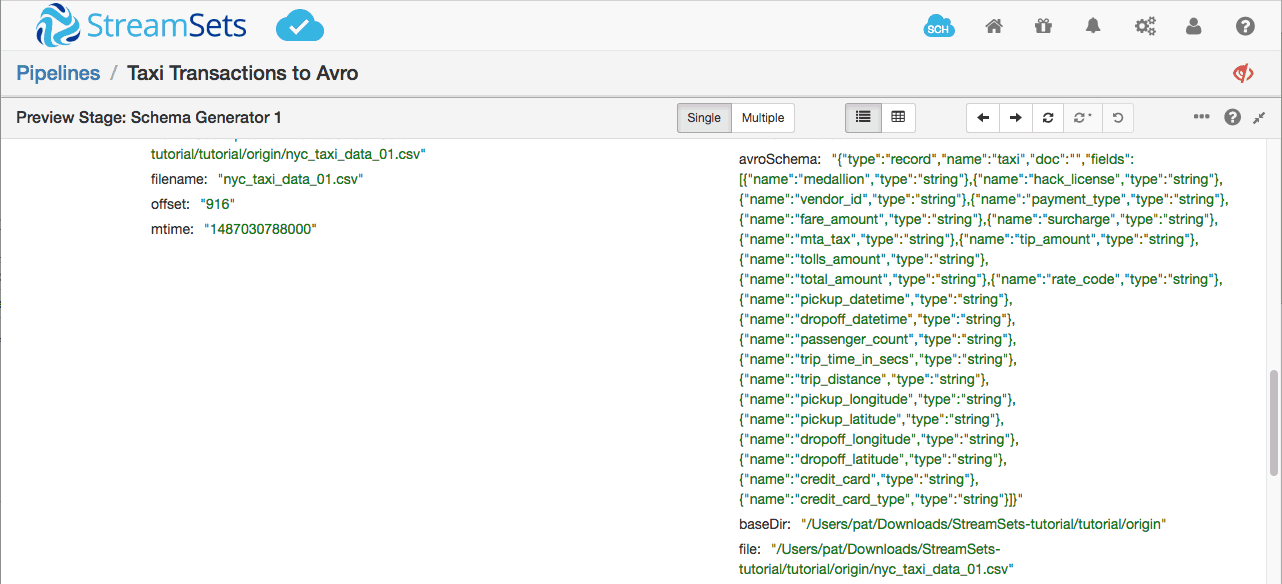
Let’s reformat the Avro schema so it’s more readable. I’ve removed most of the fields so we can focus on the key points:
{
"type": "record",
"name": "taxi",
"doc": "",
"fields": [
{
"name": "medallion",
"type": "string"
},
...
{
"name": "fare_amount",
"type": "string"
},
...
{
"name": "pickup_datetime",
"type": "string"
},
...
{
"name": "passenger_count",
"type": "string"
},
...
{
"name": "dropoff_latitude",
"type": "string"
},
...
]
}
StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.

Converting Field Types
The Schema Generator has created an Avro schema, but it’s likely not going to be very useful. Delimited input data (for example, data from CSV files) doesn’t have any type information, so all the fields are strings. It would be way more useful to have those datetimes as the corresponding type, the amount and coordinate fields as decimals, and it looks like trip_time_in_secs and passenger_count can be integers.
We can use the Field Type Converter processor to do the job:
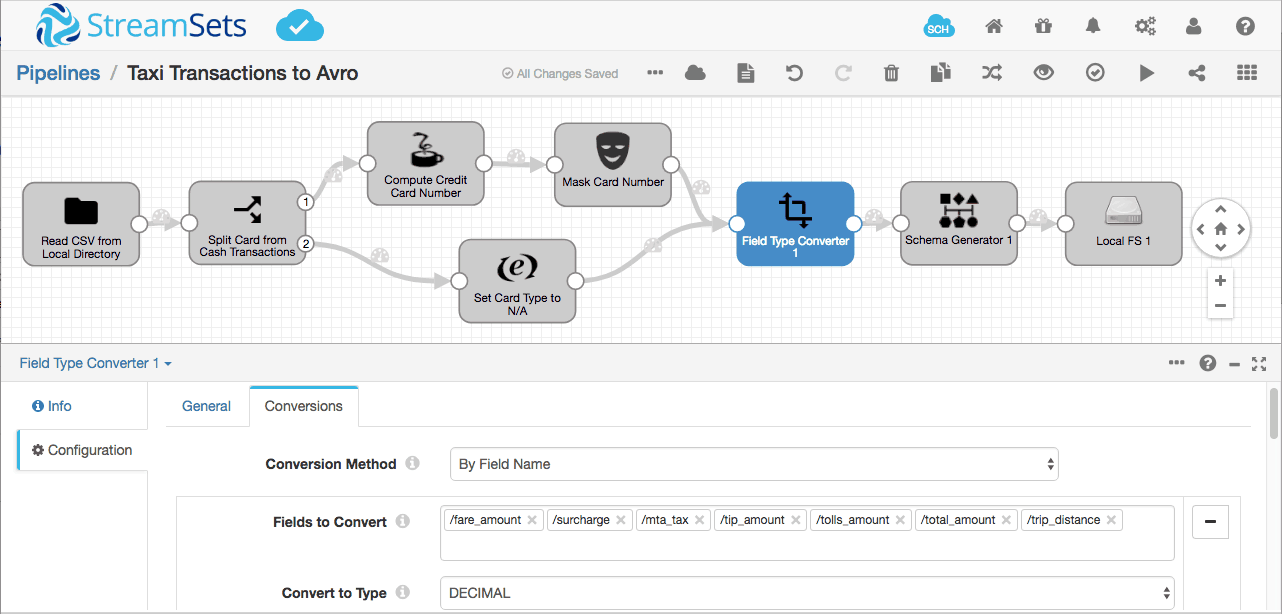
Previewing again, the schema looks much better, but we still have a little work to do. Notice that the Field Type Converter ‘guesses’ the precision for the decimal fields based on the values in each individual record:
{
"type": "record",
"name": "taxi",
"doc": "",
"fields": [
{
"name": "medallion",
"type": "string"
},
...
{
"name": "fare_amount",
"type": {
"type": "bytes",
"logicalType": "decimal",
"precision": 4,
"scale": 2
}
},
...
{
"name": "pickup_datetime",
"type": {
"type": "long",
"logicalType": "timestamp-millis"
}
},
...
{
"name": "passenger_count",
"type": "int"
},
...
{
"name": "dropoff_latitude",
"type": {
"type": "bytes",
"logicalType": "decimal",
"precision": 8,
"scale": 6
}
},
...
]
}
The precision attributes of the generated schemas will vary from record to record, but the schema needs to be uniform across all of the data. We can use an Expression Evaluator to set the field headers to override the generated precision attribute with sensible values for the entire data set:
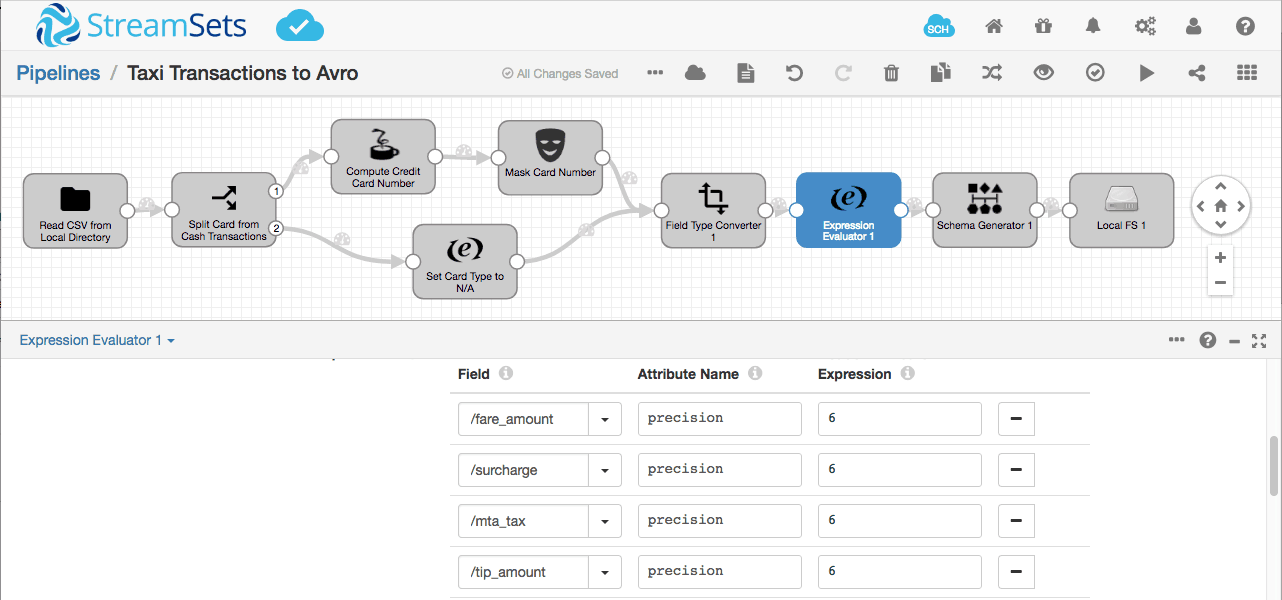
One last preview, and we can see that the schema is in good shape!
{
"type": "record",
"name": "taxi",
"doc": "",
"fields": [
{
"name": "medallion",
"type": "string"
},
...
{
"name": "fare_amount",
"type": {
"type": "bytes",
"logicalType": "decimal",
"precision": 6,
"scale": 2
}
},
...
{
"name": "pickup_datetime",
"type": {
"type": "long",
"logicalType": "timestamp-millis"
}
},
...
{
"name": "passenger_count",
"type": "int"
},
...
{
"name": "dropoff_latitude",
"type": {
"type": "bytes",
"logicalType": "decimal",
"precision": 10,
"scale": 6
}
},
...
]
}
Let’s run the pipeline and take a look at the output. I used Avro Tools to verify the schema and records in the output file from the command line (here’s a useful primer on Avro Tools).
$ java -jar ~/Downloads/avro-tools-1.8.2.jar getschema /tmp/out/2017-12-08-02/sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6_ec7d44fe-1afd-4c34-932f-ce375ae19348
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
{
"type" : "record",
"name" : "taxi",
"doc" : "",
"fields" : [ {
"name" : "medallion",
"type" : "string"
}, ... {
"name" : "fare_amount",
"type" : {
"type" : "bytes",
"logicalType" : "decimal",
"precision" : 6,
"scale" : 2
}
}, ... {
"name" : "pickup_datetime",
"type" : {
"type" : "long",
"logicalType" : "timestamp-millis"
}
}, ... {
"name" : "passenger_count",
"type" : "int"
}, ... {
"name" : "dropoff_latitude",
"type" : {
"type" : "bytes",
"logicalType" : "decimal",
"precision" : 10,
"scale" : 6
}
}, ... ]
}
As expected, that matches what we saw in the pipeline preview. Let’s take a look at the data:
$ java -jar avro-tools-1.8.2.jar tojson --pretty /tmp/out/2017-12-08-02/sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6_ec7d44fe-1afd-4c34-932f-ce375ae19348
log4j:WARN No appenders could be found for logger (org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
{
"medallion" : "F6F7D02179BE915B23EF2DB57836442D",
"hack_license" : "088879B44B80CC9ED43724776C539370",
"vendor_id" : "VTS",
"payment_type" : "CRD",
"fare_amount" : "\u0004°",
"surcharge" : "2",
"mta_tax" : "2",
"tip_amount" : "\u0000¯",
"tolls_amount" : "\u0000",
"total_amount" : "\u0005Ã",
"rate_code" : "1",
"pickup_datetime" : 1358080561000,
"dropoff_datetime" : 1358081162000,
"passenger_count" : 5,
"trip_time_in_secs" : 600,
"trip_distance" : "\u00018",
"pickup_longitude" : "ûå{",
"pickup_latitude" : "\u0002mV·",
"dropoff_longitude" : "ûò¶",
"dropoff_latitude" : "\u0002lí3",
"credit_card" : "xxxxxxxxxxxx2922",
"credit_card_type" : "Visa"
}
...
The strings and integers look fine, but what’s happened to the datetime and amount fields? Avro defines Logical Types for timestamp-millis, decimal and other derived types, specifying the underlying Avro type for serialization and additional attributes. Timestamps are represented as a long number of milliseconds from the unix epoch, 1 January 1970 00:00:00.000 UTC, while decimals are encoded as a sequence of bytes containing the two’s-complement representation of the unscaled integer value in big-endian byte order. The decimal fields in particular look a bit strange in their JSON representation, but rest assured that the data is stored in full fidelity in the actual Avro encoding!
Conclusion
The Schema Generator processor is a handy tool to save us having to write Avro schemas by hand, and a key component of the StreamSets Apache Sqoop Import Tool, but there is one caveat. The processor has no persistent state, so it can’t track the schema between pipeline restarts to ensure that the evolving schema follows Avro’s schema evolution rules. For this reason, you should not use the Schema Generator with drifting data – that is, when the incoming record structure may change over time.
If a car can drive itself and a watch can notify your doctor when your blood pressure goes up, why are you still specifying schemas and rebuilding pipelines? A smart data pipeline is a data pipeline with intelligence built in to abstract away details and automate as much as possible, so it is easy to set up and operate continuously with very little intervention. Try StreamSets DataOps Platform.