Today at StreamSets, we’re thrilled to announce the launch of our Public Preview of Transformer for Snowflake. By entering Public Preview, all users of the StreamSets Platform will be able to build and run transformation pipelines on Snowflake within minutes. Once you get started, you can continue to use the power of the platform to build end-to-end ingestion and transformation pipelines on Snowflake, all within a single user experience.
What is Transformer for Snowflake?
Transformer for Snowflake is a hosted service embedded within the StreamSets Platform that uses the Snowpark client libraries to generate queries that run directly on Snowflake. There’s nothing to deploy or manage. Just log in and begin building data pipelines on Snowflake.
- Use the familiar StreamSets pipeline design canvas to build transformations on Snowflake – no SQL required.
- Deploy your transformation pipelines alongside your ingestion pipelines to build an end-to-end data integration flow for Snowflake.
- Monitor the flow of your data pipelines and use dynamic tooling like subscriptions to alert you on the status of your jobs automatically.
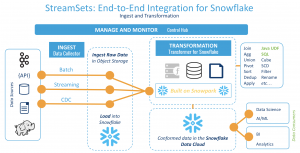
Running a pipeline is easy – just hit the run button, and the pipeline logic is passed through the Snowpark API. Snowpark generates the SQL, the query is sent to Snowflake, and the workload executes entirely on Snowflake’s backend in your Snowflake account.
You can also extend Transformer for Snowflake to apply user-defined functions and other third-party integrations to your transformations. Transformer for Snowflake can directly invoke any Snowflake UDF that you’ve already created or can create new Java UDFs for you on the fly.
Getting Started
To get started, simply log in to the StreamSets Platform, and then:
- Click on the User icon in the top right corner and navigate to My Account.
- You’ll see a new tab called Snowflake Settings. You can enter your Snowflake credentials there and define a default account URL, warehouse, database, schema, and role to use for all new pipelines.
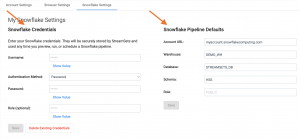
- Click on Quick Start (shown in the first screenshot above), and choose Create pipeline. You’ll navigate to the New Pipeline wizard, where you can choose a new option called Transformer for Snowflake. You can then click through, and you’ll drop into the pipeline design canvas to create a new pipeline.
- If you configured defaults in the second step, you’ll see pipeline parameters populated with the defaults specified above.
From there, you can drop a Snowflake origin onto the canvas and begin building transformations on Snowflake in minutes with no code required!
If a live walkthrough would help, check out our getting started video on YouTube.
What does Public Preview mean?
Public Preview means that you can use the functionality within the StreamSets Platform free of charge. You will only be limited by your account tier on the StreamSets Platform. All Transformer for Snowflake pipelines are deployed as jobs like all other StreamSets engines.
As a Preview, we expect some users will unearth bugs – so don’t put pipelines into production just yet. There are also elements of the user experience that will certainly evolve over time, and features that will be added in the coming months.
What Should I Do Next?
- Try the product! It’s free to get started.
- Give us feedback. We are very interested in your feedback. Please send any feedback to productfeedback@streamets.com. We will happily follow up to work through any issues that arise and provide more details on the roadmap plans for this component of the Platform.
- Lastly, join us at Snowflake’s Snowpark Snowday on April 21, 2022, where our partner engineer Kate Guttridge will be presenting an overview of how to build an end-to-end data integration pipeline on Snowflake with StreamSets.
Thanks and happy pipeline building!
