 Apache Pulsar is an open-source distributed pub-sub messaging system originally created at Yahoo, and a top-level Apache project since September 2018. StreamSets Data Collector 3.5.0, released soon after, introduced the Pulsar Consumer and Producer pipeline stages. In this blog entry I’ll explain how to get started creating dataflow pipelines for Pulsar.
Apache Pulsar is an open-source distributed pub-sub messaging system originally created at Yahoo, and a top-level Apache project since September 2018. StreamSets Data Collector 3.5.0, released soon after, introduced the Pulsar Consumer and Producer pipeline stages. In this blog entry I’ll explain how to get started creating dataflow pipelines for Pulsar.
Installing and Running Pulsar
It’s straightforward to install a standalone single node deployment of Pulsar for development and testing. I used Homebrew to install the Pulsar broker on my Mac:
brew tap streamlio/homebrew-formulae brew install streamlio/homebrew-formulae/pulsar
I then started the Pulsar broker as a Homebrew service with:
brew services start pulsar
Alternatively, you can download the Pulsar binary tarball and run it manually – just follow the instructions in the Pulsar documentation – or run it in Docker.
Note that, currently, Pulsar is only available for Linux and Mac.
Sending and Receiving Messages with the Pulsar Command Line Tool
I used pulsar-client to run a quick test from the command line before creating a pipeline in Data Collector. In one terminal window, I ran a consumer to listen for messages on a topic:
$ pulsar-client consume --subscription-name my-subscription --num-messages 0 my-topic ...much diagnostic output... 11:41:50.345 [pulsar-client-io-1-1] INFO org.apache.pulsar.client.impl.ConsumerImpl - [my-topic][my-subscription] Subscribed to topic on localhost/127.0.0.1:6650 -- consumer: 0
Note that the --subscription-name option is required for the consume command. A subscription is a named configuration rule that determines how messages are delivered to consumers, and corresponds to a Kafka consumer group. The blog post Comparing Pulsar and Kafka: unified queuing and streaming explains some of the similarities and differences between Pulsar and Kafka.
Pulsar will automatically create a subscription when it is first referenced, and similarly a topic when you attempt to listen or write to it. You can, alternatively, use the pulsar-admin command line tool to explicitly manage topics, subscriptions and more.
In another terminal window I ran a producer to write messages to that topic
$ pulsar-client produce my-topic --messages "hello-pulsar" ...much diagnostic output... 11:42:11.392 [main] INFO org.apache.pulsar.client.cli.PulsarClientTool - 1 messages successfully produced
Back in the consumer window:
... more diagnostics... ----- got message ----- hello-pulsar
Success! You might be wondering why I started the consumer before the producer. If you start the consumer with a new subscription, by default it will only receive messages sent since the subscription was created. So, if you push a message to the topic, then run the consumer for the first time, the consumer will not see that initial message, though it will see any that are subsequently sent. This is an important point to remember if you are experimenting with Pulsar and wondering why you aren’t seeing any messages!
Let’s send some more messages while the consumer is running. Running the producer again to send three messages:
$ pulsar-client produce my-topic --messages "biff","bang","pow"
Over at the consumer:
----- got message ----- biff ----- got message ----- bang ----- got message ----- pow
Using Data Collector’s Pulsar Consumer
Now that we understand the basics of Pulsar, it’s straightforward to build a pipeline to read a Pulsar topic. I used Data Collector’s Pulsar Consumer origin with the Local FS destination to simply read messages from a Pulsar topic and write them to a text file.
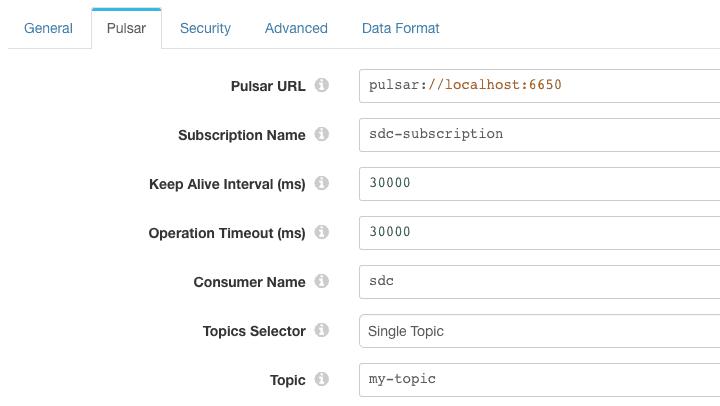
I configured the Pulsar Consumer origin to my-topic on the local broker with its own subscription, sdc-subscription, setting the consumer name to sdc:
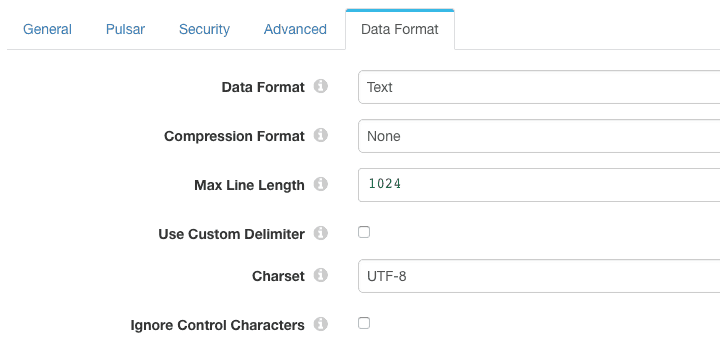
The Pulsar Consumer can parse a variety of other data formats including JSON, XML and delimited. To make it easy to consume messages created with the command line Pulsar client, I configured the origin’s data format to ‘Text’:
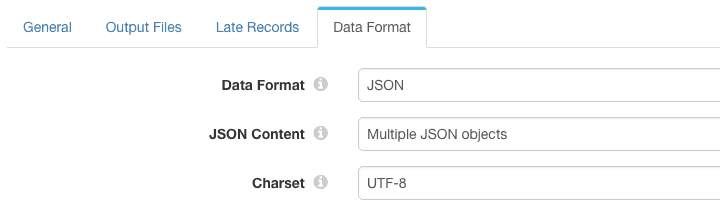
To make things a little more interesting, I configured the Local FS destination to write records to a file as JSON objects:
Before running the pipeline, I explicitly created its subscription, specifying that the subscription should start from the earliest available message. This way there was some data waiting for the pipeline to read on startup:
pulsar-admin topics create-subscription --subscription sdc-subscription \ --messageId earliest persistent://public/default/my-topic
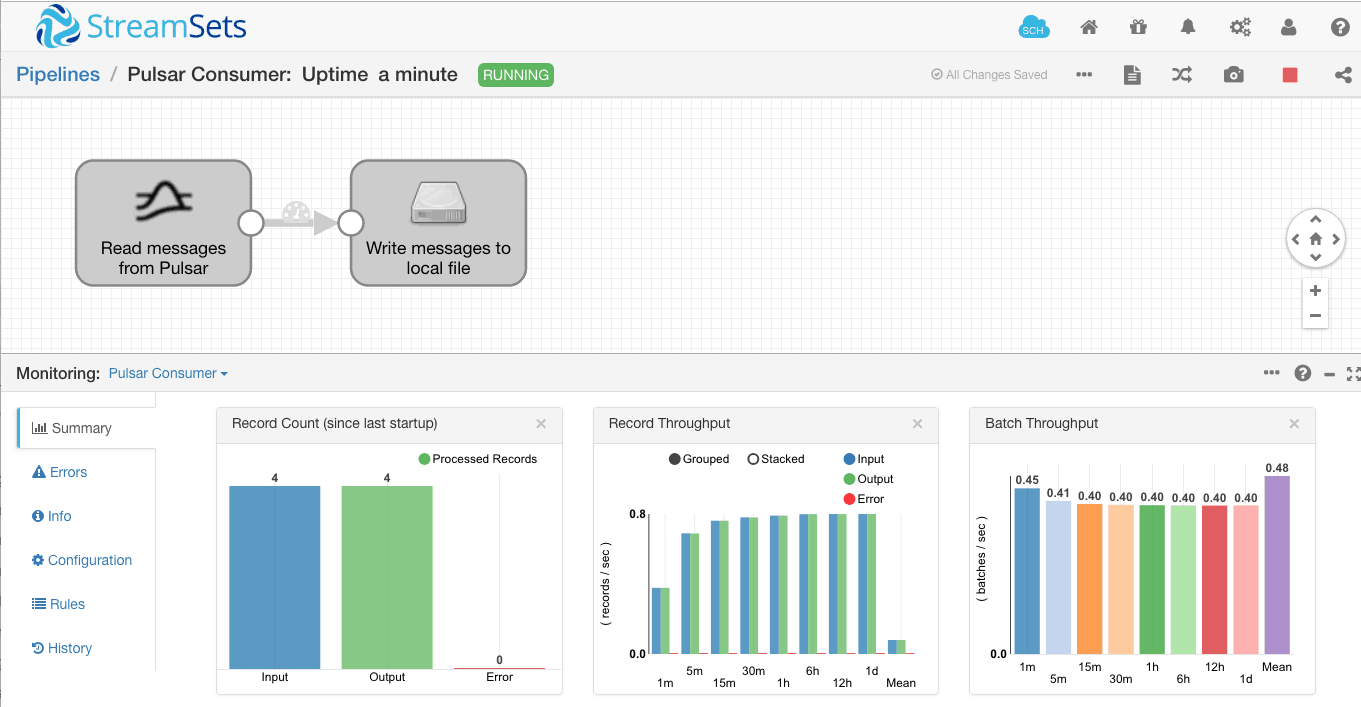
Now, starting the pipeline, we see that the existing four messages are immediately processed:
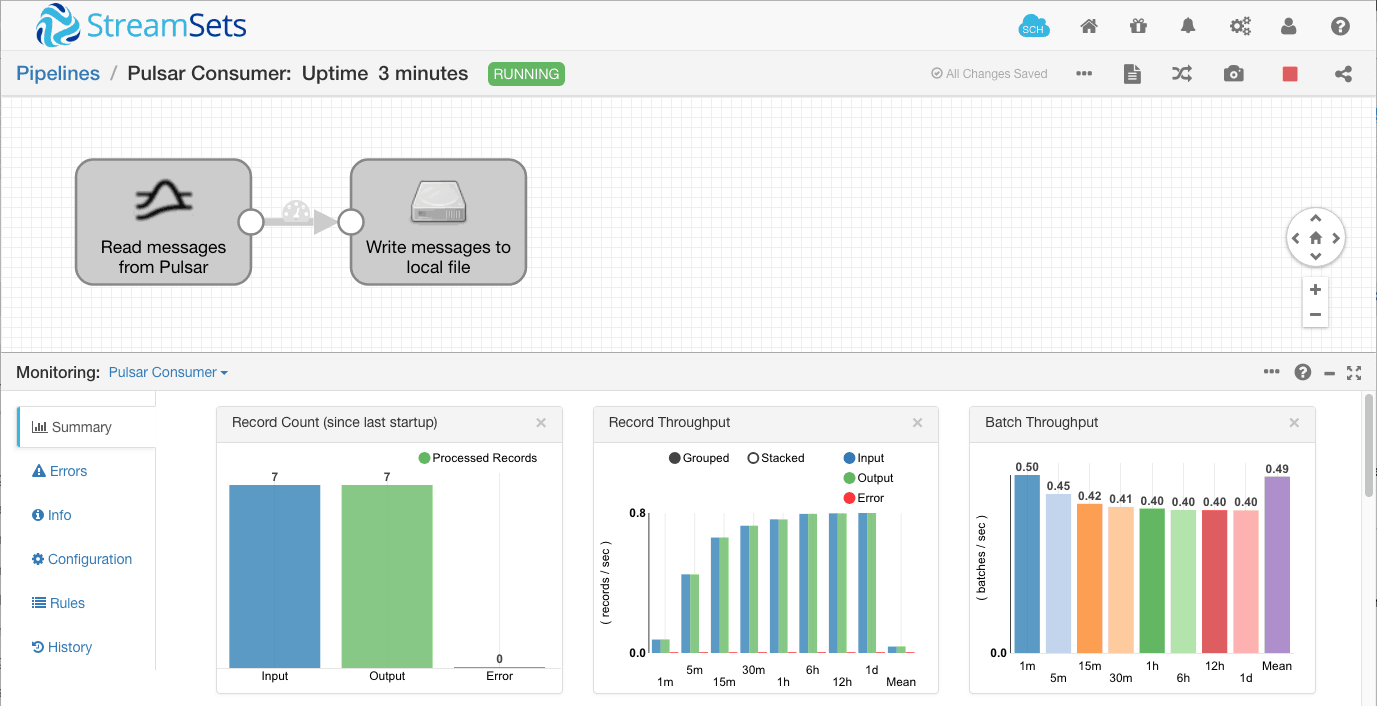
Pushing another three messages into the Pulsar topic has the expected result – we can see that the record count has risen to seven:
Looking in the output file, we can see the seven messages written out in JSON format:
$ cat /tmp/out/2018-12-07-22/_tmp_sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6_0
{"text":"hello-pulsar"}
{"text":"biff"}
{"text":"bang"}
{"text":"pow"}
{"text":"biff"}
{"text":"bang"}
{"text":"pow"}
Writing data with Data Collector’s Pulsar Producer
I created another simple pipeline, this time to write random data to the Pulsar topic using the Pulsar Producer destination:
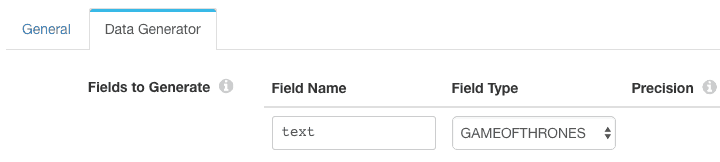
Just for fun, I set the Dev Data Generator’s field type to GAMEOFTHRONES. This will use the Java Faker library to generate random character names from Game of Thrones:
The Pulsar Producer writes to my-topic on the local broker:
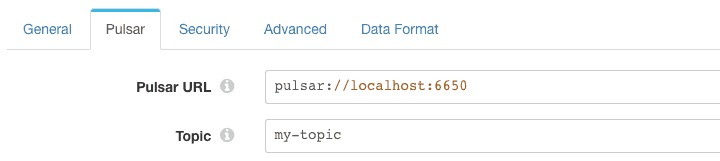
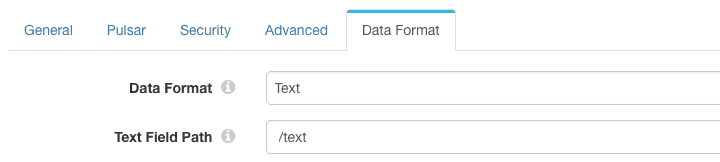
The Pulsar Producer data format is set to ‘Text’, so that it will send the content of the /text field as the Pulsar message.
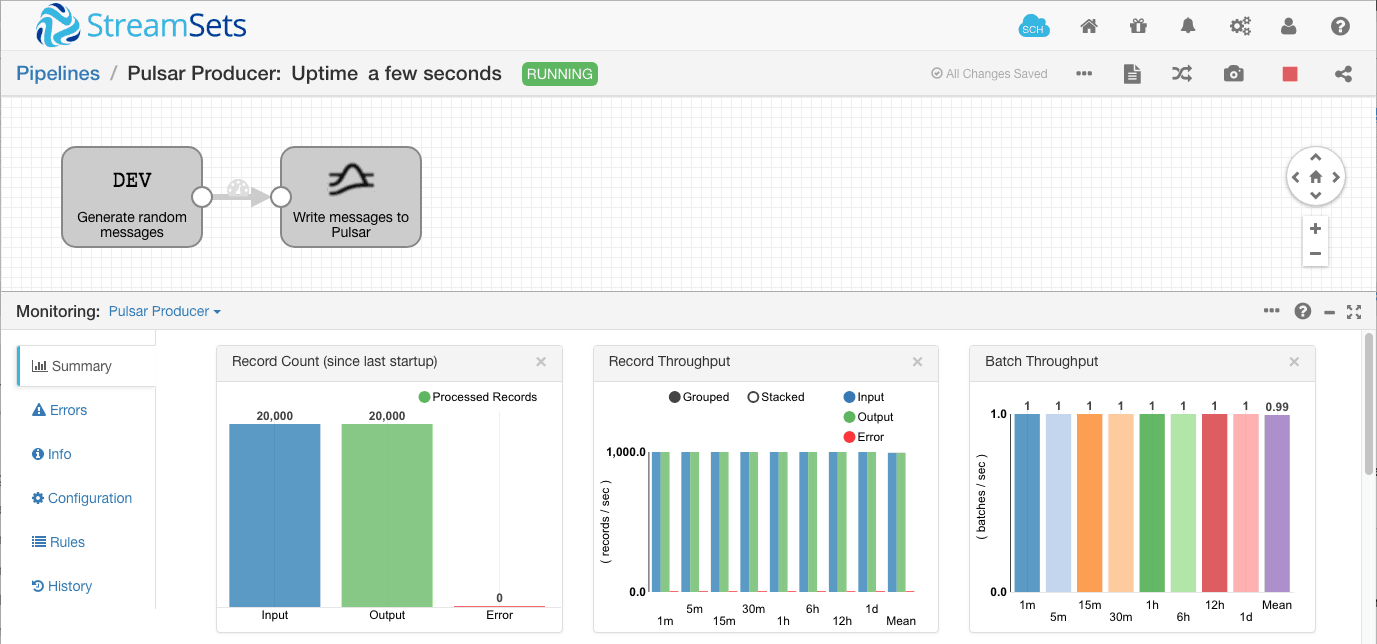
Running the pipeline results in a batch of 1000 records being sent to the Pulsar topic every second:
We can see the messages over in the Pulsar consumer command line client. Here’s a short sample:
----- got message ----- Danelle Lothston ----- got message ----- Hotho Harlaw ----- got message ----- Devyn Sealskinner ----- got message ----- Walder Haigh ----- got message ----- Reznak mo Reznak ----- got message ----- Cadwyn ----- got message ----- Robin Moreland ----- got message ----- Nella ----- got message ----- Cleon ----- got message ----- Dontos Hollard
Back in the consumer pipeline, we can see the messages being processed:
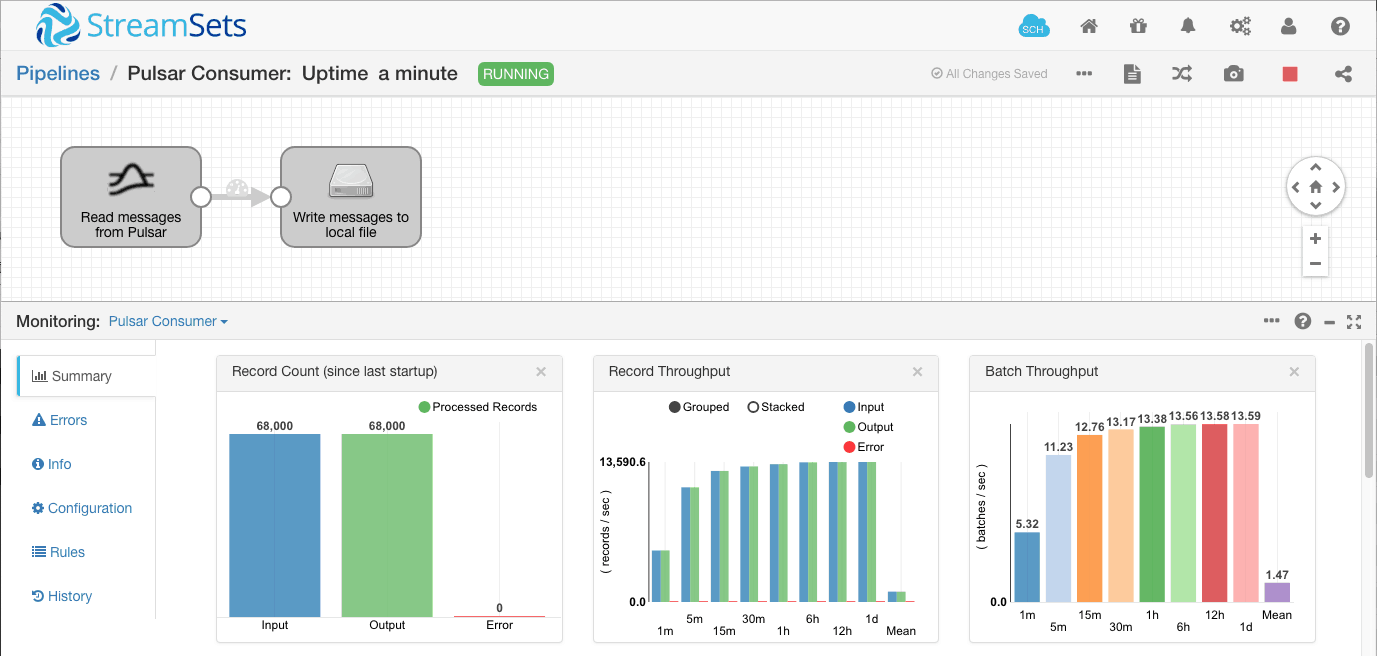
Looking at the output file, we can see the JSON-formatted data:
$ tail /tmp/out/2018-12-07-23/_tmp_sdc-24e75fba-bd00-42fd-80c3-1f591e200ca6_0
{"text":"Danelle Lothston"}
{"text":"Hotho Harlaw"}
{"text":"Devyn Sealskinner"}
{"text":"Walder Haigh"}
{"text":"Reznak mo Reznak"}
{"text":"Cadwyn"}
{"text":"Robin Moreland"}
{"text":"Nella"}
{"text":"Cleon"}
{"text":"Dontos Hollard"}
Success! We’re generating text data and sending it to the Pulsar topic in the Pulsar Producer pipeline while reading it from the topic and writing it to disk in JSON format in the Pulsar Consumer pipeline.
Conclusion
It’s easy to run a standalone single node deployment of Apache Pulsar for local development and testing. The pulsar-client command line tool is a handy mechanism for reading and writing messages to Pulsar topics, and StreamSets Data Collector’s Pulsar Consumer and Pulsar Producer pipeline stages allow you to quickly build dataflow pipelines to send and receive data via Pulsar topics.