![]() Minneapolis-based phData has long been a StreamSets partner, deploying the StreamSets DataOps Platform at customers across the US. It’s not surprising then, that when phData principal solutions architect Keith Smith wanted to integrate the Ethereum blockchain platform with the Apache Hadoop filesystem and Apache Kudu, he reached for StreamSets Data Collector.
Minneapolis-based phData has long been a StreamSets partner, deploying the StreamSets DataOps Platform at customers across the US. It’s not surprising then, that when phData principal solutions architect Keith Smith wanted to integrate the Ethereum blockchain platform with the Apache Hadoop filesystem and Apache Kudu, he reached for StreamSets Data Collector.
His first dataflow pipeline read Ethereum transaction data from the infura.io API via Data Collector’s HTTP Client origin. This worked well, retrieving the most recent transaction block, archiving it into the Hadoop filesystem, and breaking each block into individual records using the Field Pivoter processor, inserting the records into Kudu for analysis.
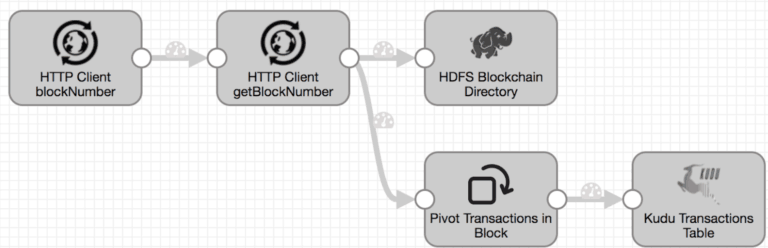
Although this implementation was functional, it wasn’t robust. If the pipeline was stopped and restarted for any reason, transaction blocks generated during the downtime might be missed. Keith then went on to create a custom Data Collector origin able to track block numbers and retrieve any missed blocks on pipeline restart.
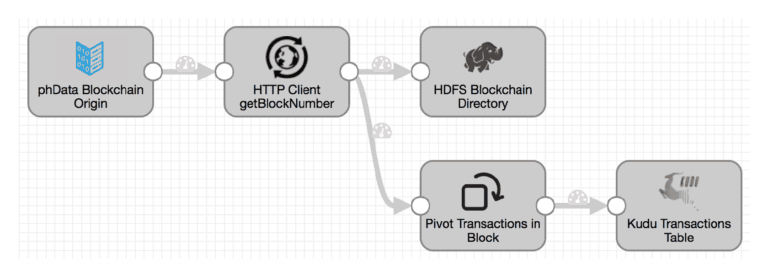
Once the data is in Kudu, it can be mined for insights such as finding the products with the highest amount of transactions since a given date, drilling into the transaction data to retrieve product details. Keith goes into the use case and analysis in much more detail in his article on the phData blog: Hadoop meets Blockchain: Trust your (Big) Data.
Have you put StreamSets Data Collector to use in a novel application? Let us know in the comments!