Overview
You have options when bulk loading data into RedShift from relational database (RDBMS) sources. These options include manual processes or using one of the numerous hosted as-a-service options.
But, if you have broader requirements than simply importing, you need another option. Your company may have requirements such as adhering to enterprise security policies which do not allow opening of firewalls. They might have a need to operationalize and automate data pipelines, masking, encryption or removal of sensitive information such as PII before landing in RedShift. In this case, your best option to use is StreamSets.
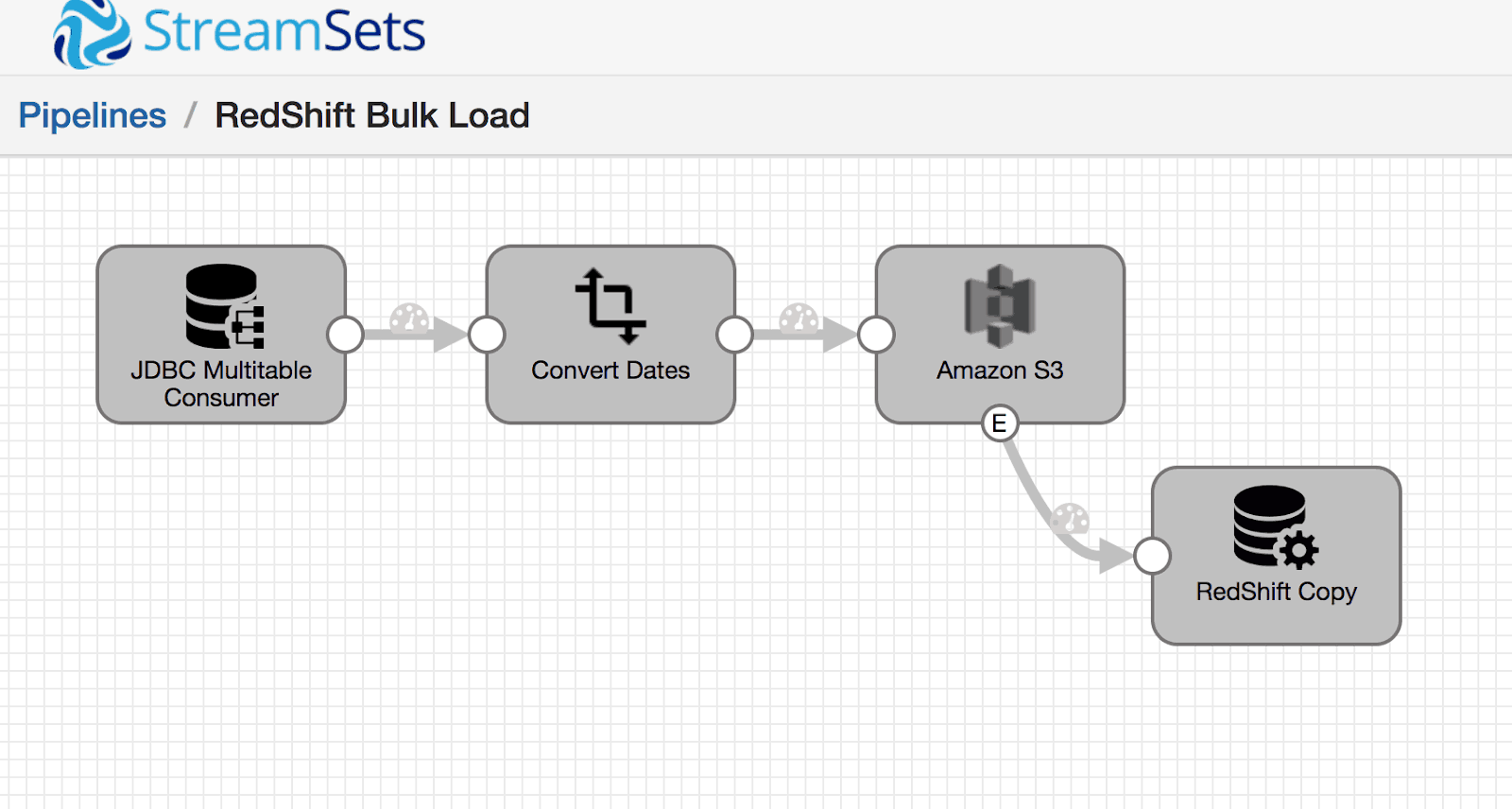
This tutorial will show how to load data into RedShift from a relational database (RDBMS) with StreamSets Data Collector. (Also included is a template pipeline to use with StreamSets Control Hub in case you are a StreamSets customer or Control Hub evaluator.) In future tutorials, we can cover how to perform near real-time or also known as “trickle” updates to RedShift with StreamSets Change Data Capture (CDC) sources.
This tutorial uses MySQL for the RDBMS, but you can substitute any RDBMS such as Oracle, SQL Server, or Postgres if there is a JDBC driver available.
We’ll also cover an introductory example of performing transformations to prepare your data for RedShift. StreamSets offers many ways to transform data such as field masking and PII detection when being streamed into RedShift, but we’ll leave that for another time.
At the end of this tutorial there are links to various references which should help get your environment up-and-running. References include SQL scripts for RedShift setup, a StreamSets pipeline to import, and a screencast of sections in this tutorial.
If you have any questions, comments or ideas for improvement, please visit our community page.
Approach
If there are multiple approaches to load data into RedShift, you might be wondering, what does Amazon recommend for data ingest?
Amazon recommends either Kinesis Firehose or landing data in S3 and then using the `COPY` command. You can implement either option in StreamSets Data Collector.
In this tutorial, we’re going to land our data in S3 and then use the `COPY` command. You may check the AWS RedShift documentation for further information on the COPY command.
For the overall sequence of events in the tutorial, we’re going start with setup requirements. Next, we’ll move on to importing the skeleton StreamSets pipeline and customizing it for your environment.
Requirements
In order to complete this tutorial, you will require the following
- Amazon Web Services (AWS) account with
- read/write access to S3 bucket
- read/write access to RedShift cluster
- MySQL
- StreamSets Data Collector version 3.4 or above or
- Optional – StreamSets Control Hub with Data Collector 3.4 or above
- JDBC drivers
Assumptions
This tutorial assumes familiarity with all the requirements in this tutorial. You don’t need to be an expert by any means, but it may be difficult if any of these requirements are completely new to you. In particular, if you are new to StreamSets Data Collector, I highly recommend you complete the excellent tutorial in the Data Collector documentation before attempting to ingest data into Amazon RedShift.
Setup
Assuming you meet all the requirements, we’ll now cover the steps needed for each.
RedShift
Log on to your RedShift Cluster with a SQL client and create the destination tables. For this tutorial, I followed the Amazon RedShift instructions for SQL Workbench/J setup here
Next, create the tables where we land the data. These tables have the same columns as the MySQL source, but the RedShift DDL has been modified to be appropriate for RedShift.
MySQL
In this tutorial, we use the sample Employees database available from https://dev.mysql.com/doc/employee/en/
Follow the instructions to download and recreate in your environment.
AWS S3
Nothing really special here. You just need access to a bucket and appropriate permissions.
StreamSets Data Collector
It doesn’t really matter where you run Data Collector for this tutorial as long as you are able to install the MySQL and Amazon RedShift JDBC drivers and can access S3 and RedShift. This tutorial should run fine with Data Collector running on your laptop.
Run the StreamSets data pipeline to bulk load to RedShift
In the following screencast, the necessary configuration changes and running the data pipeline is demonstrated.
Advanced Considerations
Depending on the size of files landed on S3, you may experience slower than expected performance. Writing many, small files to distributed file systems such as S3, HDFS, Google Cloud Storage, etc. is a fairly well known issue regardless of Amazon RedShift and StreamSets performance. If this is a known issue, you may be wondering if we have any options to best position ourselves against possible performance implications? In StreamSets, there are a few options to create and land larger files to S3.
- Increase Max Batch Size in the JDBC Multitable Origin and keep in mind the following
- Check
production.maxBatchSize in etc/sdc.properties
(or equivalent in Cloudera Manager) – the value in sdc.properties is the absolute maximum batch size for the Data Collector instance.
- With higher Max Batch Size values you may need to adjust JVM max heap size
- With larger heaps, you might benefit from changing JVM garbage collector from the default of CMS to G1GC
- Check
- Create a two pipeline approach to utilize the Whole File Transformer and load much larger files to S3, since RedShift supports the Parquet file format. This may be relevant if you want to use Parquet files outside of RedShift.
If you are curious, we can cover these options in a later tutorial or contact our team to speak with an expert.
Conclusion
This tutorial demonstrated how to synchronize a relational database to Amazon RedShift. The intention is to jumpstart your efforts using StreamSets Data Collector, a fast data ingestion engine, and Amazon RedShift.
Also, checkout the new tutorial on CDC to RedShift.
Learn more about building data pipelines with StreamSets, how to process CDC information from Oracle 19c database and StreamSets for Amazon Web Services.