StreamSets Data Collector is available in the major cloud marketplaces; as an AWS Marketplace vendor, StreamSets has access to a number of data sets detailing product usage and billing. Data sets are available interactively via a web portal and via the AWS Marketplace Commerce Analytics Service (MCAS) API. While the individual reports are useful, it would be even more valuable to store the data in a relational database or data warehouse for dashboards and ad-hoc queries. In this blog entry, I’ll explain how I built a pair of data pipelines with StreamSets Data Collector to ingest AWS MCAS data sets into MySQL on Amazon RDS.
This is a great example of a real-world use case implemented in Data Collector. I’ve included short videos illustrating key points. Feel free to skip them on first reading, then return to them for a deeper understanding.
AWS Marketplace Commerce Analytics Service
On receiving a request for an analytics data set, the AWS SDK delivers a CSV-formatted object via Amazon S3. There are currently 21 different data sets listed in the AWS documentation, published on a variety of schedules from daily to monthly.
AWS MCAS Data Sets
Most of the MCAS data sets have the same standard CSV format. Here’s a sample of a typical data set, sales_compensation_billed_revenue.
| Customer AWS Account Number | Country | State | City | Zip Code | Email Domain | Product Code | Product Title | … |
| 1234-5678-9012 | US | TX | DALLAS | 77777 | example.com | dfkjlerfklw | Acme Widget | … |
| 3282-3616-7894 | GB | London | EC1N 1AA | example.net | dfkjlerfklw | Acme Widget | … | |
| 1111-2222-3333 | US | CA | San Jose | 95125 | example.org | dfkjlerfklw | Acme Widget | … |
| … | … | … | … | … | … | … | … | … |
A few of the data sets are a little different. Four of the disbursement reports have an additional row of text about the column headers; here’s disbursed_amount_by_age_of_disbursed_funds:
| Age of Disbursed Funds (in USD) | |||||
| Collected (< 31 days pending) | Collected (31-60 days pending) | Collected (61-90 days pending) | Collected (91-120 days pending) | Collected (> 120 days pending) | Collected (overall) |
| 1.23 | 2.34 | 3.45 | 4.56 | 5.67 | 17.25 |
Two of the reports have a summary/detail format; for example, disbursed_amount_by_customer_geo:
| Settlement ID | Settlement Period Start Date | Settlement Period End Date | Deposit Date | Disbursed Amount | Country Code | State or Region | City |
| abcd1234 | 2019-07-03 21:07:02 UTC | 2019-07-10 22:12:16 UTC | 2019-07-10 23:20:13 UTC | 999.99 | |||
| US | CA | San Jose | |||||
| US | NY | New York | |||||
| US | IL | Chicago | |||||
| US | FL | Orlando |
I challenged myself to write the minimum number of pipelines to ingest all twenty one reports. As a teaser, here’s one of the data pipelines I created:
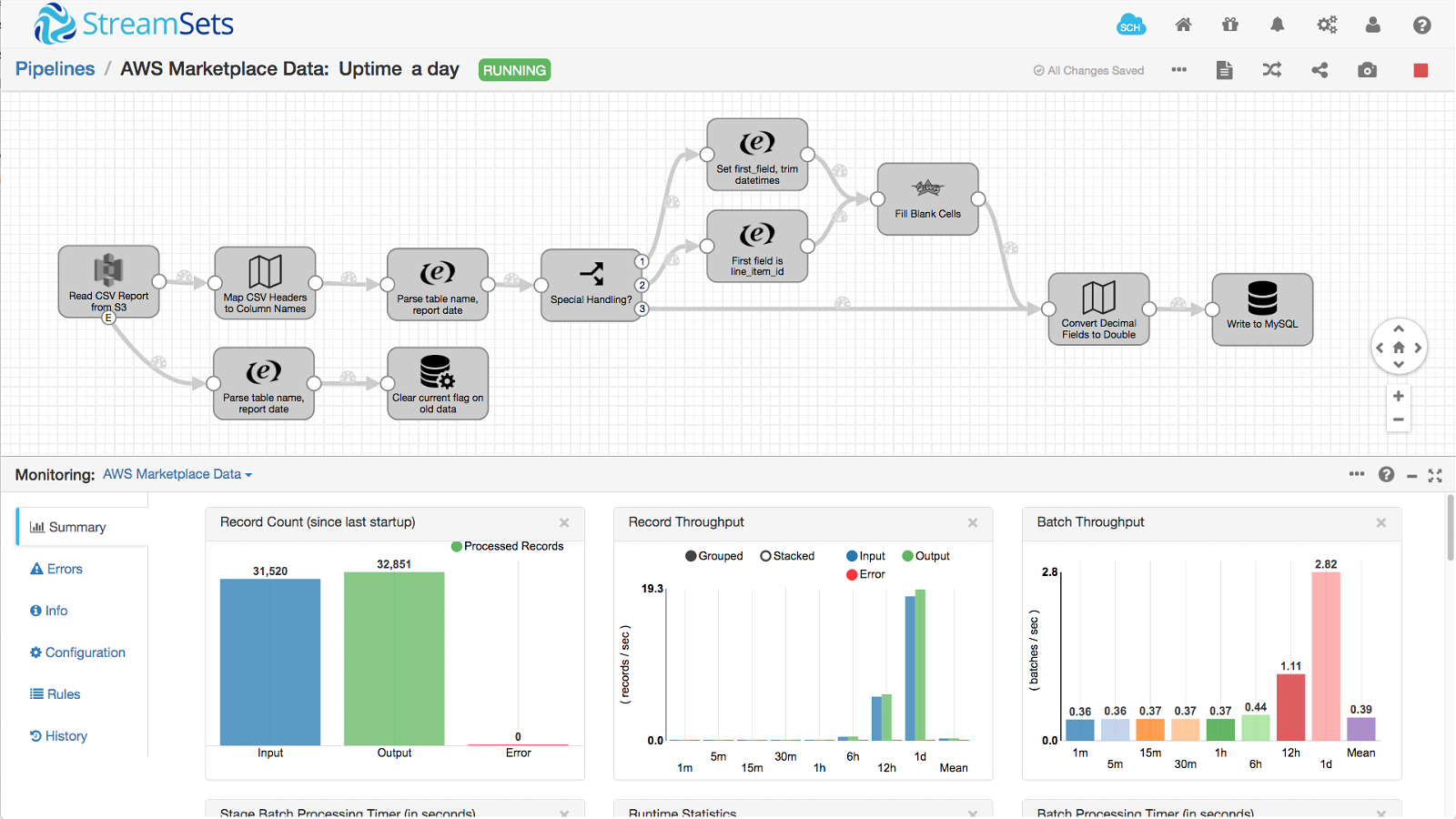
Generating AWS Marketplace Commerce Analytics Service Data Sets
Given a data set’s type and publication date, the generate-data-set command asynchronously publishes a data set to the specified S3 bucket and notifies an SNS topic once the data is available. AWS Lambda functions are ideal for automating small, regular tasks like this, so I wrote a Python function to generate all of the available reports for the current day. The function is triggered by an AWS CloudWatch Events Application, running daily at 00:30 UTC, half an hour after publication time.
Ingesting CSV Data from Amazon S3
StreamSets Data Collector’s Amazon S3 origin retrieves and parses data from S3 objects. The origin reads any existing objects that match its configuration and then continues to monitor the S3 bucket for new data, ingesting objects as they become available.
The S3 origin supports many data formats, including comma-separated values (CSV). My first task was to create a pipeline with the S3 origin to read the data sets, but previewing one of the four disbursement reports revealed an error:

The origin is interpreting the initial row of text as a single column header, and then complaining that the next row has more than one column. Fortunately, it’s an easy fix: configure the origin to skip the first row of data:
I now needed two pipelines, one for the four disbursement data sets and another for the remaining seventeen. Would I need any more?
The next snag I hit was that missing CSV values were interpreted as empty strings. I wanted them to be NULLs in my database, so I set the S3 origin accordingly:
Transforming Data in StreamSets Data Collector
The column headers in the data sets are very readable, for example “Collected (31-60 days pending)”, but it’s not best practice to create relational database tables with mixed case names and non-alphanumeric characters. I configured Data Collector’s Field Mapper processor to apply an expression to every field name in every record:
${str:replaceAll(
str:replace(
str:replace(
str:replace(
str:replaceAll(
str:toLower(f:name()),
'[ \\-]',
'_'),
'#',
'number'),
'<',
'under'),
'>',
'over'),
"[\\'\\.\\(\\)]",
'')}
This converts “Collected (31-60 days pending)” to a much more RDBMS-friendly collected_31_60_days_pending. I pick the expression apart in this short video:
Note that this approach works across all of the data sets; I still only need two pipelines…
Manipulating Metadata in StreamSets Data Collector
The S3 object names have the form {data_set_name}_{effective_date}.csv. For example, us_sales_and_use_tax_records_2020-02-15.csv. Enabling ‘Include Metadata’ in the S3 origin causes the object key and other metadata to be included as header attributes with each record. I constructed a regular expression to match the data set name and effective date in the S3 object key:
/\w*?_\d{4}-\d{2}-\d{2}.csv
Data Collector’s str:regExCapture Expression Language function extracted the data set name and effective date, allowing me to include that metadata with each record:
Routing Records in StreamSets Data Collector
I avoided creating more pipelines to handle the summary/detail reports by using a Stream Selector to route records depending on the data set name:
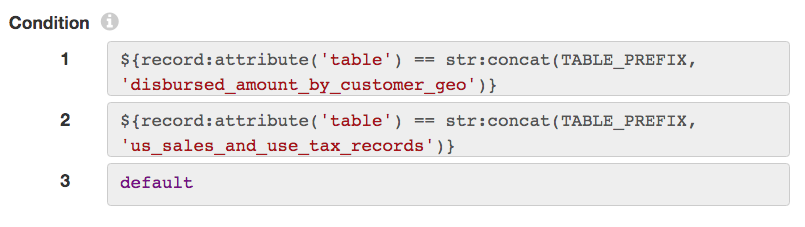
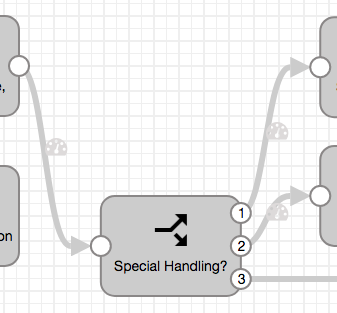
None of the four disbursement data sets deviate from the default CSV format, so they didn’t need any special processing.
Custom Data Processing in StreamSets Data Collector
I handled the two summary reports by identifying a ‘key’ field that was only present in the summary rows and referencing it in a Groovy Evaluator script. The script identified the summary rows, saved them, and copied the summary data into the empty fields in the detail rows:
When I wrote the data to MySQL (you can also use MySQL as an origin), it was almost correct, but currency values were wrong: instead of 1.23, the database showed 1.00. The MySQL JDBC driver seemed to be stopping at the decimal point as it parsed strings to numeric values. The quickest fix was to simply convert all decimal strings to DOUBLE data type in the pipeline. I used Field Mapper again to convert any field values that looked like decimals:
Trigger Database Updates from Events in StreamSets Data Collector
A current column in each MySQL table gave me an efficient way to extract the most recent data set. It was easy to set current in new records, but how could I clear the flag on existing data? Data Collector origins can emit event records when they, for instance, finish reading a file. Given the data set name and effective date, it was easy to configure the JDBC Query executor to clear the current flag on old rows:
UPDATE ${record:value('/table')}
SET current = 0
WHERE current <> 0
AND effective_date < '${record:value('/effective_date')}'
Intent-Driven Data Pipelines
Data Collector’s pipelines are intent-driven rather than schema-driven. With twenty one different data sets across our two pipelines, if we had to manually map fields from CSV to RDBMS we might need a pipeline per data set and a lot of tedious clicking and dragging. As it is, we’ve avoided explicitly naming data sets and columns as far as possible. In most cases, we don’t even need to know these in advance of building the pipeline.
By creating MySQL tables and columns with appropriate names, I configured the JDBC Producer destination identically for all of the data sets. The table name is simply the data set name parsed from the S3 object key:

I didn’t need to specify any field/column mappings – the destination automatically matched them up:
Final Score: Two Pipelines to Process Twenty One Data Sets!
By applying the intent-driven approach, I was able to process all twenty one data sets with just two pipelines; one for the four disbursement reports and another for the remaining seventeen data sets, summary/detail reports and all:
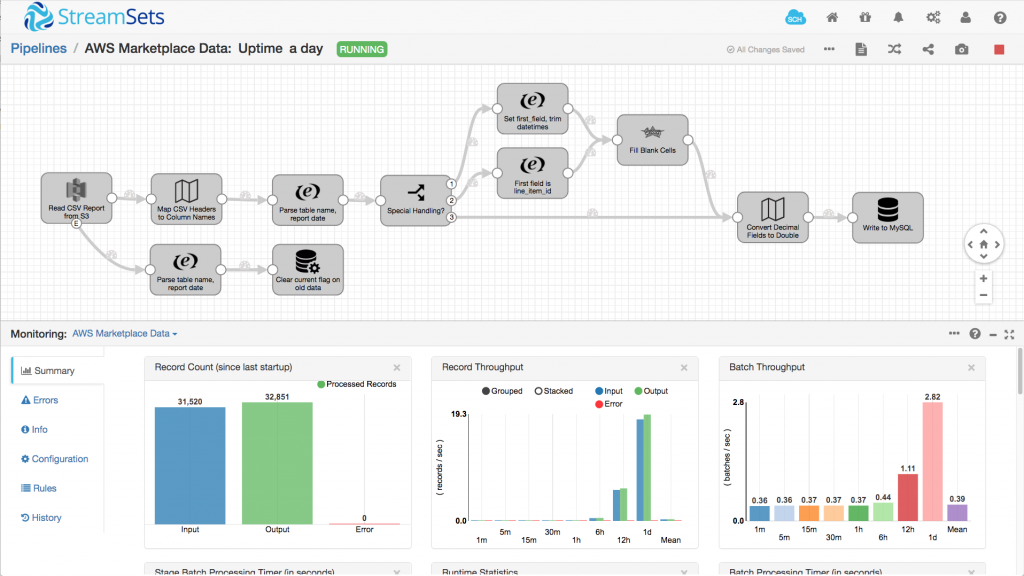
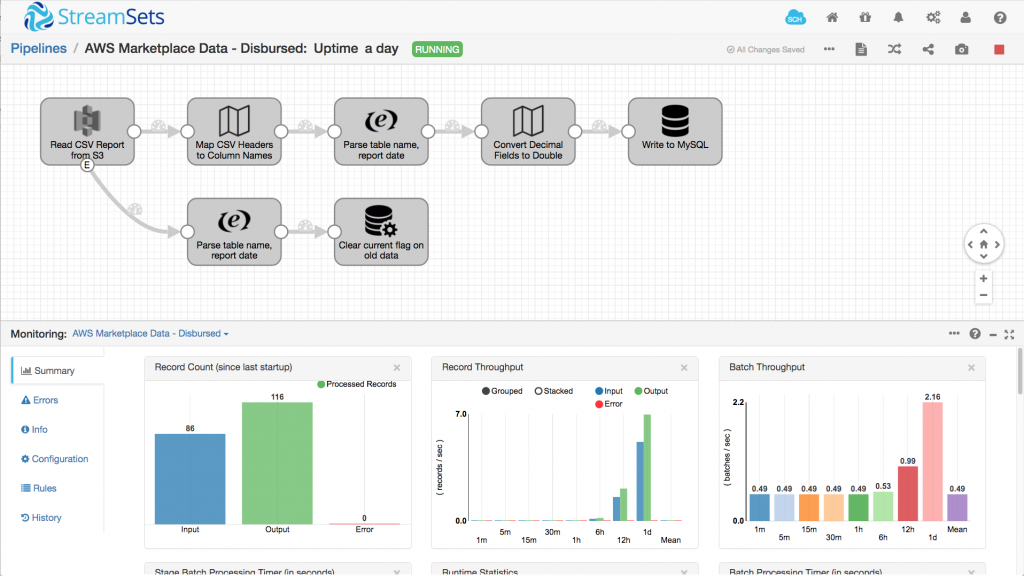
We have been successfully using these pipelines to process AWS Marketplace Commerce Analytics Service data for several weeks now:
- AWS Marketplace Data.json
- AWS Marketplace Data – Disbursed.json
- SQL script to create the MySQL tables
Import the pipelines into StreamSets Data Collector 3.15 or above to try this out yourself. To get started, deploy StreamSets Data Collector from the AWS Marketplace.
![]()