![]() The Glue Conference (better known as GlueCon) is always a treat for me. I’ve been speaking there since 2012, and this year I presented a session explaining how I use StreamSets Data Collector to ingest content delivery network (CDN) data from compressed CSV files in S3 to MySQL for analysis, using the Kickfire API to turn IP addresses into company data. The slides are here, and I’ll write it up in a future blog post.
The Glue Conference (better known as GlueCon) is always a treat for me. I’ve been speaking there since 2012, and this year I presented a session explaining how I use StreamSets Data Collector to ingest content delivery network (CDN) data from compressed CSV files in S3 to MySQL for analysis, using the Kickfire API to turn IP addresses into company data. The slides are here, and I’ll write it up in a future blog post.
As well as speaking, I always enjoy the keynotes (shout out to Leah McGowen-Hare for an excellent presentation on inclusion!) and breakouts. In one of this year’s breakouts, Diana Hsieh, director of product management at Timescale, focused on the TimescaleDB time series database.
Time Series Databases
Time series databases are optimized for handling data indexed by time, efficiently handling queries for data within a particular range of time. There are several time series databases in the market, indeed, Data Collector has long had the capability to write to InfluxDB, for example, but what intrigued me about TimescaleDB was the fact that it is built on PostgreSQL. Full disclosure: I spent five and a half years as a developer evangelist at Salesforce, and PostgreSQL was, and remains, a core part of Heroku’s platform, but I’ve also come to love PostgreSQL as more robust alternative to MySQL.
Getting Started with TimescaleDB
While listening to Diana’s presentation, I ran the TimescaleDB Docker image, mapping port 54321 on my laptop to 5432 in the Docker container so it wouldn’t clash with my existing PostgreSQL deployment. As soon as Diana left the stage, I ran through the ‘Creating Hypertables’ section of the TimescaleDB quick start, creating a PostgreSQL database, enabling it for TimescaleDB, and writing a row of data to it:
tutorial=# INSERT INTO conditions(time, location, temperature, humidity)
tutorial-# VALUES (NOW(), 'office', 70.0, 50.0);
INSERT 0 1
tutorial=# SELECT * FROM conditions ORDER BY time DESC LIMIT 10;
time | location | temperature | humidity
-------------------------------+----------+-------------+----------
2019-05-25 00:37:11.288536+00 | office | 70 | 50
(1 row)
My First TimescaleDB Pipeline
Since TimescaleDB is built on PostgreSQL, the standard PostgreSQL JDBC driver works with it out of the box. Since I already have the driver installed in Data Collector, it took me about two minutes to build a simple test pipeline to write a second row of data to my shiny new TimescaleDB server:
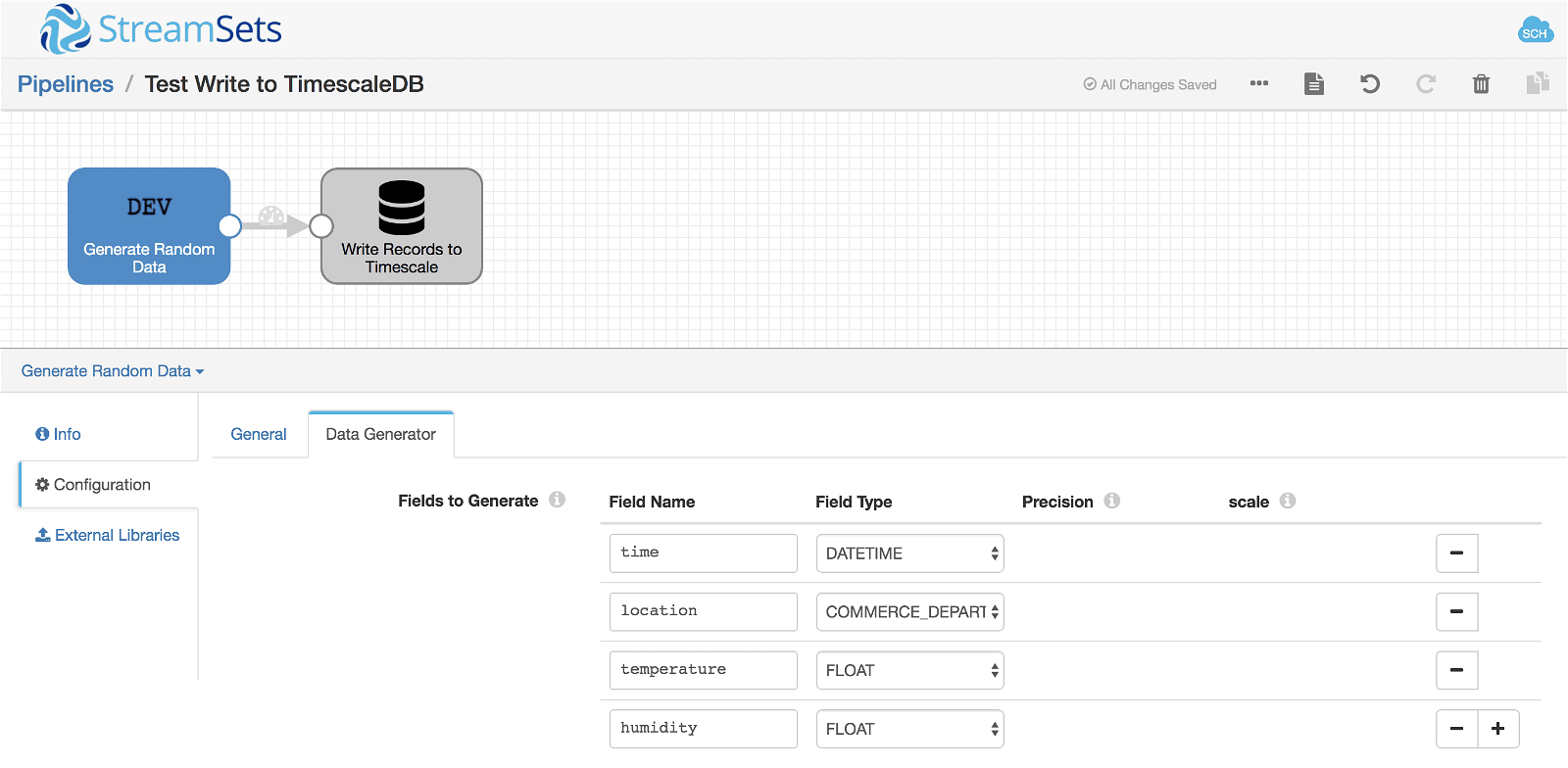 Gratifyingly, the pipeline worked first time:
Gratifyingly, the pipeline worked first time:
tutorial=# SELECT * FROM conditions ORDER BY time DESC LIMIT 10;
time | location | temperature | humidity
----------------------------+---------------------------+--------------------+--------------------
2020-12-25 23:35:43.889+00 | Grocery | 0.806543707847595 | 0.0844637751579285
2020-10-27 02:20:47.905+00 | Shoes | 0.0802439451217651 | 0.398806214332581
2020-10-24 01:15:15.903+00 | Games & Industrial | 0.577536821365356 | 0.405274510383606
2020-10-22 02:32:21.916+00 | Baby | 0.0524919033050537 | 0.499088883399963
2020-09-12 10:30:53.905+00 | Electronics & Garden | 0.679168224334717 | 0.427601158618927
2020-08-25 19:39:50.895+00 | Baby & Electronics | 0.265614211559296 | 0.274695813655853
2020-08-15 15:53:02.906+00 | Home | 0.0492082238197327 | 0.046688437461853
2020-08-10 08:56:03.889+00 | Electronics, Home & Tools | 0.336894452571869 | 0.848010659217834
2020-08-02 09:48:58.918+00 | Books & Jewelry | 0.217794299125671 | 0.734709620475769
2020-08-02 08:52:31.915+00 | Home | 0.931948065757751 | 0.499135136604309
(10 rows)
Ingesting IoT Data from Kafka to TimescaleDB
One of the primary use cases for a time series database is storing data from the Internet of Things. It took me a few minutes to code a simple Python Kafka client that would emulate a set of sensors producing more realistic temperature and humidity data than my test pipeline:
from kafka import KafkaProducer
from kafka.errors import KafkaError
import json
import random
# Create a producer that JSON-encodes the message
producer = KafkaProducer(value_serializer=lambda m: json.dumps(m).encode('ascii'))
# Send a quarter million data points (asynchronous)
for _ in range(250000):
location = random.randint(1, 4)
temperature = 95.0 + random.uniform(0, 10) + location
humidity = 45.0 + random.uniform(0, 10) - location
producer.send('timescale',
{'location': location, 'temperature': temperature, 'humidity': humidity})
# Block until all the messages have been sent
producer.flush()
Notice that the emulator emits an integer value for location, and does not timestamp the data. As you can see, just for fun, I had the emulator generate a quarter million data points. This is enough to exercise TimescaleDB a little, without taking a significant amount of time to generate.
I replaced my pipeline’s Dev Data Generator origin with a Kafka Consumer, and added a couple of processors to the pipeline:
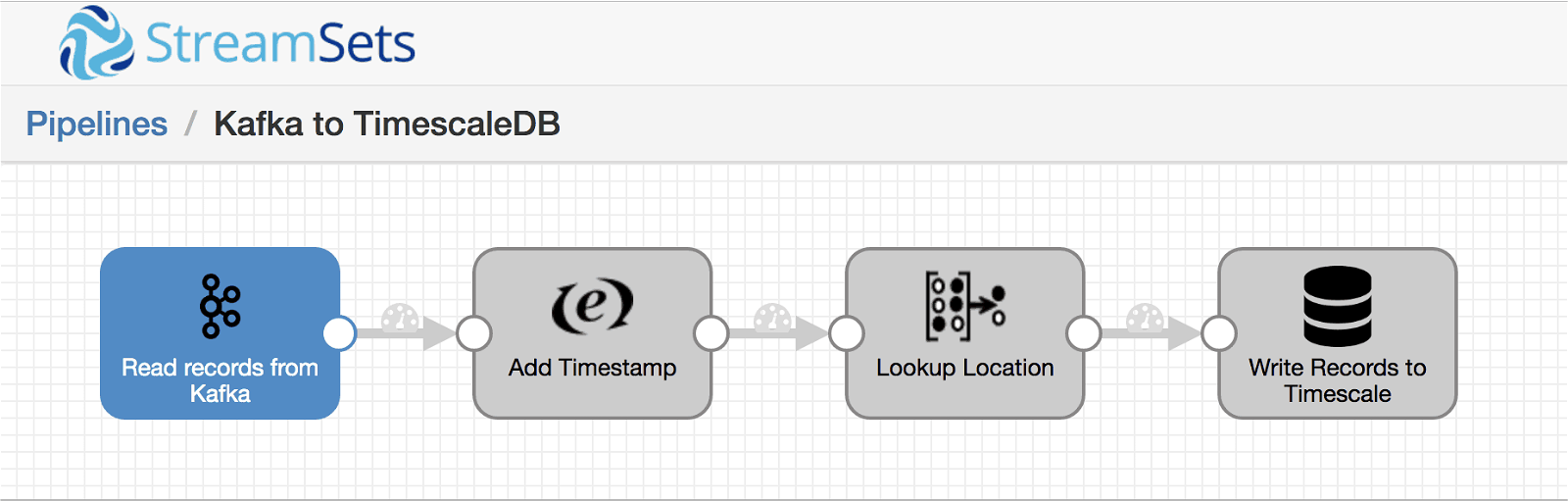 The Expression Evaluator simply adds a timestamp to each record, using some Expression Language to create the correct format:
The Expression Evaluator simply adds a timestamp to each record, using some Expression Language to create the correct format:
${time:extractStringFromDate(time:now(), 'yyyy-MM-dd HH:mm:ss.SSSZZ')}
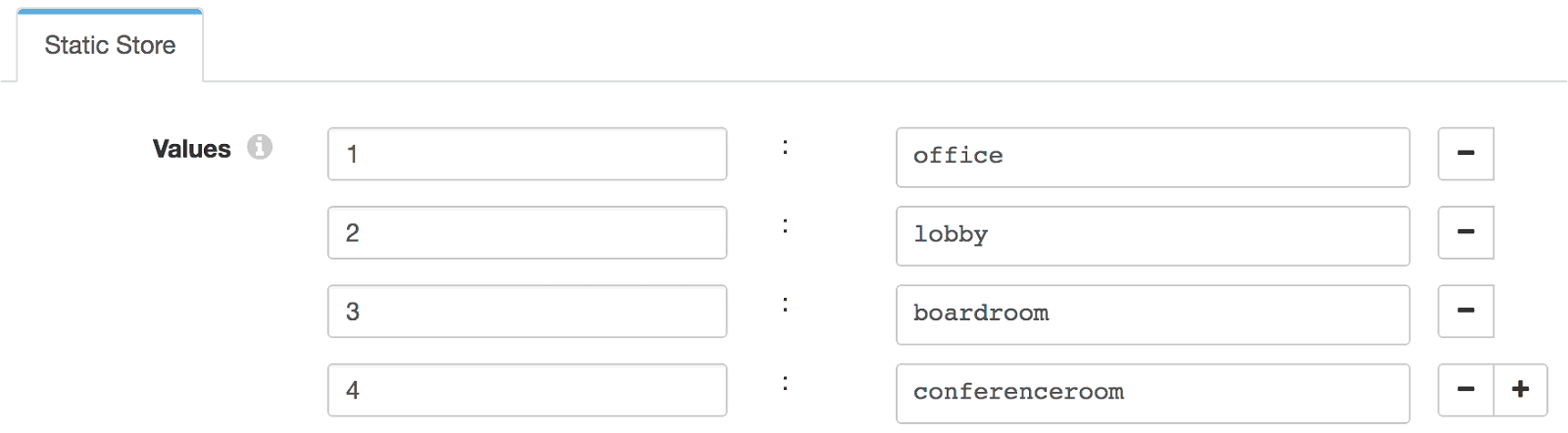
The Static Lookup processor replaces the integer location field with a string to match the TimescaleDB table schema:
 This short video shows the result. As you can see, the pipeline ingests 250,000 records in about 30 seconds. Note – this shouldn’t be interpreted as a benchmark result. Everything here was running on my laptop, and the Kafka topic had a single partition. A real-work IoT ingestion pipeline would run on more capable hardware, with multiple Kafka partitions and the same number of Data Collector pipelines:
This short video shows the result. As you can see, the pipeline ingests 250,000 records in about 30 seconds. Note – this shouldn’t be interpreted as a benchmark result. Everything here was running on my laptop, and the Kafka topic had a single partition. A real-work IoT ingestion pipeline would run on more capable hardware, with multiple Kafka partitions and the same number of Data Collector pipelines:
Conclusion
I was impressed by TimescaleDB. The unboxing experience was fast and pain-free. Although I only gave it the briefest of tire-kickings, everything worked first time. The fact that TimescaleDB is built on PostgreSQL made it easy for me to write data with off-the-shelf tooling, and I was able to use familiar SQL commands to work with the data once it was in a hypertable.
If you’re using TimescaleDB, download StreamSets Data Collector and give it a try for your data integration needs. Like the core of TimescaleDB, it is made available as open source under the Apache 2.0 license and freely available for test, development and production use.