 Importing data into Apache Hive is one of the most common use cases in big data ingest, but gets tricky when data sources ‘drift’, changing the schema or semantics of incoming data. Introduced in StreamSets Data Collector (SDC) 1.5.0.0, the Hive Drift Solution monitors the structure of incoming data, detecting schema drift and updating the Hive Metastore accordingly, allowing data to keep flowing. In this blog entry, I’ll give you an overview of the Hive Drift Solution and explain how you can try it out for yourself, today.
Importing data into Apache Hive is one of the most common use cases in big data ingest, but gets tricky when data sources ‘drift’, changing the schema or semantics of incoming data. Introduced in StreamSets Data Collector (SDC) 1.5.0.0, the Hive Drift Solution monitors the structure of incoming data, detecting schema drift and updating the Hive Metastore accordingly, allowing data to keep flowing. In this blog entry, I’ll give you an overview of the Hive Drift Solution and explain how you can try it out for yourself, today.
The StreamSets Hive Drift Solution
Apache Hive is a data warehouse system built on Hadoop-compatible file systems such as Hadoop Distributed File System (HDFS) and MapR FS. Records are written to files using a format such as Avro, with schema being stored in the Hive Metastore. Hive runs queries using the Hadoop MapReduce framework; Apache Impala (incubating) shares the Hive Metastore, files and SQL syntax, but allows interactive queries.
The StreamSets Hive Drift Solution comprises three SDC stages: the Hive Metadata processor, the Hive Metastore destination and either the Hadoop FS or the MapR FS destination.
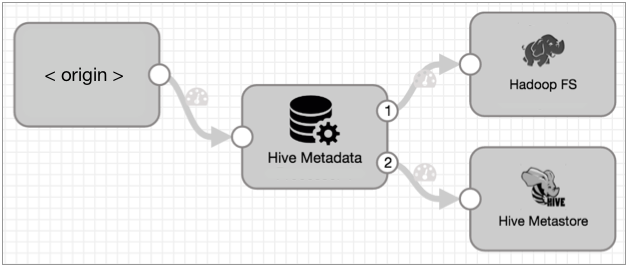
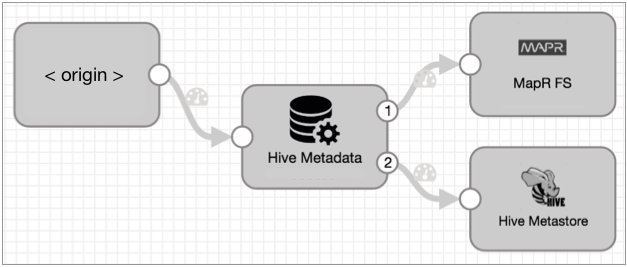
- The Hive Metadata processor reconciles any differences between the incoming record structure and the corresponding table schema in Hive, sending metadata records to the Hive Metastore destination.
- The Hive Metastore destination interprets incoming metadata records, creating or altering Hive tables accordingly.
- The Hadoop FS/MapR FS destination writes the actual data files in the Avro data format.
Why three stages instead of just one? Flexibility and scalability. As you can see, we can write data to either Hadoop FS or MapR FS by just swapping out the data destination. Also, data volume tends to increase far faster than metadata, so we can scale out the data pathway to many pipelines independent of the metadata stream. We can even fan in multiple metadata paths to a single Hive Metastore destination to control the amount of load that SDC puts on the Hive Metastore.
StreamSets Hive Drift Solution Tutorial
If you’d like to try the solution out, you can follow our new tutorial, Ingesting Drifting Data into Hive and Impala. The tutorial guides you through configuring the solution to ingest data from MySQL to Apache Hive running on any of the Apache, Cloudera, MapR or Hortonworks distributions. This short video shows the tutorial configuration in action:
StreamSets Data Collector is 100% open source, so you can download it today, work through the tutorial and get started ingesting drifting data into Apache Hive!