 In the unlikely event you’re not familiar with the Raspberry Pi, it’s an ARM-based computer about the same size as a deck of playing cards. The latest iteration, Raspberry Pi 3, has a 1.2GHz ARMv8 CPU, 1MB of memory, integrated Wi-Fi and Bluetooth, all for the same $35 price tag as the original Raspberry Pi released in 2012. Running a variety of operating systems, including Linux, it’s actually quite a capable little machine. How capable? Well, last week, I successfully ran StreamSets Data Collector (SDC) on one of mine (yes, I have several!), ingesting sensor data and sending them to Apache Cassandra for analysis.
In the unlikely event you’re not familiar with the Raspberry Pi, it’s an ARM-based computer about the same size as a deck of playing cards. The latest iteration, Raspberry Pi 3, has a 1.2GHz ARMv8 CPU, 1MB of memory, integrated Wi-Fi and Bluetooth, all for the same $35 price tag as the original Raspberry Pi released in 2012. Running a variety of operating systems, including Linux, it’s actually quite a capable little machine. How capable? Well, last week, I successfully ran StreamSets Data Collector (SDC) on one of mine (yes, I have several!), ingesting sensor data and sending them to Apache Cassandra for analysis.
Here’s how you can build your own Internet of Things testbed and ingest sensor data for around $50.
Sensing Environmental Data
 I started with a Raspberry Pi 3 Model B with Raspbian Jessie Lite installed and Adafruit’s BMP180 Barometric Pressure/Temperature/Altitude Sensor. I followed the instructions in Adafruit’s BMP085/180 tutorial to configure the Raspberry Pi to talk to the sensor via I2C and ran the example Python app to show sensor readings.
I started with a Raspberry Pi 3 Model B with Raspbian Jessie Lite installed and Adafruit’s BMP180 Barometric Pressure/Temperature/Altitude Sensor. I followed the instructions in Adafruit’s BMP085/180 tutorial to configure the Raspberry Pi to talk to the sensor via I2C and ran the example Python app to show sensor readings.
SDC’s File Tail Origin seemed the easiest way to get sensor data from Python to a pipeline, so I modified Adafruit’s Python app to produce JSON and wrote a simple script to run it every few seconds (code in Gist). The resulting output looks like this:
{"id":1,"time":1466727488193,"temp_deg_C":27.60,"pressure_Pa":101379.00,"altitude_m":-4.83}
{"id":1,"time":1466727493410,"temp_deg_C":27.60,"pressure_Pa":101377.00,"altitude_m":-5.08}
{"id":1,"time":1466727498619,"temp_deg_C":27.60,"pressure_Pa":101386.00,"altitude_m":-4.83}
{"id":1,"time":1466727503823,"temp_deg_C":27.60,"pressure_Pa":101382.00,"altitude_m":-4.49}
{"id":1,"time":1466727509027,"temp_deg_C":27.60,"pressure_Pa":101374.00,"altitude_m":-4.33}
Once everything was working, I set my script running, with its output directed to ~/sensor.log, to generate some data.
./sensor.sh > ~/sensor.log &
Installing StreamSets Data Collector on the Raspberry Pi
Now to get SDC running! First, we need Java. StreamSets supports the Oracle JDK, rather than OpenJDK, so I installed it on the Pi with:
$ sudo apt-get install oracle-java8-jdk
I used Jessie Lite to minimize the amount of storage and memory consumed on the Pi. One consequence was that there was no desktop to run a browser, so I browsed the StreamSets archive on my laptop, copied the relevant link, and downloaded SDC 1.4.0.0 directly onto the Pi. To minimize SDC’s footprint, I downloaded the core package, which includes only a minimal set of stages:
$ wget http://archives.streamsets.com/datacollector/1.4.0.0/tarball/streamsets-datacollector-core-1.4.0.0.tgz
Following the instructions on the StreamSets download page, I extracted the tarball and was ready to download the Cassandra destination:
$ tar xvzf streamsets-datacollector-core-1.4.0.0.tgz $ cd streamsets-datacollector-core-1.4.0.0
At this point, I ran into a snag. The SDC package manager uses sha1sum to verify the integrity of stages as they are downloaded. Unfortunately, a bug, fixed in the upcoming 1.5.0.0 release, caused the package manager to fail with an error
$ ./bin/streamsets stagelibs -list sha1sum: invalid option -- 's' Try 'sha1sum --help' for more information. Failed! running sha1sum -s -c stage-lib-manifest.properties.sha1 in /tmp/sdc-setup-927
There’s an easy workaround, though – open libexec/_stagelibs in an editor, and change line 99 from
run sha1sum -s -c ${FILE_NAME}.sha1
to
run sha1sum --status -c ${FILE_NAME}.sha1
Now I could list the available stages:
$ ./bin/streamsets stagelibs -list
StreamSets Data Collector
Stage Library Repository: https://archives.streamsets.com/datacollector/1.4.0.0/tarball
ID Name Installed
=================================================================================================================
streamsets-datacollector-apache-kafka_0_8_1-lib Apache Kafka 0.8.1.1 NO
streamsets-datacollector-apache-kafka_0_8_2-lib Apache Kafka 0.8.2.1 NO
streamsets-datacollector-apache-kafka_0_9-lib Apache Kafka 0.9.0.0 NO
streamsets-datacollector-apache-kudu-0_7-lib Apache Kudu 0.7.1 NO
streamsets-datacollector-aws-lib Amazon Web Services 1.10.59 NO
streamsets-datacollector-basic-lib Basic YES
streamsets-datacollector-cassandra_2-lib Cassandra 2.1.5 NO
streamsets-datacollector-cdh_5_2-lib CDH 5.2.6 NO
streamsets-datacollector-cdh_5_3-lib CDH 5.3.8 NO
streamsets-datacollector-cdh_5_4-cluster-cdh_kafka_1_2-lib CDH 5.4.8 Cluster Kafka 1.2.0 Lib NO
streamsets-datacollector-cdh_5_4-cluster-cdh_kafka_1_3-lib CDH 5.4.8 Cluster Kafka 1.3.2 Lib NO
streamsets-datacollector-cdh_5_4-lib CDH 5.4.8 NO
streamsets-datacollector-cdh_5_5-cluster-cdh_kafka_1_3-lib CDH 5.5.0 Cluster Kafka 1.3.2 Lib NO
streamsets-datacollector-cdh_5_5-lib CDH 5.5.0 NO
streamsets-datacollector-cdh_5_7-cluster-cdh_kafka_2_0-lib CDH 5.7.0 Cluster Kafka 2.0.1 Lib NO
streamsets-datacollector-cdh_5_7-lib CDH 5.7.0 NO
streamsets-datacollector-cdh_kafka_1_2-lib CDH Kafka 1.2.0 (0.8.2.0) NO
streamsets-datacollector-cdh_kafka_1_3-lib CDH Kafka 1.3.2 (0.8.2.0) NO
streamsets-datacollector-elasticsearch_1_4-lib Elasticsearch 1.4.5 NO
streamsets-datacollector-elasticsearch_1_5-lib Elasticsearch 1.5.2 NO
streamsets-datacollector-elasticsearch_1_6-lib Elasticsearch 1.6.2 NO
streamsets-datacollector-elasticsearch_1_7-lib Elasticsearch 1.7.4 NO
streamsets-datacollector-elasticsearch_2_0-lib Elasticsearch 2.0.2 NO
streamsets-datacollector-elasticsearch_2_1-lib Elasticsearch 2.1.2 NO
streamsets-datacollector-elasticsearch_2_2-lib Elasticsearch 2.2.2 NO
streamsets-datacollector-elasticsearch_2_3-lib Elasticsearch 2.3.1 NO
streamsets-datacollector-groovy_2_4-lib Groovy 2.4.6 YES
streamsets-datacollector-hdp_2_2-lib HDP 2.2.0 NO
streamsets-datacollector-hdp_2_3-lib HDP 2.3.0 NO
streamsets-datacollector-hdp_2_4-lib HDP 2.4.0 NO
streamsets-datacollector-influxdb_0_9-lib InfluxDB 0.9+ NO
streamsets-datacollector-jdbc-lib JDBC NO
streamsets-datacollector-jms-lib JMS NO
streamsets-datacollector-jython_2_7-lib Jython 2.7.0 YES
streamsets-datacollector-mapr_5_0-lib MapR 5.0.9 NO
streamsets-datacollector-mapr_5_1-lib MapR 5.1.0 NO
streamsets-datacollector-mongodb_3-lib MongoDB 3.0.2 NO
streamsets-datacollector-omniture-lib Omniture NO
streamsets-datacollector-rabbitmq-lib RabbitMQ 3.5.6 NO
streamsets-datacollector-redis-lib Redis 2.8.x, 3.0.x NO
streamsets-datacollector-stats-lib Statistics NO
=================================================================================================================
Since File Tail Origin is in the included ‘basic’ package of stages, I just needed to install the Cassandra Destination:
$ ./bin/streamsets stagelibs -install=streamsets-datacollector-cassandra_2-lib
Creating a Table in Cassandra
Over on my laptop, I installed Cassandra 2.2. This was the first release of Cassandra to support aggregate functions, such as mean, max and min, and it works well with SDC’s Cassandra destination, which uses the 2.1.5 driver.
In cqlsh, I created a keyspace and table to hold my data:
CREATE KEYSPACE mykeyspace
WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };
USE mykeyspace;
CREATE TABLE sensor_readings (
sensor_id INT,
time TIMESTAMP,
temperature DOUBLE,
pressure DOUBLE,
altitude DOUBLE,
PRIMARY KEY (sensor_id, time)
);
Building a Pipeline to Ingest Sensor Data
Now I could build a pipeline! The File Tail Origin was straightforward to configure – I just needed to specify JSON as the Data Format and /home/pi/sensor.log as the Path.
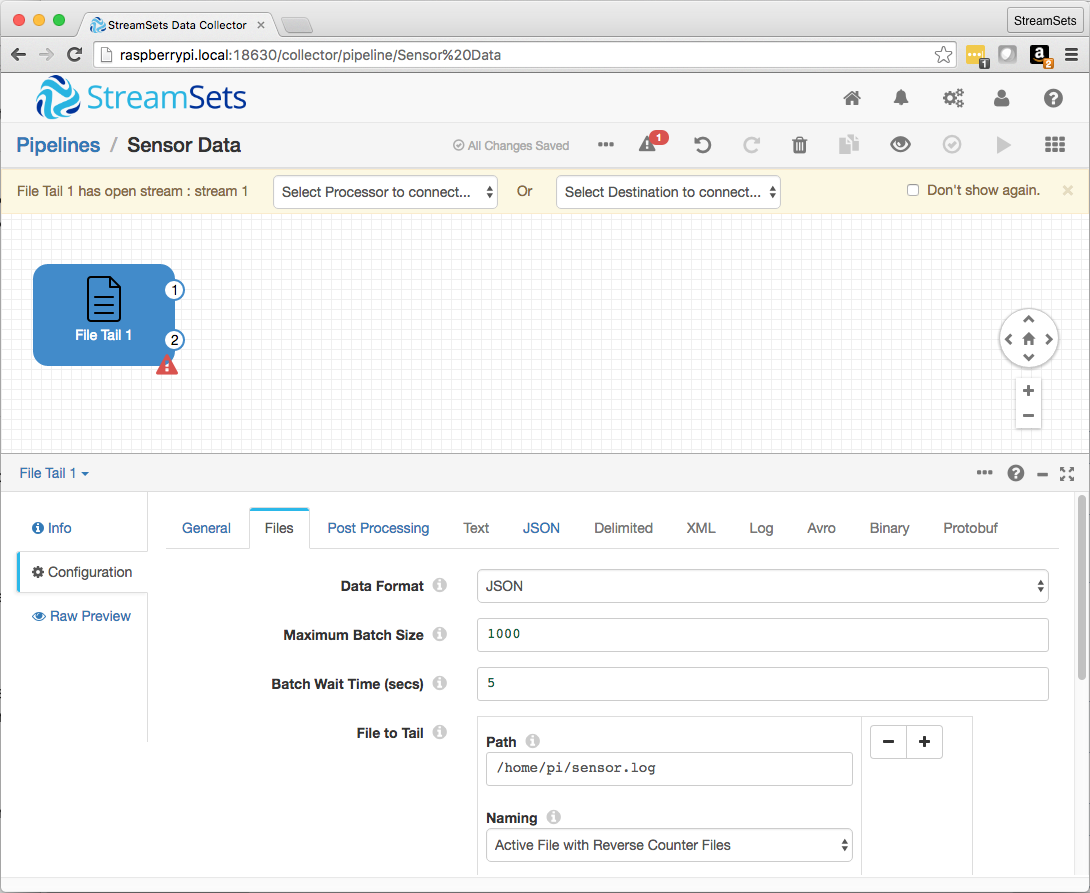
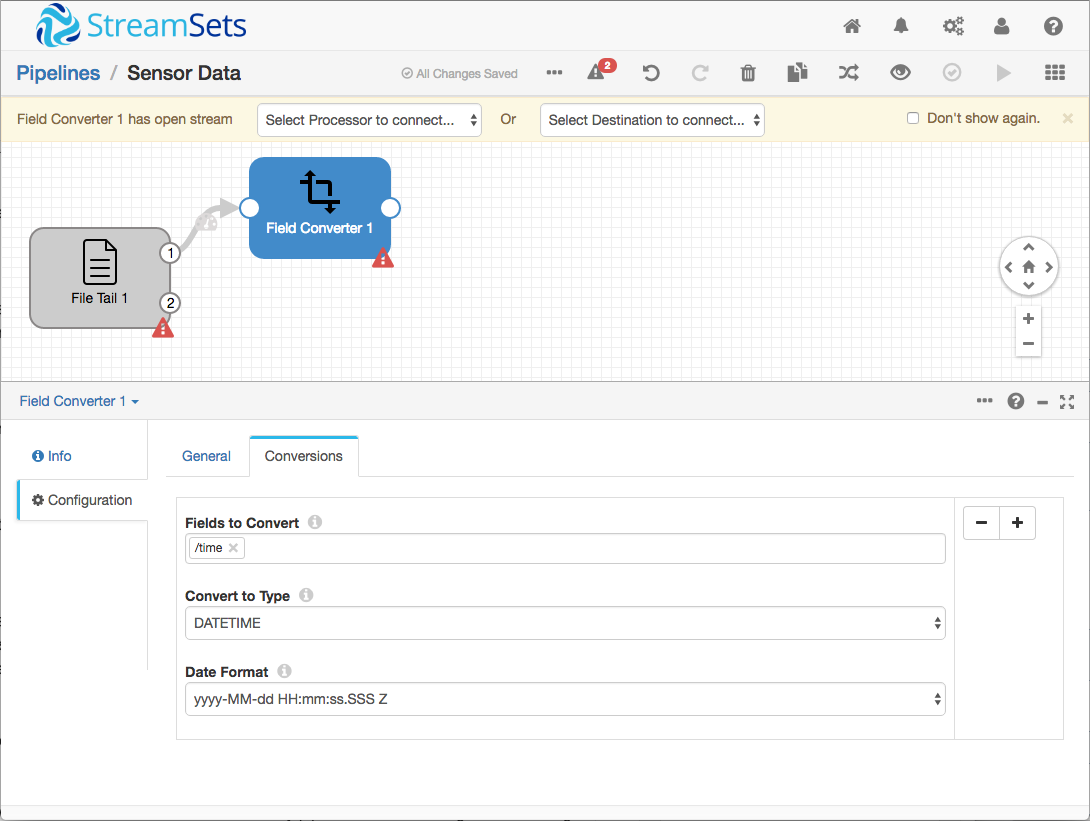
I passed the origin’s data stream to a Field Converter Processor, since the time value from the Python app, in milliseconds since 1/1/70, needed to be converted to a timestamp for consumption by Cassandra.
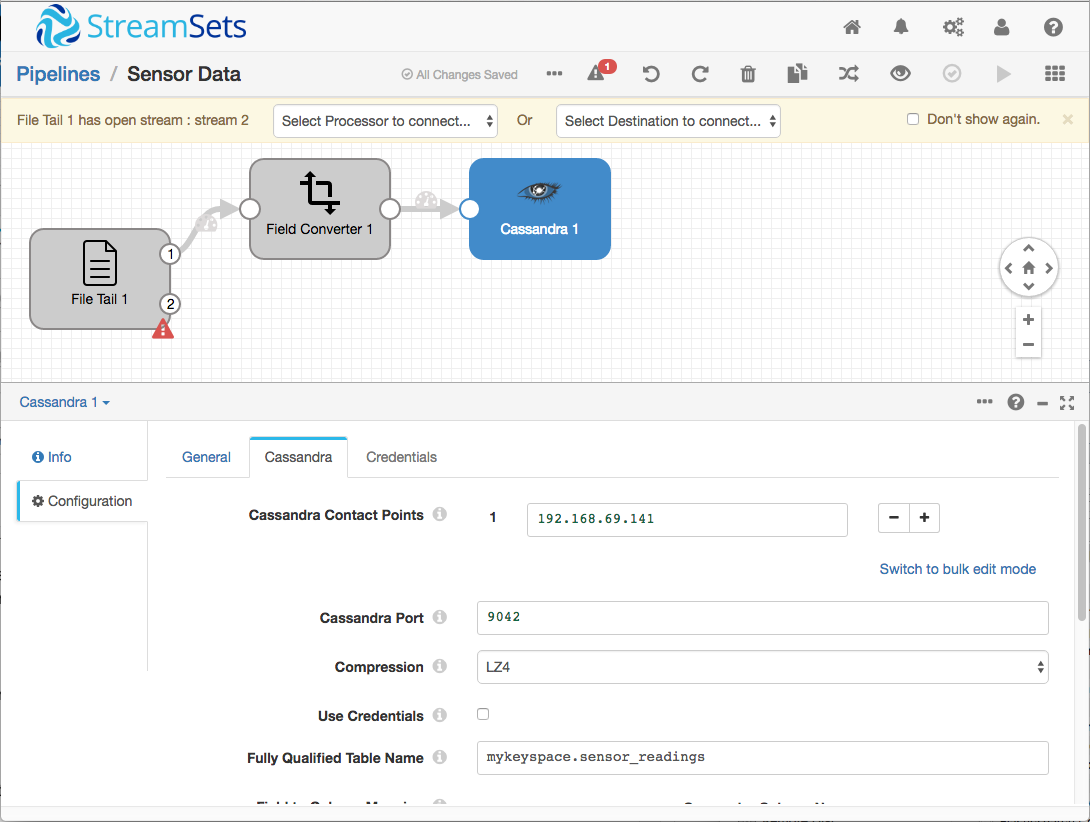
The Field Converter’s output goes straight to the Cassandra Destination, which needed mappings from the property names in the JSON to Cassandra column names as well as the Cassandra host and port.
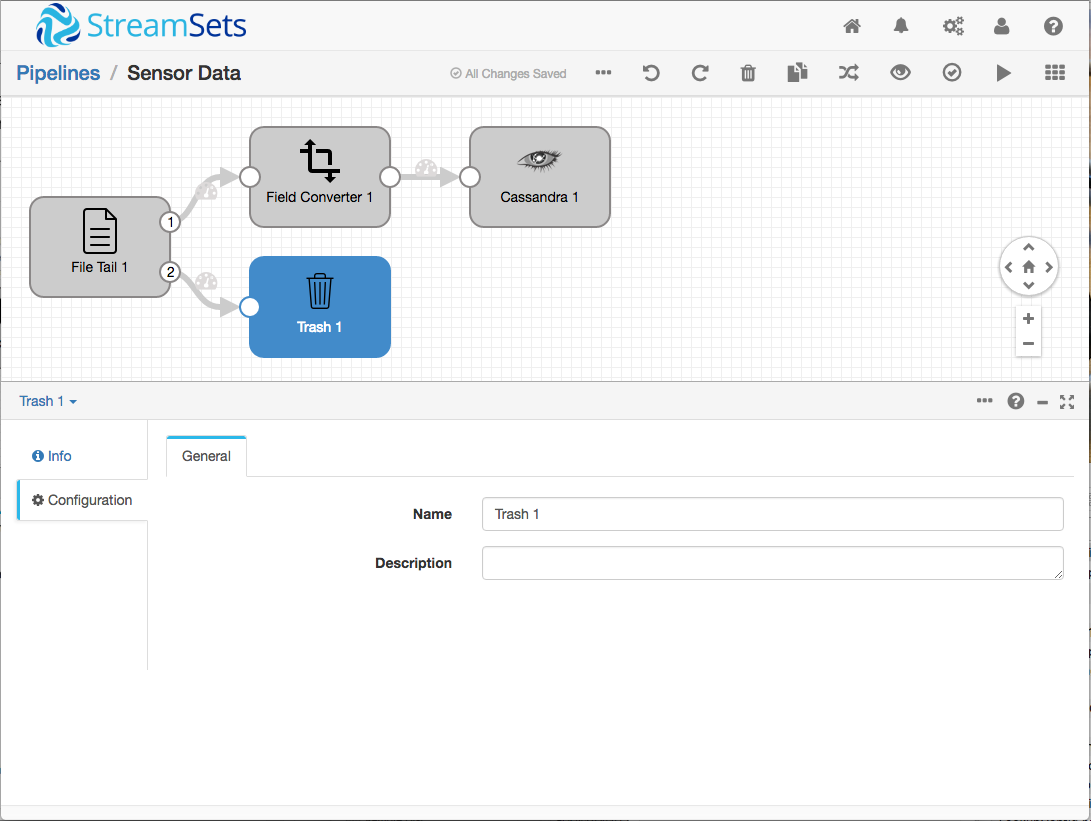
Finally, I didn’t need the File Tail Origin’s metadata stream, so I just sent it to the trash.
In preview mode, everything looked just fine, but the first time I ran the pipeline, I hit a snag – the pipeline failed with the error:
RUNNING_ERROR com.datastax.driver.core.exceptions.InvalidQueryException: Batch too large
After some research I discovered that the default Cassandra behavior is to log a warning on batch sizes greater than 5kB. Looking in the Cassandra logs, I could see that my SDC batch size of 1000 records crossed not only the warning threshold, but also the hard ceiling of 50kB!
ERROR [SharedPool-Worker-1] 2016-06-24 13:19:27,119 BatchStatement.java:267 - Batch of prepared statements for [mykeyspace.sensor_readings] is of size 116380, exceeding specified threshold of 51200 by 65180. (see batch_size_fail_threshold_in_kb)
Doing the math, it looked like Cassandra would be happy with 40 records, so I configured the origin’s maximum batch size accordingly. Now my pipeline was able to ingest the 14,000 or so records I had already collected, and continue processing new readings as they were written to the sensor.log file.
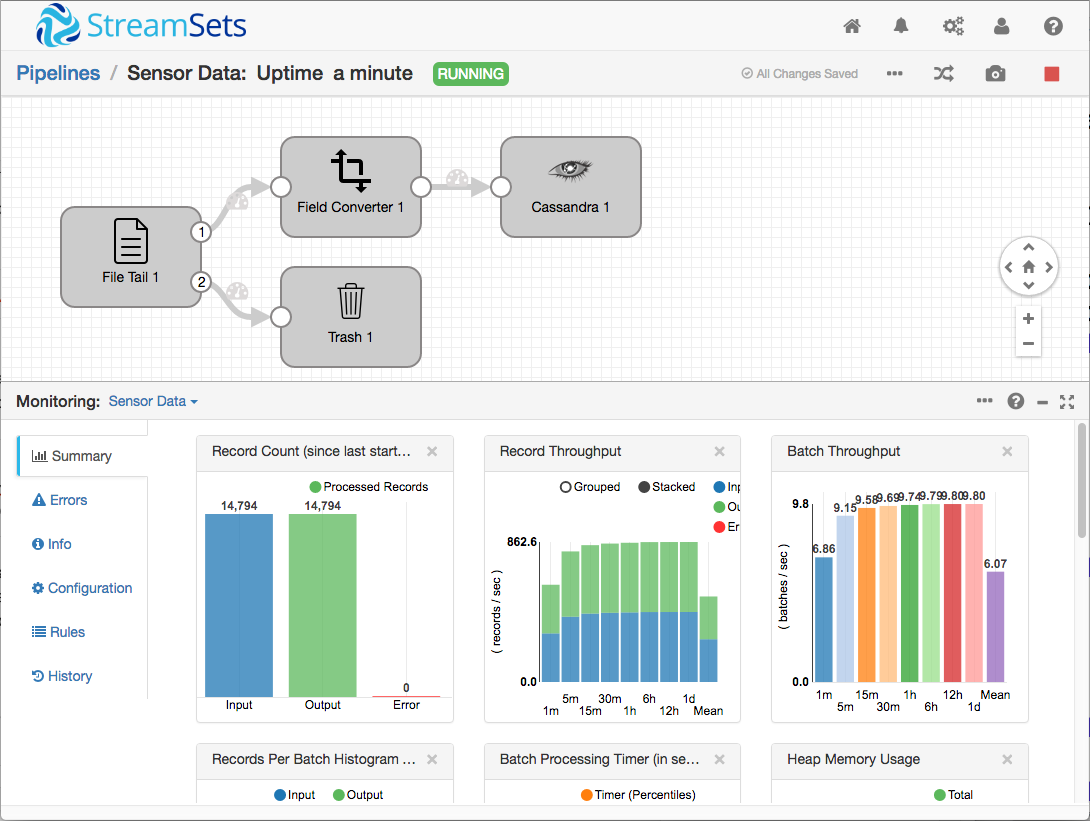
Analyzing the Data in Cassandra
Over in cqlsh, I was able to see the data, and perform some simple analysis:
cqlsh:mykeyspace> select count(*) from sensor_readings where sensor_id = 1; count ------- 14817 (1 rows) cqlsh:mykeyspace> select * from sensor_readings where sensor_id = 1 order by time desc limit 10; sensor_id | time | altitude | pressure | temperature -----------+--------------------------+----------+------------+------------- 1 | 2016-06-24 21:59:44+0000 | 4.83 | 1.0128e+05 | 27.7 1 | 2016-06-24 21:59:38+0000 | 4.33 | 1.0128e+05 | 27.7 1 | 2016-06-24 21:59:33+0000 | 3.91 | 1.0128e+05 | 27.7 1 | 2016-06-24 21:59:28+0000 | 3.66 | 1.0127e+05 | 27.7 1 | 2016-06-24 21:59:23+0000 | 4.33 | 1.0127e+05 | 27.7 1 | 2016-06-24 21:59:18+0000 | 4.08 | 1.0128e+05 | 27.7 1 | 2016-06-24 21:59:12+0000 | 4.08 | 1.0128e+05 | 27.7 1 | 2016-06-24 21:59:07+0000 | 4.16 | 1.0128e+05 | 27.7 1 | 2016-06-24 21:59:02+0000 | 4.41 | 1.0127e+05 | 27.7 1 | 2016-06-24 21:58:57+0000 | 4.58 | 1.0128e+05 | 27.7 (10 rows) cqlsh:mykeyspace> select count(temperature), avg(temperature), min(temperature), max(temperature) from sensor_readings where sensor_id = 1; system.count(temperature) | system.avg(temperature) | system.min(temperature) | system.max(temperature) ---------------------------+-------------------------+-------------------------+------------------------- 14826 | 25.36766 | 24.1 | 28 (1 rows) cqlsh:mykeyspace> select count(temperature) as count, avg(temperature) as mean, min(temperature) as min, max(temperature) as max from sensor_readings where sensor_id = 1; count | mean | min | max -------+----------+------+----- 14830 | 25.36829 | 24.1 | 28 (1 rows)
Of course, as analysis goes, this is barely scratching the surface. Now that the data is flowing into Cassandra, you could build a visualization, or write data to any other destination supported by SDC.
Conclusion
StreamSets Data Collector is sufficiently lightweight to run well on the Raspberry Pi, ingesting data produced by local apps and writing directly to a wide range of destinations. What can you build with SDC and RPi? Let me know in the comments!