
Author Bio: Isaac Omolayo is a Data Engineer with 4 years of experience in building ETL processes, data infrastructures, automated data systems, working with cloud engines, and data analytics. He has vast knowledge in working with Apache Kafka, Kafka Streaming, Apache Spark, Apache Airflow, Databases (SQL/NoSQL), Python and many other Big Data technologies. Generally, Isaac is a lover of open-source technologies.
One of the technologies being used in real-time processing is Kafka. Kafka helps to solve many problems, including consistency, scalability, fault tolerance, and resilience. Kafka is a distributed streaming platform and an event store that focuses on ensuring high throughput, and low latency of real-time data feeds.
Apache Kafka is an open-source tool that can publish-subscribe to a messaging system that enables you to build distributed applications where you can process streams of records in real-time. It was originally developed at Linkedin and was pushed out to the public in early 2011. Kafka has different APIs that allow you to achieve different solutions, this is one of its strengths. The APIs include the Producer API, the Consumer API, the Kafka Streams API, the Kafka Connect API and the Admin API.
Some of Kafka’s features include storage, a replay of historical messages, events sourcing, database replication and Change Data Capture (CDC). There are many interesting use cases that companies use Kafka for. In this post, we are going to use Kafka streaming to stream live data into our Cassandra database.
We are going to use Apache Kafka to stream live cryptocurrency data from a data API provided by coinranking.com. The API provides real-time data about the current prices of different cryptocurrencies like the BTC and Ethereum.
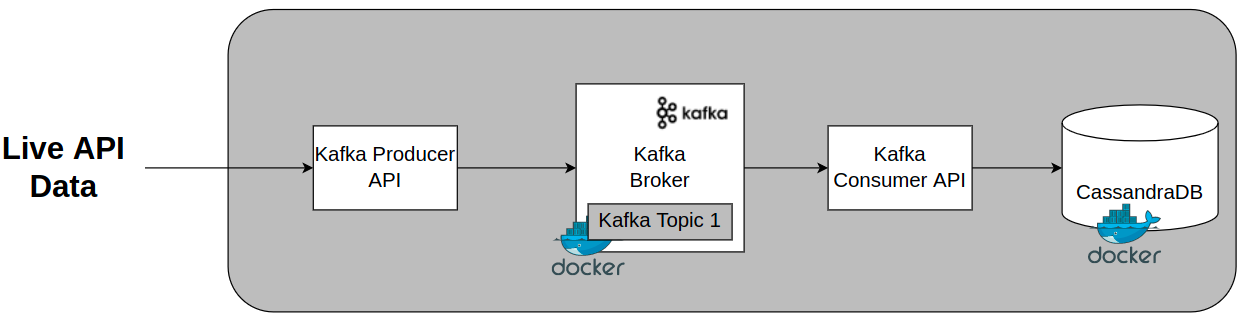
We will briefly look at:
- The architecture of Apache Kafka
- Running Apache Kafka and Apache Cassandra on a Docker container
- Creating a Kafka topic for the Kafka broker
- Writing the Python script that uses the Kafka Stream API to stream data from the coin ranking API
- Inserting data into our Cassandra database
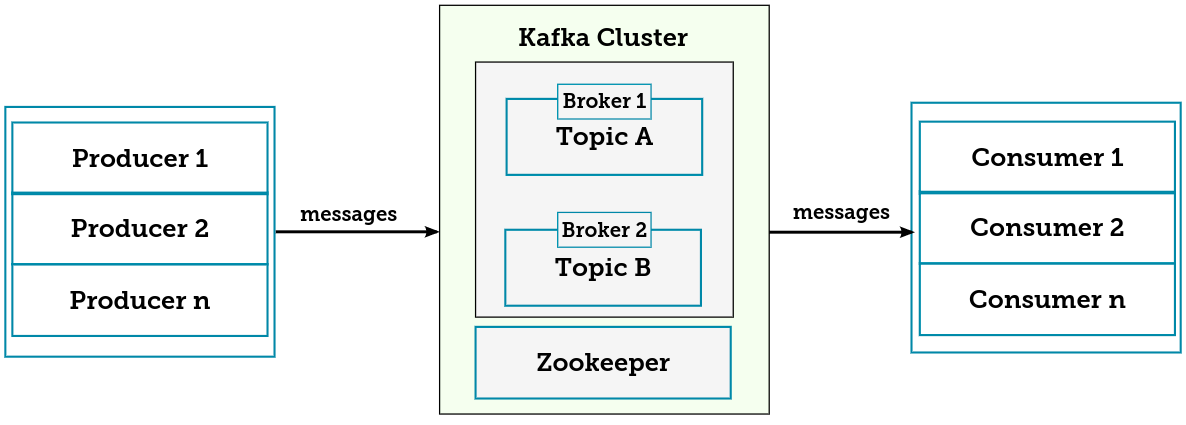
Kafka Architecture
For the purpose of this article, we are only going to create a single Kafka cluster with a single broker. The most important components of a Kafka cluster are the broker, the producer, the consumer, the APIs (Consumer, Producers, Stream API, Connect API), and Kafka topics.
One thing to keep in mind is that Kafka’s architecture is built to emphasize the performance and scalability of brokers, so you would be leveraging the Kafka Topics partition to achieve this. This is not the focus of our article today but we have included the standard architecture of a Kafka cluster so that you can see how Kafka works internally.
Running Apache Kafka on a Docker Container
- Installation of Docker Desktop
If you don’t already have Docker Desktop installed on your computer, you can download the Docker desktop executable file from here. Execute the software, and be ready to start pulling the necessary images for development. Make sure the Docker desktop is running.
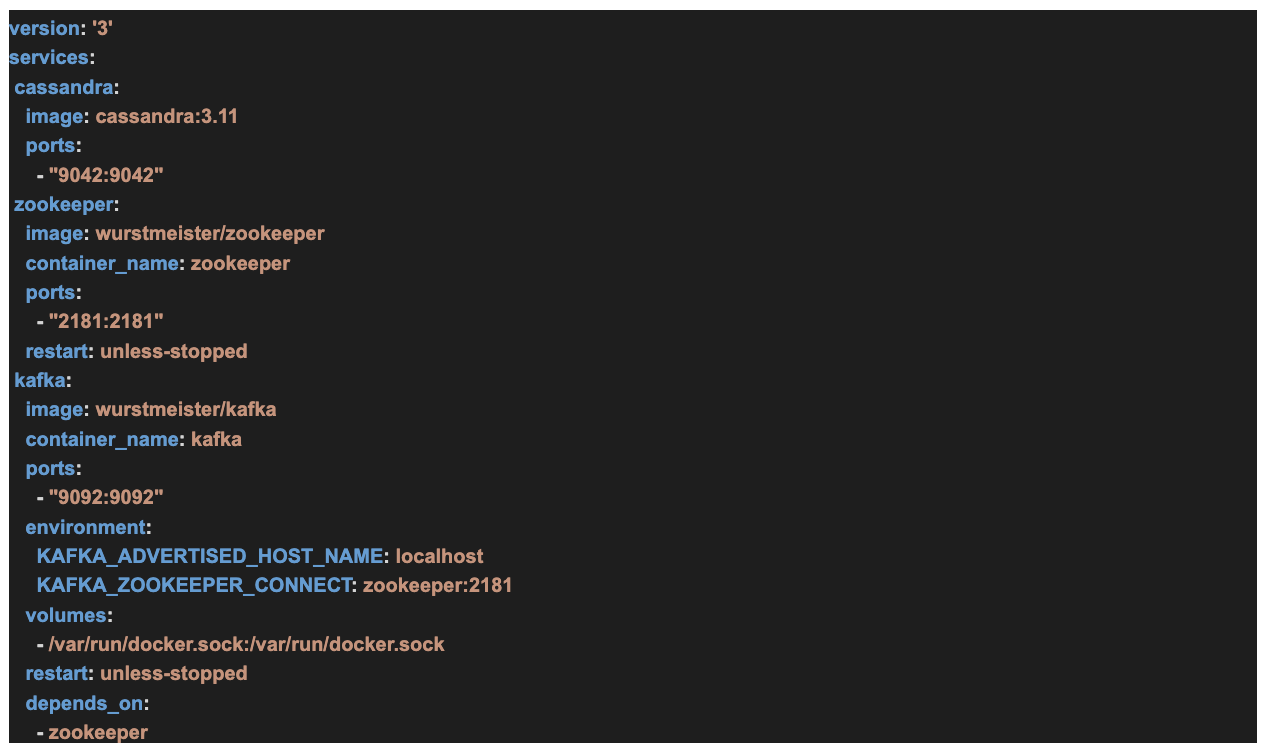
- Create docker-compose.yml file in the directory of your choice
By now, your Docker desktop should be running, you can now create a file called docker-compose.yml and write the YAML file instruction to pull our Kafka image, the Zookeeper image, and the Cassandra database image. Our file looks like the following.
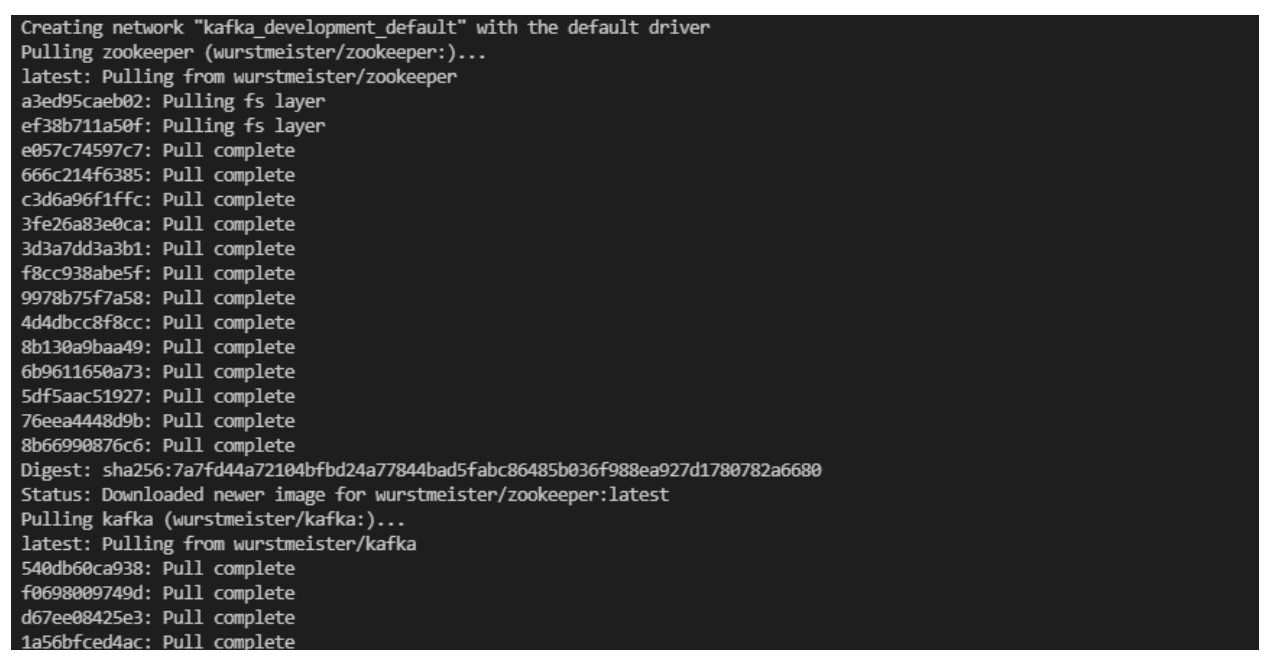
- Pull the images and start the containers.
Run the docker-compose.yml to start with the command below. We have provided what you would see when the images are being pulled, and when the containers are running.

You should see a window like the following.
Now you can check to see that Kafka, Zookeeper, and our Cassandra database are running.


With Kafka, the Zookeeper and the Cassandra database all running, we can now start writing our Python streaming application. But before that, we are going to create our Kafka topic in the Kafka cluster and set up our database keyspace and the table.
Kafka Topic Creation in the Kafka Broker
Messages are sent to and read from specific topics, our Kafka producer will write data to the topic we created and we are also going to consume the data from our topic. To set this, we are going to go into the Kafka container, navigate to the Kafka bin folder, create a Kafka topic using the below command, and list the topics in our Kafka broker.

Cassandra Database Setup
Make sure to choose the right database for your application, but if you are looking for a distributed database, that can handle fault tolerance and consistency, then you would want to give it to Cassandra. Cassandra is a free and open-source database that can handle a large amount of data. One of its strengths is high availability, so if you are looking for a database that can scale as your business grows, then you would want to look into Cassandra.
Interestingly, Cassandra is more situated for a large amount of data and not for small applications, so make sure to know when to use it. In our case, we expect our data will continue to grow and we want to be sure our database can scale. Though we have set up a single node cluster, we can bring in more nodes if there is a need for that. We have created the Cassandra keyspaces and the tables using the command below.
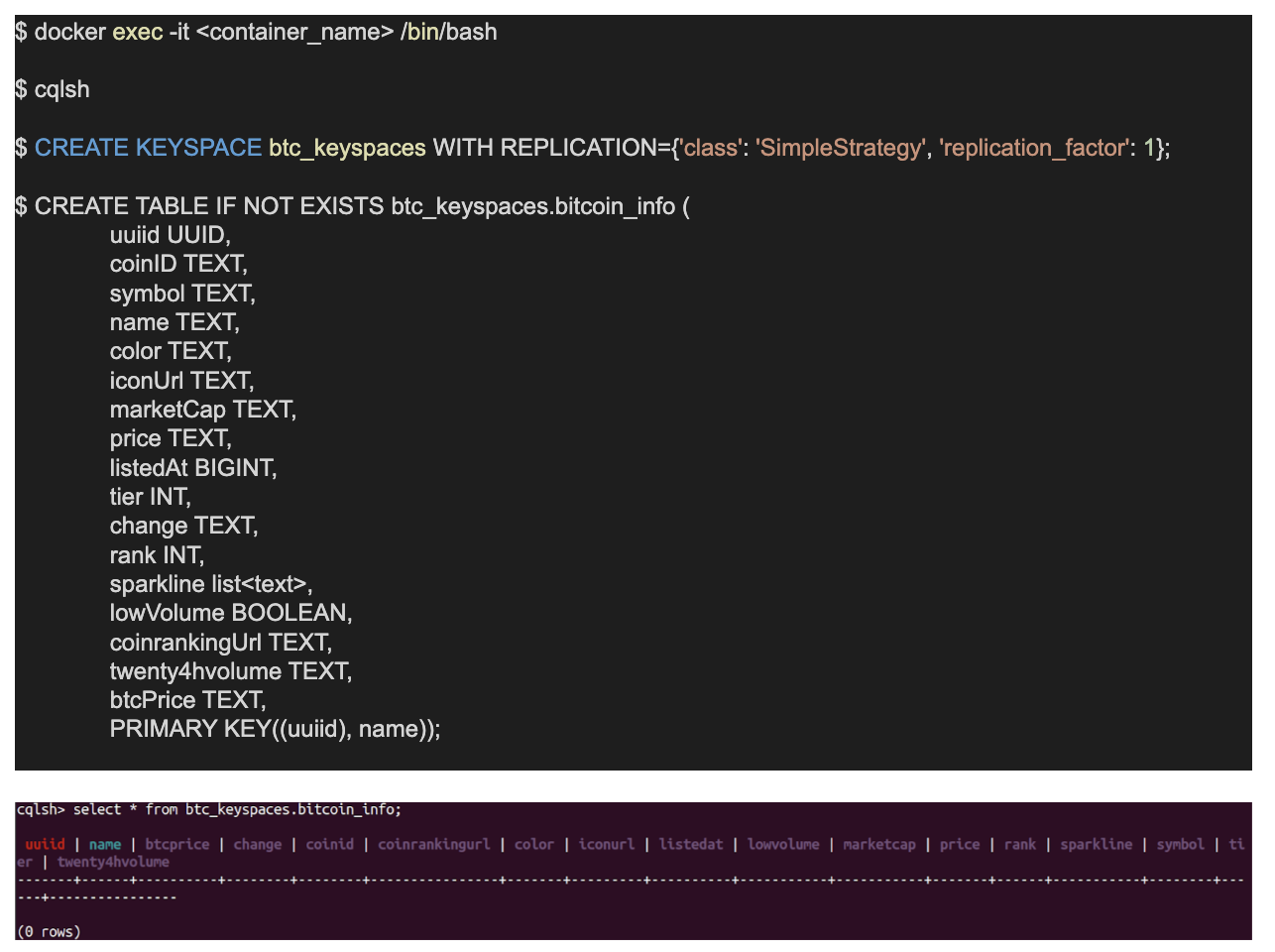
Using the Kafka Streams API to Stream Data from the Coin Base API
At this point, we are going to write the Python scripts for our streaming application. Now navigate to your folder where you have created the YAML file to write the Python application scripts. Different parts of our application will help to achieve different purposes, but in general, you can write your application in a language of your choice, we have used Python here, but you can use JAVA or Scala depending on your preferred language. One of the things I like about Kafka is the APIs it provides at different stages of pipelines that allow us to plug in different platforms.
With that in mind, we are going to write three Python applications.
- One that interacts with data API and gets the data. The most important part of getting the data is the authorization method which is fairly easy, you only need to provide the access token that is attributed to your account, it probably has some request limits depending on your account plan. Please read more about this in the documentation.
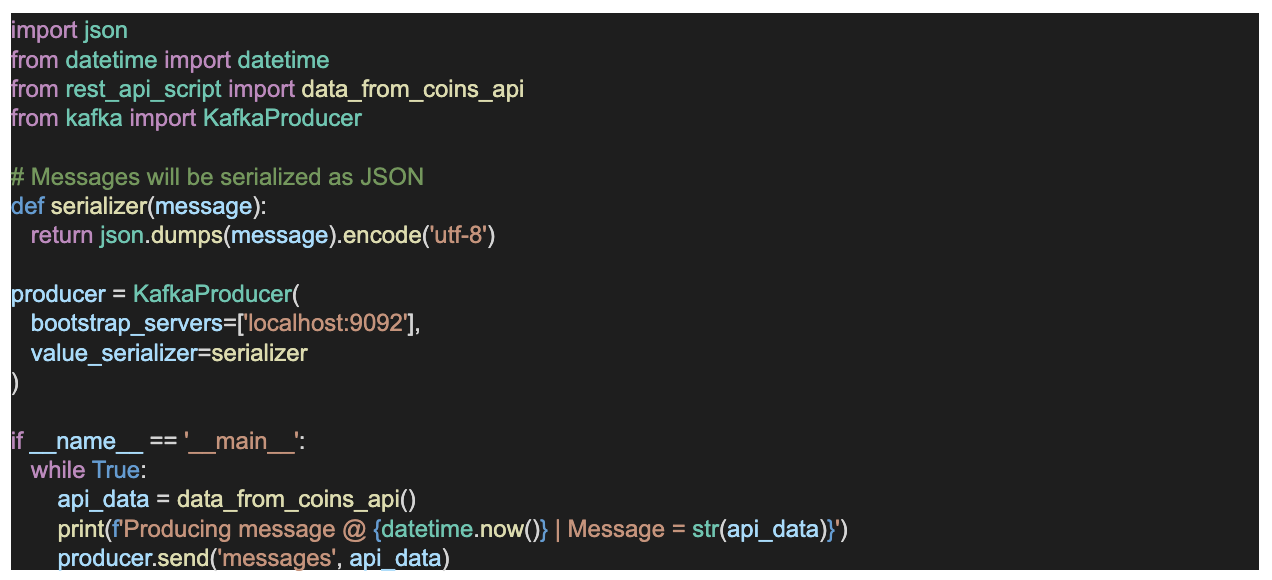
- Another for Kafka streaming produces the data from the generated data of the Python application.
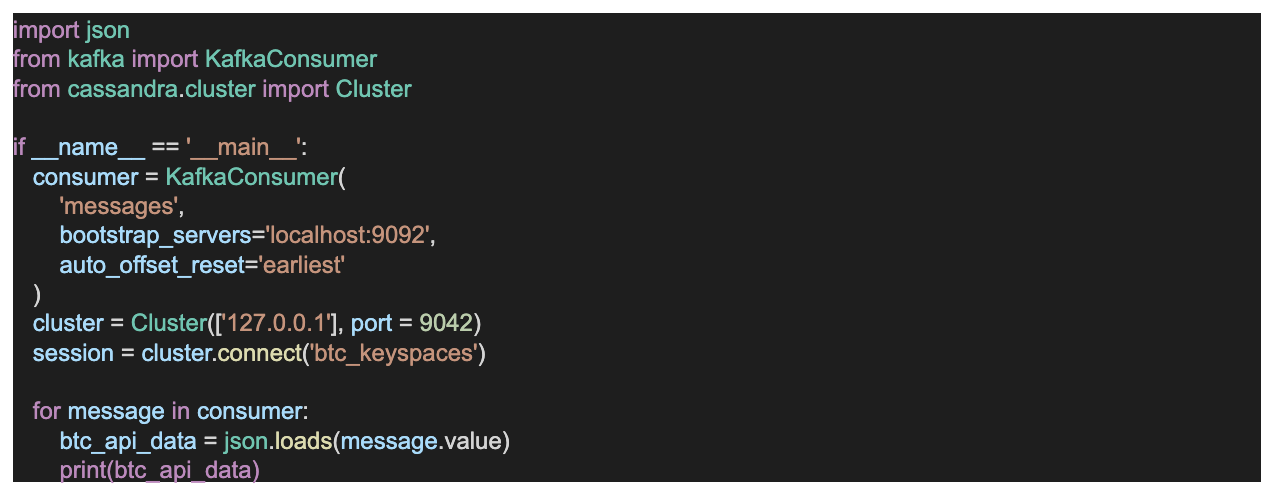
- The final that consumes and inserts the data into Cassandra.
Let’s start on the first.
- Write the Python application that gets our real-time data from API. We have called it rest_api_script.py. The script looks like this.
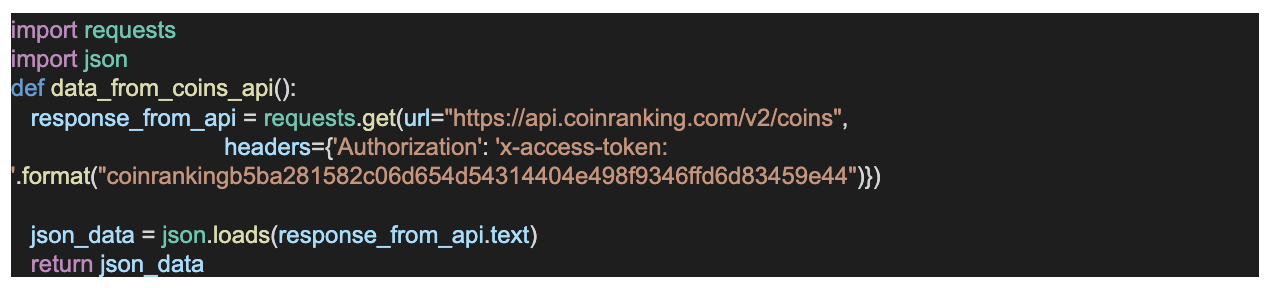
- Next, integrate the application that produces data into the Kafka producer API using the Kafka Stream Python client (Python-Kafka). We have created a Python script called producer.py.
You need to install the Python Kafka library using: pip install kafka-python. You can read about the package here.
- Lastly, I Integrate the application that consumes the data streamed by the Kafka producer API using the Kafka Streaming consumer API. We have now created the third script, the consumer; we called it consumer.py. Interestingly, we have also incorporated the script that inserts into our Cassandra database in the consumer.py. This is what the script looks like, the complete code is on Github.
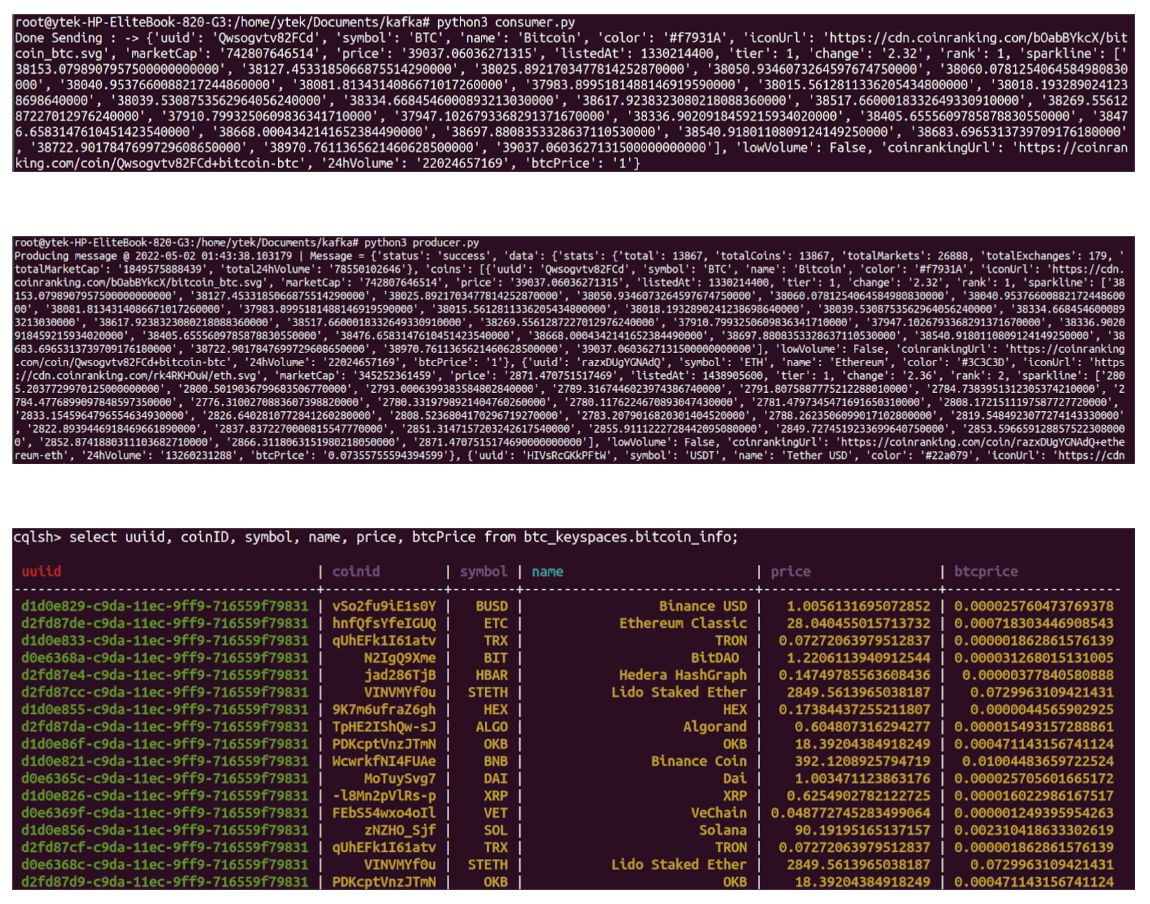
With all the scripts ready, we are going to start our applications in this chronological order, the python consumer.py, and python producer.py. The resulting window is shown below. For the complete code of this blog is on github.com.
Summary
In this article, we have built a live streaming Kafka application that inserts into a Cassandra database. We can decide to write into the database using Apache Spark for faster writes, but we are not going to do that since this is just a simple pipeline.
A very important takeaway here is that always make sure you deploy your Kafka application on a low latency network. Now imagine we want different upstream applications that make use of the data from Kafka for prediction. A late response from our Kafka would imply a loss of revenue, so you don’t want to do that. On the Cassandra side, always make sure you use the right data modelling strategy that suits your application.
Interestingly, StreamSets provides us with a simple way of achieving real-time data streaming and writing data into Cassandra. This video provides an example pipeline that uses the StreamSets Kafka connector to interact with HTTP requests. And this video shows how easy it is to use Kafka to stream data using StreamSets Kafka connectors. A very important piece of information here is that you should make sure your application can communicate with both the Kafka cluster and your Cassandra database if they are not in the same network. With that, you are good to go.
