This article is the second part of a three-part series, Conducting the Chaos of Data Drift. StreamSets’ automated drift detection, a piece of it’s patented Data Drift technology, allows users to reduce break-fix by 90%. In this second part of the series, we will be covering explicitly data drift as it pertains to Kafka Topics.
Read Part One: Manage File Updates with Automated Drift Detection in Your Snowflake Ingest Pipelines
I have been working with MOM (Messaging Oriented Middleware) since 2001. From the start, I simply loved knowing that the work we did had an immediate impact on a user, a peer, somewhere in the company in real-time.
XML was the craze and people went overboard with their DTD’s (before XSD). (That’s if you were lucky enough to have someone that actually took the time to create one so you could at least understand what exactly to expect.)
Most of us were not that lucky and basically got a few XML messages that you had to code off of.
Alas, the task was simple enough: read messages off the queue, do something with it after you parsed it and then create a response message back. As always, things worked great in the DEV and QA environments. Of course they would, because the developers of the upstream system were the ones that sent the test cases. Unsurprisingly, they made sure that the data entry point was always picture perfect.
I would receive these pristine messages and fire back my response. We would sail through QA. Now, time to smile at our success, pop our beverage of choice, and patiently await pushing to production the next day. Onto the next exciting project we go!
Fantasy over. And, reality sets it.
I arrived at the office on time, got my cup of coffee and read the news on my monitor when the Business Rep across the cubicle gets a phone call. It seems that my application is busted because they are not getting any response back.
There it is again…. a DATA DRIFT TSUNAMI!
What had happened? Well, the end users, doing normal end user things, did not follow that well-manicured script that we did during QA. Now, those pristine messages I was getting are anything but pristine in my Kafka Topics.
My application is freaking out. I have fields I am not expecting, fields I should expect in the message not in the Kafka message… heck, I don’t even know what to expect anymore. If only there was something at the time to save me hours of frantic coding, save my shirts from sweat stains and my dreams from XML… horrible dreams like the XML was Hannibal Lecter “are the fields still changing”.
Well today, with StreamSets’ automated drift detection, you can save yourself from these horrible experiences. How do you ask? Let’s walk through a very specific use case—automating drift detection in your Kafka Topics.
Avoiding Data Drift Problems in Your Kafka Topics
Let’s stop the drift at its source… literally.
Extending from our previous blog, we will be working with the same drifty files as before. However, this time we are also going to make some of the fields Required. We’ll also rename some fields so that they match with the JSON naming conventions that we need to write to.
In this pipeline, we are selecting to create a single JSON Object Message for every record we process. Instead, we could do this as an array of JSON Objects per Message. I will let you switch between the two and determine which one you prefer.
Let’s have a peak at our Pipeline!

As previously mentioned, this pipeline should look very similar to our drifty files to Snowflake blog. It’s not supposed to look complicated because handling data drift in StreamSets is not complicated at all. It’s built into the DNA of the platform.
Whether you are working with files, semi-structured formats or even NoSQL systems, this pipeline is as complicated as you need to get for handling Data Drift.
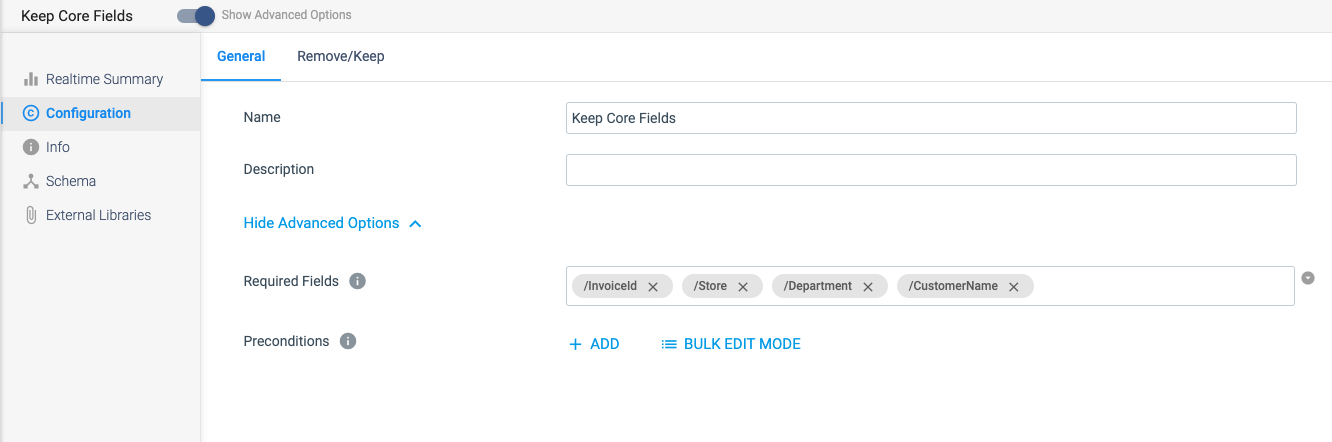
Required Fields
The biggest issue when dealing with files, semi-structured and NoSQL systems is the fact that you are not guaranteed to receive a field even if it is ~blank/null/nil/none~ (whatever your application wants to call no value).
I have had this happen to me so many times where the format, unless I specifically detect for one of these scenarios, will then drop that field from the payload I receive. They are expecting that the source system will always be correct, but that never happens.
Requirements change, new data is introduced, mergers and acquisitions happen and before you know it the source system is not what it once was. However, the processing that sends data downstream has either never been updated or, maybe it was, but something was missed. When you are viewing millions or even billions of records, missing something is more than likely.
Eventually, we get that first record and BOOM our application is down. You know the drill!
So, how can we handle this so that even if a required field is missing our application can not only keep processing the data it expects, but also do something with those bad records?
We used the Field Remover in the last blog but this time we are going to introduce a new processor that could be used.

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
Required Fields
In the screenshot below, we’ve placed the fields that must always be in the payload in the Required Fields section. If these fields do not exist, they will be sent to error in which case we can either handle them in some other fashion or simply ignore them if they are unneeded in our Kafka Topics.
The most important piece is that when required fields are missing, they do not take down our application. Now, that’s a win!
Rename Fields
We have not discussed this processor before, but I do want to bring it up because I often have to convert my field names to something else to fit with the Canonical model in messaging applications. I like this processor because it makes it very simple to handle and I am not stuck having to maintain some third party XSD, DTD, etc. that is likely never going to keep up with data drift.
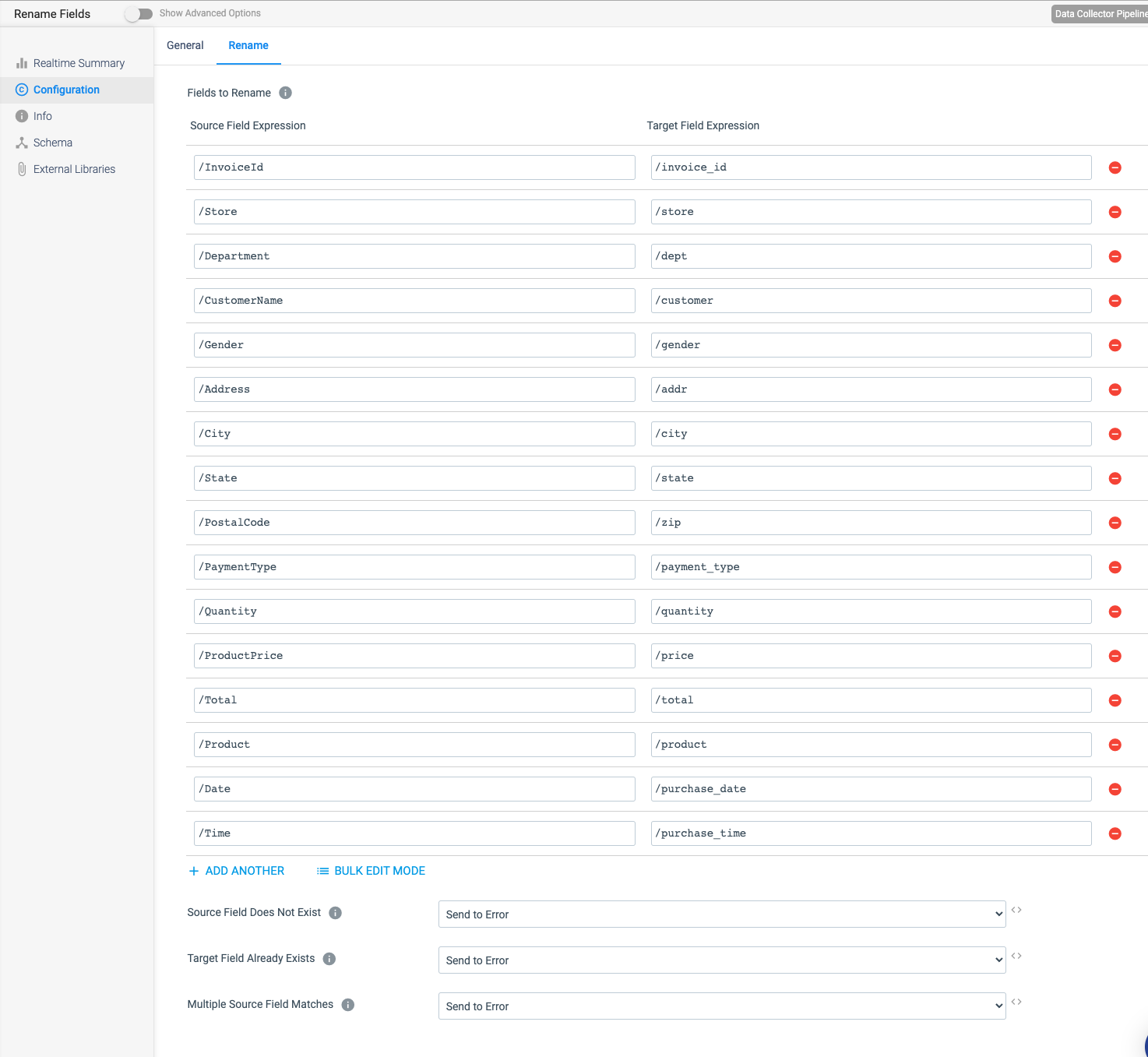 The Fields to Rename expression segment of this page is very straightforward; however, what I do want to draw your attention to are the three options at the bottom of the image above.
The Fields to Rename expression segment of this page is very straightforward; however, what I do want to draw your attention to are the three options at the bottom of the image above.
Source Field Does Not Exist
This is very similar to the Field Remover processors’ Keep Core Fields option, but in this configuration the processor expects every source field to be Required. If that is the case, we could drop the Field Remover and just enable this setting.

Target Field Already Exists
This setting is very powerful. One of my favorite options is APPEND_NUMBERS. It would be so nice to capture something like this and push it down the line without needing to go back and edit the Schema or some other section in your code, eliminating the need for regression testing, etc. Enabling this option will simply automatically handle it for you.

Multiple Source Fields Matches
Another annoying occurrence that comes up from time to time. But, no need to worry about a pipeline going down because of it any longer.

There you have it. We’ve just finished setting up our processors and are ready to add the final touch to our pipeline, the destination.
Writing to Kafka Topics
As mentioned before, I have been working with messaging systems for the past 20 years. I must say it’s always been annoying when I have one team that wants XML, another one that prefers JSON, and then yet another that prefers binary.
I’d then have to import and use all of these different libraries and learn whatever structure I had to learn for what they wanted. Plus, handle constant data drift.
I’ll always cherish these memories. But, life just got so much easier.
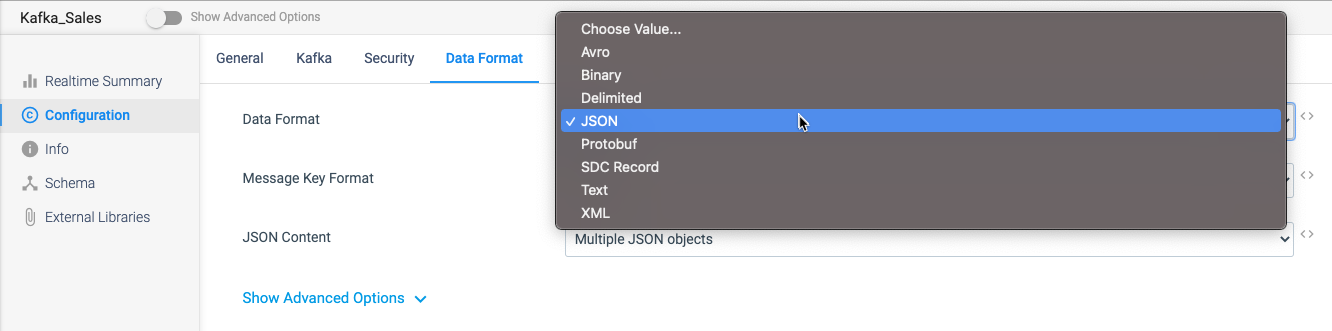
Now, in our Kafka Destination, I don’t have to even think about what any of these formats are, I no longer have to import multiple libraries, and best of all, I don’t have to spend hours trying to figure all of it out.
Instead, I simply select JSON as my Data Format and then decide how I want it to handle all the records that I process into my Kafka Topics.
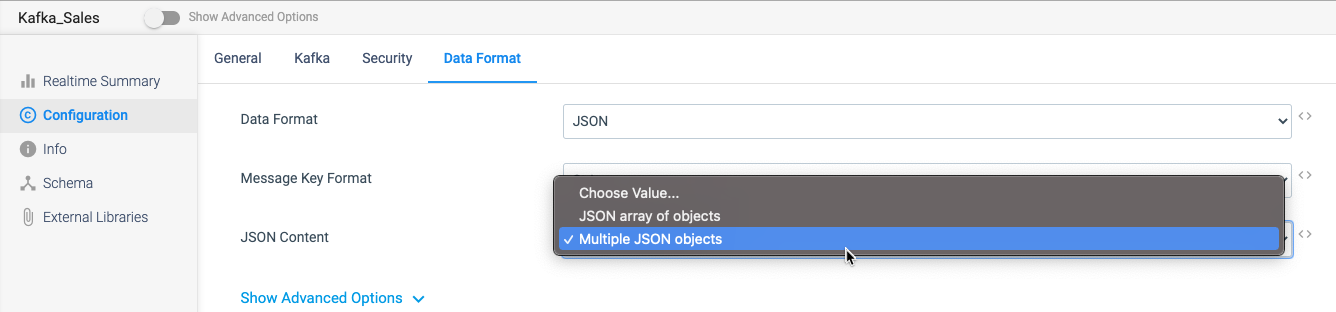
Now, all my consumers are guaranteed to have clean, drift-free data in the correct format and data types. Everyone’s life just got a lot easier.
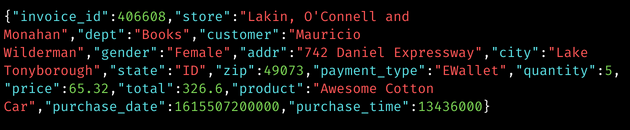
Data Drift Detection in Your Kafka Topics
Event tracking is becoming a necessity for growing businesses. And, Apache Kafka has become the de facto Event Streaming Platform used by many leaders in the industry. As with many new technologies, data engineers are consistently promised cleanliness and simplicity. But, the reality is that, with humans in the equation, data engineering always ends up being a little more difficult.
StreamSets doesn’t promise to eliminate data drift. Instead, StreamSets was built with patented, data drift detection and automation capabilities in its DNA to put you in control of your drift.
Avoid the tsunami of drifty data and eliminate 90% of break-fix time by giving StreamSets a try today.
You can find the export of this pipeline as well as the sample files used in our GitHub repo.