In my previous blog, we looked at using TensorFlow models in dataflow pipelines to generate predictions and classifications in real-time. In this blog post, I will walk you through using Databricks ML models in StreamSets Data Collector for low-latency inference.
In Machine Learning there are two major phases.
Training Phase
- In this phase historical data is used to build, train and evaluate models
- Some of the more popular tools, languages, and frameworks used for training models include Python, R, Scala, SparkML; TensorFlow, Keras, scikit-learn; Jupyter Notebooks, and Anaconda
Inference Phase
This can be broken down in two categories.
Bulk
- Predictions and classifications for larger datasets
- In such use cases mid-to-high latency is usually acceptable
- Example: sending nightly emails to entire customer base to promote discounts/deals
Low-latency (aka Fast inference)
- Involves predictions and classifications on small number of records for fast predictions
- Example: if a transaction is fraudulent or not at Point Of Sale systems or during online purchases
Like TensorFlow Serving, MLeap, and PMML, Databricks ML Model Export is also targeted at low-latency, lightweight ML-powered applications. With Databricks Model Export, you can.
- Use an existing model deployment system—which in this case is Data Collector’s Databricks ML Evaluator*
- Achieve low latency (milliseconds) inference
- Use ML models and pipelines in custom deployments
*Note: Databricks ML Evaluator currently belongs to Technology Preview family of beta stages and should not be used in production until it has been promoted out of beta.
*UPDATE: As of Data Collector version 3.7.0, Databricks ML Evaluator is no longer considered a Technology Preview feature and is approved for use in production.
To illustrate how low-latency inference can be achieved using Databricks ML Evaluator in Data Collector, let’s take a look at a rather straightforward example.
Here are the details:
Training Phase: Databricks
Spark ML Model
- I’ve created and trained a RandomForestRegressor model in Databricks (Notebooks) using Scala. Note: The code can be easily ported to Python, and for the sake of this illustration, I did not fine tune any hyperparameters—which is highly recommended in production.
- After training the model I exported it using Databricks ML Model Export and saved it on AWS S3 directly from Databricks. Note: The exported model eventually needs to be stored locally in Data Collector where Databricks ML Evaluator can access it. In my case, I simply downloaded it using AWS Command Line Interface.
Dataset
- The model is trained on a classic dataset that contains advertising budgets (in 1000s of USD) for media channels–TV, Radio and Newspapers–and their sales (in 1000s of units).
Inference
- The model is trained to predict sales (number of units sold) based on advertising budgets allocated to TV, Radio and Newspapers media channels.
Inference Phase: Databricks ML in SDC

For simplicity, I’ve kept the pipeline to a minimum with three stages — Dev Raw Data Source origin, Databricks ML Evaluator and Kafka Producer destination.
Things to pay close attention to:
- The format and structure of input data in Dev Raw Data Source origin:
{ "metadata" : ["TV","Radio","Newspaper"], "features": { "type": 1, "values":[4.1, 11.6, 5.7] } } { "metadata" : ["TV","Radio","Newspaper"], "features": { "type": 1, "values":[48.3,47.0,8.5] } } { "metadata" : ["TV","Radio","Newspaper"], "features": { "type": 1, "values":[230.1,37.8,69.2] } }Where;
- metadata is optional and indicates that the three values are TV, Radio and Newspaper (budgets) respectively.
- features is required and must be in MLlib vector format — type == 0 for sparse vectors and type == 1 for dense vectors.
- values is required and must be an array of dense or sparse values depending on type.
- The config section of Databricks ML Evaluator
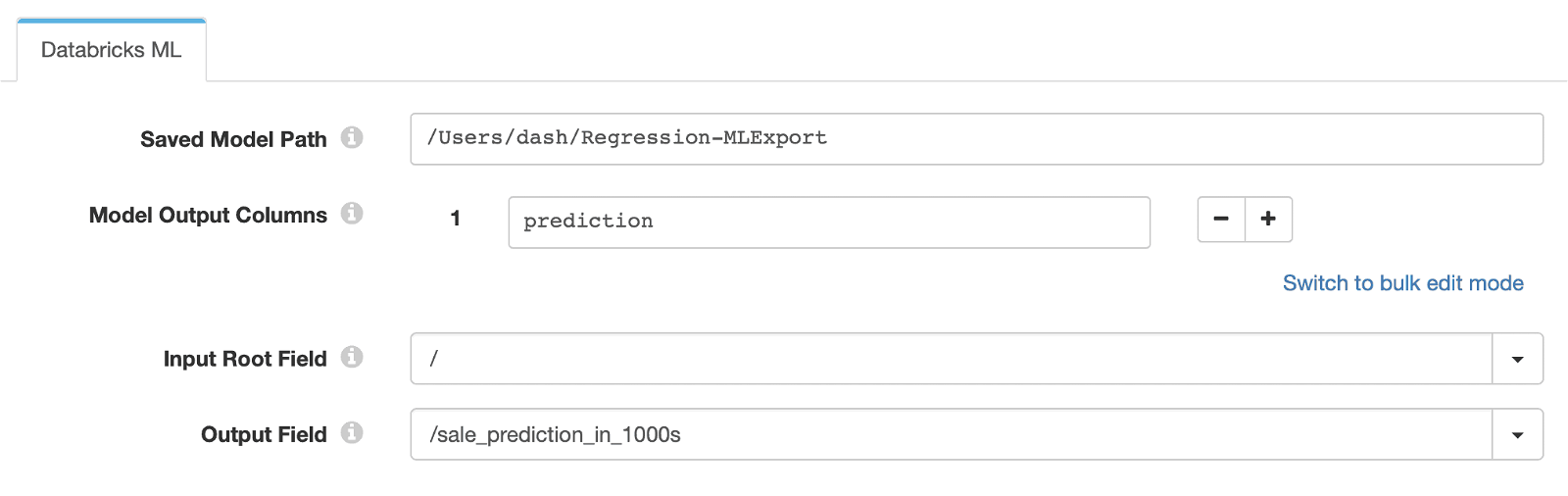
Where;- Saved Model Path is the location of the pre-trained, exported Databricks ML model.
- Model Output Columns is the column(s) we want to retrieve from the model inference output.
- Input Root Field is the field to be passed as model input.
- Model Output Columns is the record field we want the model prediction values to be stored.
Running the Databricks ML Regression Pipeline in Data Collector
To run the sample pipeline in your own Data Collector environment, follow these instructions:
- Download and install Data Collector.
- Import DatabricksML_Regression.json pipeline.
- Uncompress Regression-MLExport.zip model in a local folder, such as /Users/<name>/Regression-MLExport and update Saved Model Path location in Databricks ML Evaluator config accordingly.
If all goes well, running the pipeline should result in:
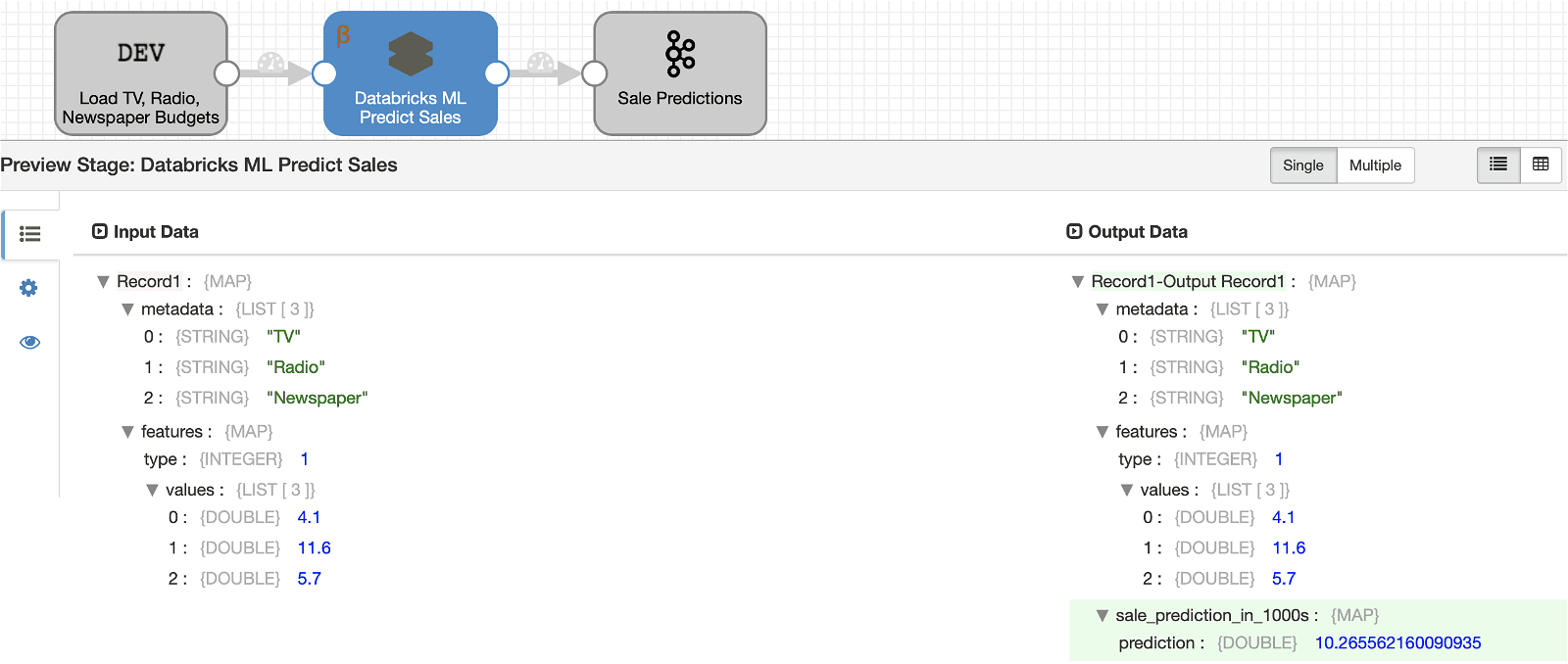
As shown above, model prediction values are stored in record field sale_prediction_in_1000s and records are passed on to Kafka Producer so production application(s) can consume those predictions in a performant and scalable manner using Kafka… pushing your applications to move as fast as your incoming data!
That’s a wrap!
Summary
This blog post illustrated the use of the newly released Databricks ML Evaluator in Data Collector. Generally speaking, this evaluator will enable you to serve pre-trained Databricks ML models for generating predictions and/or classifications without having to write any custom code.
In addition, with Data Collector Edge, you can also run Databricks ML enabled pipelines on devices such as Raspberry Pi and others running on supported platforms.
In coming weeks, I will blog about ML-enabled pipelines running on Data Collector Edge and also about using MLeap and PMML evaluators.
StreamSets Data Collector is open source, under the Apache v2 license.