Learn how to load data from S3 to Snowflake and serve a TensorFlow model in StreamSets Data Collector, a fast data ingestion engine, data pipeline for scoring on data flowing from S3 to Snowflake.
Data and analytics are helping us become faster and smarter at staying healthy. Open data sets and analytics at cloud scale are key to unlocking the accuracy needed to make real impacts in the medical field. Data Clouds like Snowflake are prime enablers for opening up analytics with self-service data access and scale that mirrors the dynamic nature of data today. One prominent pattern and a key initial step is loading data from S3 to Snowflake to get quick value out of your data cloud. However, the value of your Snowflake Data Cloud may never be realized if you can’t load it full of your relational and streaming sources. Smart data pipelines let you send and sync your data from all corners of your business and land it in your data cloud in the right format, ready for analytics. This means you can provide production ready data for data science and machine learning.
Use Case
The use case we’re going to review is of classifying breast cancer tumors as malignant or benign, and to demonstrate we’ll be using the Wisconsin breast cancer dataset made available as part of scikit-learn. To learn how I’ve trained and exported a simple TensorFlow model in Python, checkout my code on GitHub. As you’ll note, the model architecture is kept to a minimum and is pretty simple with only a couple of layers. The important aspect of the code to pay attention is how the model is exported and saved using TensorFlow SavedModelBuilder*.
*Note: To use TensorFlow models in Data Collector, they should be exported/saved using TensorFlow SavedModelBuilder in your choice of supported language such as Python.
What is TensorFlow?
TensorFlow is an open source machine learning framework built for Deep Neural Networks. It was created by the Google Brain Team. TensorFlow supports scalable and portable training on CPUs, GPUs and TPUs. As of today, it is the most popular and active machine learning project on GitHub.
S3 to Snowflake: Data Pipeline Overview
Here’s the overview of the data pipeline.
- Ingest breast cancer tumors data from Amazon S3
- Perform transformations
- Use TensorFlow machine learning model to classify tumor as benign or malignant
- Store breast cancer tumors data along with the cancer classification in Snowflake
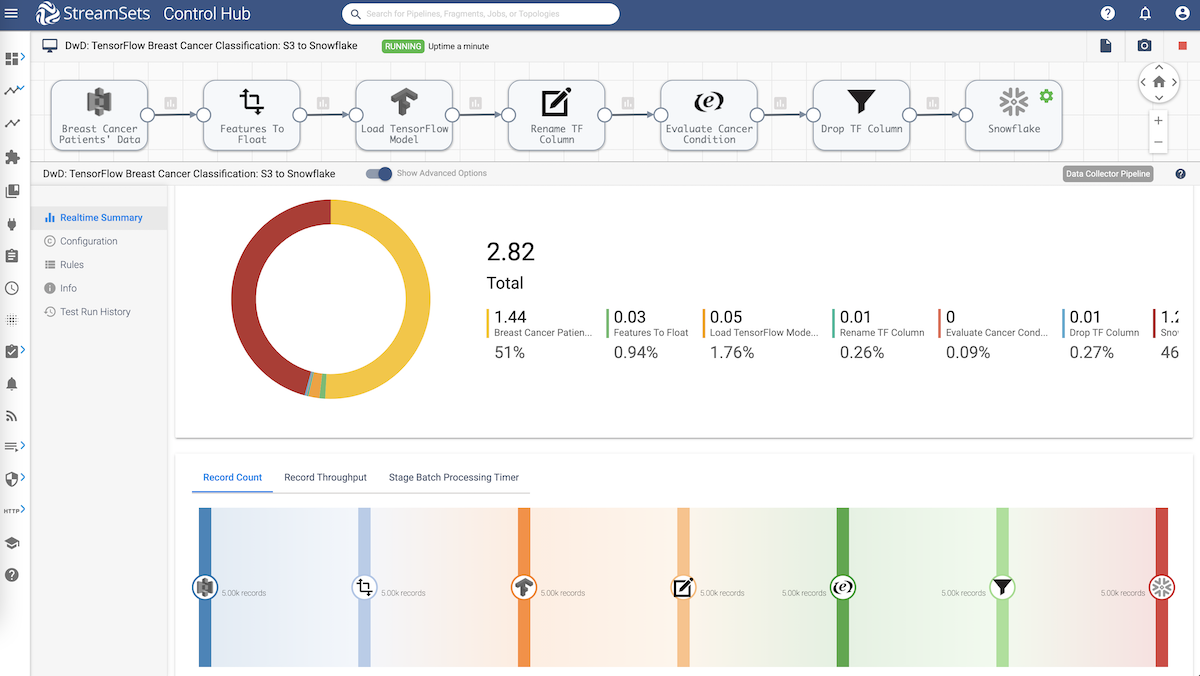
Load Data From S3 to Snowflake
Amazon S3
- The origin will load breast cancer tumor records stored in a .csv file on Amazon S3. Some of the important configuration include:
- AWS credentials — you can use either an instance profile or AWS access keys to authenticate
- Amazon S3 bucket name
- Object/file name or patterns of file names that contain the input data to load from Amazon S3.
Field Converter
- This processor will convert all input columns from String to Float. In this case, all fields need to be included in the list since they are all features that will be used by the TensorFlow model.
TensorFlow Evaluator
- This processor will load a pre-trained TF model to score on data flowing in real-time. Some of the important configuration include:
- Saved Model Path: Location of the pre-trained TF model to be used.
- Model Tags: Set to ‘serve’ because the meta graph (in our exported model) was intended to be used in serving. For more details, see tag_constants.py.
- Input Configs: The input tensor information as configured during training and exporting the model. (See Train model and save/export it using TensorFlow SavedModelBuilder section.)
- Output Configs: The output tensor information as configured during training and exporting the model. (See Train model and save/export it using TensorFlow SavedModelBuilder section.)
- Output Field: Output record field that we’d like to store the classification values.
Field Renamer
- This processor will enable us to rename columns to make them a little more self-explanatory.
Expression Evaluator
- This processor will use the expression ${record:value(‘/classification’) == 0 ? ‘Benign’ : ‘Malignant’ } to evaluate ‘condition’ column value and create a new column with values ‘Benign’ or ‘Malignant’ depending on the tumor classification.
Field Remover
- This processor will enable us to remove columns that we don’t need to store in Snowflake.
Snowflake
- The transformed data is stored in Snowflake. Some of the important configuration include:
- Snowflake Account, Username, Password, Warehouse, Database, Schema and Table name. Note: The pipeline will automatically create the table if it doesn’t already exist. So there’s no need to pre-create it in Snowflake.
- When processing new data, you can configure the Snowflake destination to use the COPY command to load data to Snowflake tables.
- When processing change data capture (CDC) data, you can configure the Snowflake destination to use the MERGE command to load data to Snowflake tables.
S3 to Snowflake: Data Pipeline Execution
Upon executing the S3 to Snowflake pipeline, the input breast cancer tumor records are passed through the data pipeline outlined above including real-time scoring using the TensorFlow model. The output records sent to Snowflake data cloud include breast cancer tumor features used by the model for classification, model output value of 0 or 1, and respective tumor condition Benign or Malignant. See below.
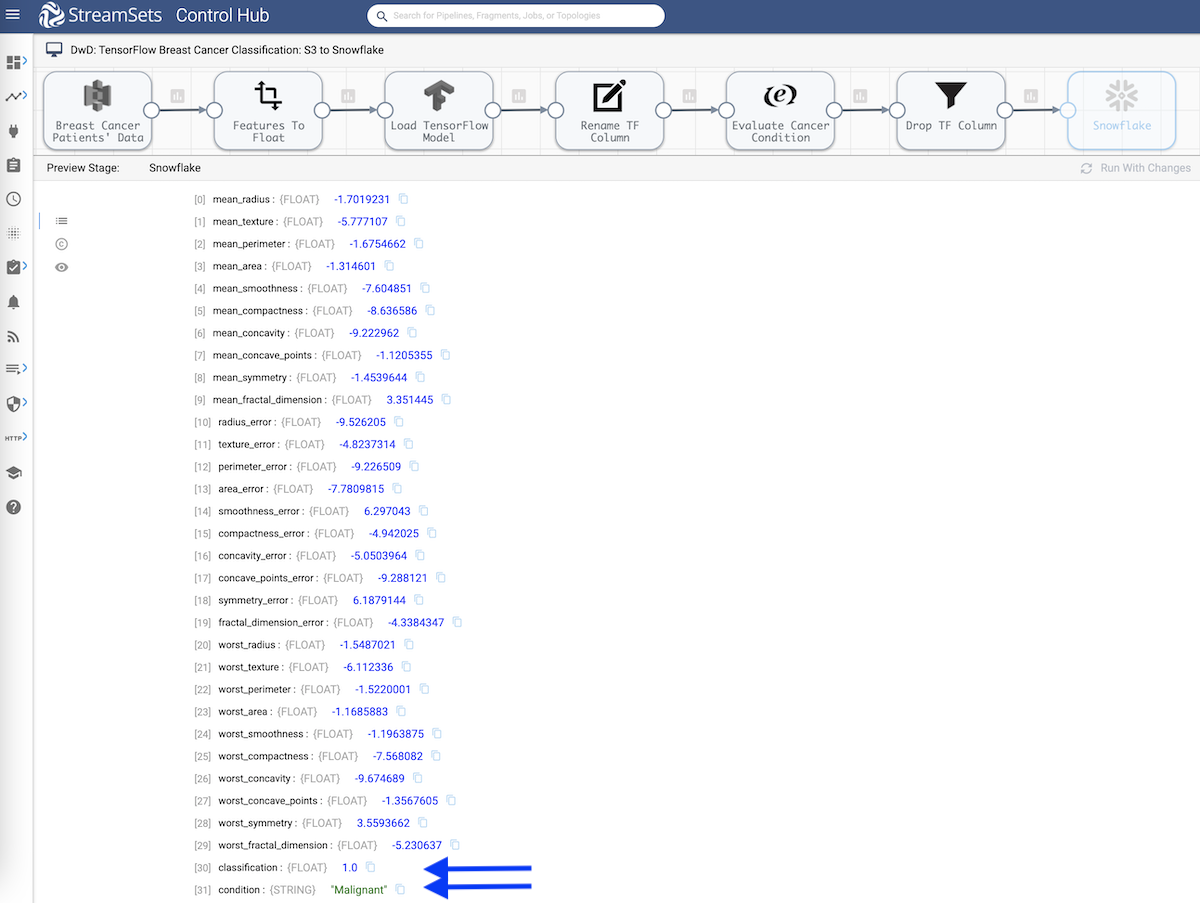
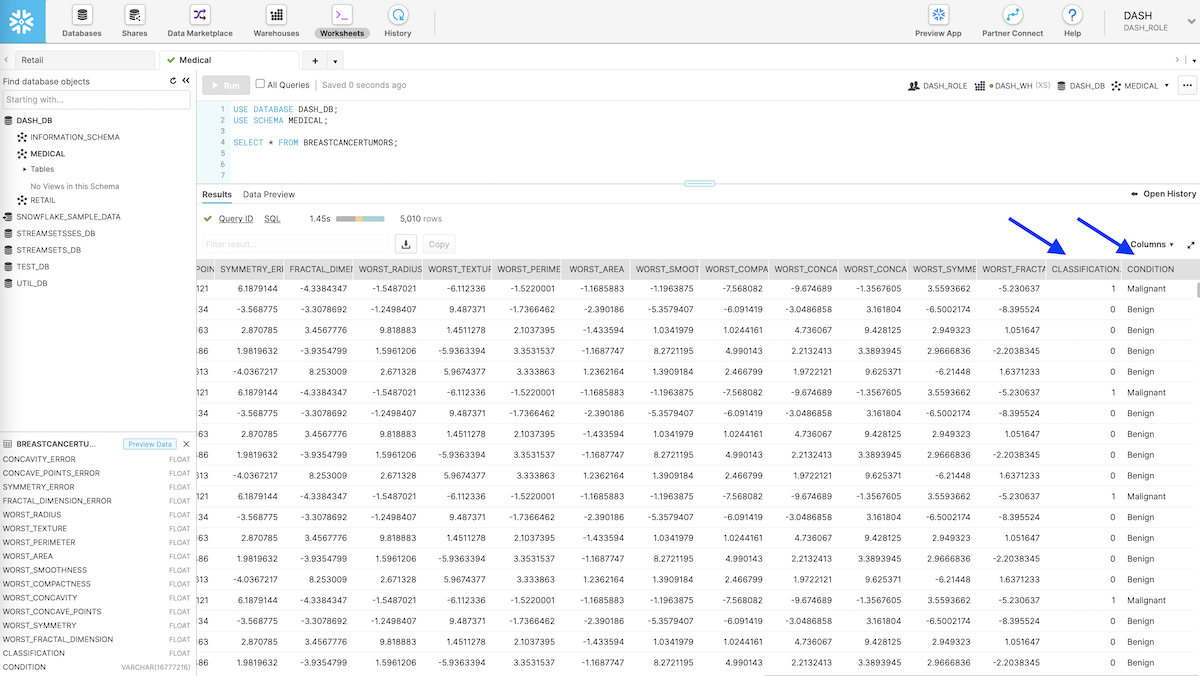

Conclusion
The integration between StreamSets and Snowflake enables data engineers to build smart data pipelines to load data synchronously as well as asynchronously. A good example of synchronous load is multi-table, real-time replication using change data capture (CDC) and for asynchronous, high-throughput, and pure-inserts type of workloads data engineers can leverage Snowpipe integration in StreamSets.
Get started with your S3 to Snowflake integration today by deploying a Data Collector Engine, a fast data ingestion engine, in the StreamSets DataOps Platform.
On-demand Webinar: I also encourage you to watch this webinar where I’ve demonstrated building an orchestrated pipeline in SDC to first migrate Oracle data warehouse to Snowflake Data Cloud and then automatically kick-off a Change Data Capture (CDC) pipeline to keep the two in sync.