Change Data Capture is becoming essential to migrating to the cloud. In this blog, I have outlined detailed explanations and steps to load Change Data Capture (CDC) data from PostgreSQL to Redshift using StreamSets Data Collector, a fast data ingestion engine.
The data pipeline first writes PostgreSQL CDC data to Amazon S3 and then executes a set of queries to perform an upsert operation on Amazon Redshift. The set of queries executed includes Amazon S3 COPY command, which leverages Amazon Redshift’s massively parallel processing (MPP) architecture to read and load data in parallel from files stored in the Amazon S3 bucket.
What is an upsert operation?
An upsert operation enables you to either insert a new record or update an existing record within the same transaction. To determine whether a record already exists or not, the set of queries rely on the incoming records’ primary key(s).
Load Change Data Capture data from PostgreSQL to Redshift
Prerequisites
- Access to an instance of StreamSets Data Collector Engine (SDC)
- Also download JDBC drivers for PostgreSQL and Redshift. (I used postgresql-42.2.5.jar and RedshiftJDBC42-no-awssdk-1.2.41.1065.jar)
- Once you have the drivers, use Package Manager to install them in SDC.
- Access to a Amazon Redshift cluster
- Access to Amazon RDS for PostgreSQL. (I used version 11.6)
Enable CDC in Your PosgreSQL to Redshift Pipeline
- Note: Users connecting to the database must have the replication or superuser role.
- On the Amazon RDS for PostgreSQL instance, make sure that in the associated parameter group rds.logical_replication is enabled (i.e. set to 1)
- If you do not have permissions to edit the existing parameter group, you can create a new parameter group, then set rds.logical_replication parameter to 1, leave the other values to their defaults, and add this new group to the Amazon RDS instance.
- In PSQL, do the following:
- Create the replication slot.
- SELECT pg_create_logical_replication_slot(‘your_replication_slot_name_goes_here‘, ‘wal2json’);
- Create a role with the replication attribute for use by PostgreSQLReader and give it select permission on the schema(s) containing the tables to be read.
- CREATE ROLE your_role_name_goes_here WITH LOGIN PASSWORD ‘your_password_goes_here’;
- GRANT rds_replication TO your_role_name_goes_here;
- GRANT SELECT ON ALL TABLES IN SCHEMA your_schema_name_goes_here TO your_role_name_goes_here;
- Create the replication slot.
-
- For example:
- SELECT pg_create_logical_replication_slot(‘streamsets_slot’, ‘wal2json’);
- CREATE ROLE streamsets WITH LOGIN PASSWORD ‘strong!password’;
- GRANT rds_replication TO streamsets;
- GRANT SELECT ON ALL TABLES IN SCHEMA public TO streamsets;
- For example:
Protip: StreamSets also makes it easy to write the data to Snowflake Data Cloud, Delta Lake on Databricks or both in a single data pipeline.
If you’d like to follow along, here are the PostgreSQL and Amazon Redshift table structures and schemas for the table I’ve used in this example:
#### PostgreSQL
CREATE TABLE "companies" (
"id" int4 NOT NULL DEFAULT nextval('companies_id_seq'::regclass),
"name" bpchar(60),
"type" bpchar(60),
"funding" numeric(12,5),
PRIMARY KEY ("id")
);
#### Amazon Redshift
CREATE TABLE companies(
id bigint NOT NULL,
name varchar(60),
type varchar(60),
funding decimal(12,5),
PRIMARY KEY(id)
);
Data Pipeline Overview | PostgreSQL to Redshift
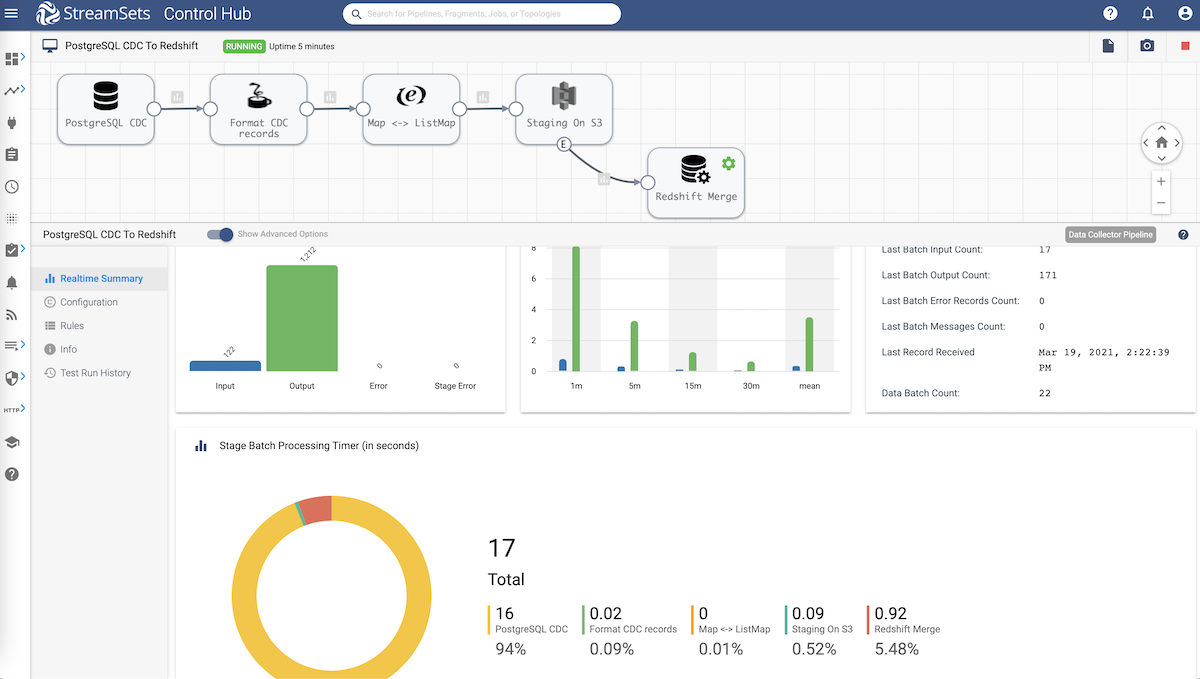
PostgreSQL CDC Client
- The origin for reading the Write-Ahead Logging (WAL) records in the data pipeline is PostgreSQL CDC Client. This origin generates a single record for each transaction. And because every transaction can include multiple CRUD operations, it can also include multiple operations on a record.
- Some of the important configuration attributes include:
- Schema, Table Name Pattern (name of the table or a pattern that matches a set of tables), Initial Change (from where to start reading the records), Operations (CRUD operations to capture; in our case Insert and Update), Replication Slot, JDBC Connection String (in the format jdbc:postgresql://<host>:<port>/<dbname>), and Credentials (to connect to the database.)
- For more details on other configuration attributes, click here.
Note: Users connecting to the database must have the replication or superuser role.
Jython Evaluator
It’s time to add processors in your PostgreSQL to Redshift pipeline.
- In the Jython Evaluator processor, add this Jython code on GitHub that will reformat WAL records for easier downstream processing.
Expression Evaluator
- Using the Expression Evaluator processor, we will convert the new record from List to ListMap with a simple expression where Output Field is set to ‘/’ which evaluates to the record root and Field Expression is set to ${record:value(‘/’)} which represents the entire record.

StreamSets enables data engineers to build end-to-end smart data pipelines. Spend your time building, enabling and innovating instead of maintaining, rewriting and fixing.
Amazon S3
- Amazon S3 is one of the key components of the pipeline not only because it’s where the transformed CDC data is written, but also because writing to S3 enables us to use Amazon COPY command to load PostgreSQL CDC data from Amazon S3 to Redshift in a massively parallel processing (MPP) fashion. (More on this in the JDBC Query section below.)
- Some of the important configuration attributes include:
- Produce Events: Enabling this option will cause the destination to generate events and the one that we’re most interested in is S3 Object Written which is generated when a set/batch of CDC records are written to S3. When this event is generated, JDBC Query executor will kick-off an upsert operation for those records on Amazon Redshift. (See below.)
- Data Format (set to JSON in our case), JSON Content (set to Multiple JSON objects in our case), Bucket, Authentication Method, and Object Name Suffix (set to json in our case). For more details on other configuration attributes, click here.
JDBC Query
- JDBC Query executor is where the meat of the data pipeline is encapsulated!
- Some of the important configuration attributes include:
- JDBC Connection String (in the format jdbc:redshift://<hostname>:<port>/<dbname>) and Credentials to connect to the Amazon Redshift cluster.
- Precondition set to ${record:eventType() == “S3 Object Written”}
- SQL Queries to load PostgreSQL CDC data (specifically inserts and updates) from Amazon S3 to Redshift as an upsert operation including Amazon COPY command to first load data from Amazon S3.
BEGIN transaction;
CREATE TABLE ${REDSHIFT_SCHEMA}.t_staging (LIKE ${REDSHIFT_SCHEMA}.${REDSHIFT_TABLE});
COPY ${REDSHIFT_SCHEMA}.t_staging
FROM '${AWS_BUCKET}'
CREDENTIALS 'aws_access_key_id=${AWS_KEY};aws_secret_access_key=${AWS_SECRET}'
FORMAT AS JSON 'auto';
UPDATE ${REDSHIFT_SCHEMA}.${REDSHIFT_TABLE}
SET name = s.name, type = s.type, funding = s.funding
FROM ${REDSHIFT_SCHEMA}.t_staging s
WHERE ${REDSHIFT_TABLE}.id = s.id;
INSERT INTO ${REDSHIFT_SCHEMA}.${REDSHIFT_TABLE}
SELECT s.* FROM ${REDSHIFT_SCHEMA}.t_staging s LEFT JOIN ${REDSHIFT_SCHEMA}.${REDSHIFT_TABLE}
ON s.id = ${REDSHIFT_SCHEMA}.${REDSHIFT_TABLE}.id
WHERE ${REDSHIFT_SCHEMA}.${REDSHIFT_TABLE}.id IS NULL;
DROP TABLE ${REDSHIFT_SCHEMA}.t_staging;
END transaction;
- Here’s what happening in the above set of SQL queries:
- Begin transaction — a single, logical unit of work which is committed as a whole
- Create temporary (“t_staging”) table in Redshift with the schema identical to the primary table identified as ${REDSHIFT_TABLE}
- Use Amazon COPY command to load PostgreSQL CDC data stored on Amazon S3 in JSON format into the temporary (“t_staging”) table in Redshift
- Execute UPDATE query to update all records where the primary keys match between the temporary (“t_staging”) table and the primary table identified as ${REDSHIFT_TABLE}
- Execute INSERT query to insert new records in the main table if the record primary key in the temporary (“t_staging”) table doesn’t exist in the primary table identified as ${REDSHIFT_TABLE}
- Drop temporary (“t_staging”) table
- End transaction — commit the current transaction
Note: REDSHIFT_SCHEMA, REDSHIFT_TABLE, AWS_BUCKET, AWS_KEY, and AWS_SECRET referenced in the SQL queries above are defined as pipeline parameters, one of the 13 data engineering best practices, in order to make the pipeline reusable (for other schemas and tables via Job Templates, for example) and also to keep the set of SQL queries as dynamic as possible.
Summary
In this post, I’ve reviewed the value that is realized by leveraging and integrating technologies like StreamSets Data Collector Engine and Amazon Web Services.
Learn more about building data pipelines with StreamSets, how to process CDC information from Oracle 19c database and StreamSets for Amazon Web Services.
If you like this topic and would like to continue similar conversations focused on data engineering, join the community.