The real value of a modern DataOps platform is realized only when business users and applications are able to access raw and aggregated data from a range of sources, and produce data-driven insights in a timely manner. And with Machine Learning (ML), analysts and data scientists can leverage historical data to help make better, data-driven business decisions—offline and in real-time using technologies such as TensorFlow.
In this blog post, you will learn how to use TensorFlow Evaluator* in StreamSets Data Collector to serve pre-trained TF models for generating predictions and/or classifications without having to write any custom code.
*Note: TensorFlow Evaluator belongs to Technology Preview family of beta stages and should not be used in production until it has been promoted out of beta.
*UPDATE: As of Data Collector version 3.7.0, TensorFlow Evaluator is no longer considered a Technology Preview feature and is approved for use in production.
Before we dive into the details, here are some basic concepts.
Machine Learning
Arthur Samuel described it as: “The field of study that gives computers the ability to learn without being explicitly programmed.” With recent advances in machine learning, computers now have the ability to make predictions as well as or even better than humans and it can feel like it can solve any problem. Let’s begin by reviewing exactly what kind of problems it solves.
Generally speaking, ML is classified into two broad categories:
Supervised Learning
“Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs.” — Wikipedia.
It involves constructing an accurate model which can predict an outcome when historical data has been labeled for those outcomes.
Common business problems addressed by supervised learning:
- Binary classification (learning to predict a categorical value)
– Will a customer buy a particular product or not?
– Is this cancer malignant or benign? - Multiclass classification (learning to predict a categorical value)
– Is a given piece of text toxic, threatening, or obscene?
– Is the species of this Iris flower setosa, versicolor, or virginica? - Regression (learning to predict a continuous value)
– What is the predicted selling price of a house?
– What will the temperature be in San Francisco tomorrow?
Unsupervised learning
Allows us to approach problems with little or no idea of what our outputs should look like. It involves constructing models where labels on past data are unavailable. In these types of problems, the structure is derived by clustering the data based on relationships among the variables in the data.
The two common approaches for unsupervised learning are K-means clustering and DBSCAN.
Note: the TensorFlow Evaluator in Data Collector and Data Collector Edge currently only supports supervised learning models.
Neural Networks And Deep Learning
Neural Networks are a form of ML algorithm that can learn and use a model of computing inspired by the structure of the human brain. Neural Networks have proven to be highly accurate compared to other ML algorithms such as decision trees, logistic regression, etc.
Deep learning is a subset of Neural Networks which allows the networks to represent a wide variety of concepts in a nested hierarchy.
Andrew Ng has described it in the context of traditional artificial neural networks. In his talk titled “Deep Learning, Self-Taught Learning and Unsupervised Feature Learning”, he described the idea of Deep Learning as:
“Using brain simulations, hope to:
– Make learning algorithms much better and easier to use.
– Make revolutionary advances in machine learning and AI.
I believe this is our best shot at progress towards real AI.”
Common neural networks and deep learning applications include:
- Computer Vision / Image Recognition / Object Detection
- Speech Recognition / Natural Language Processing (NLP)
- Recommendation Systems (Products, Matchmaking, etc.)
- Anomaly Detection (Cybersecurity, etc.)
TensorFlow
TensorFlow is open source ML framework designed for deep Neural Networks and created by the Google Brain Team. TensorFlow supports scalable and portable training on Windows and Mac OS — on CPUs, GPUs and TPUs. As of today, it is the most popular and active ML project on GitHub.
For more details, visit TensorFlow.org.
TensorFlow in Data Collector
With the introduction of the TensorFlow Evaluator you are now able to create pipelines that ingest data/features and generate predictions or classifications within a contained environment—without having to initiate HTTP or REST API calls to ML models served and exposed as web services. For example, Data Collector pipelines can now detect fraudulent transactions or perform natural language processing on text in real-time as data is passing through various stages before being stored in the final destination—for further processing or decision making.
In addition, with Data Collector Edge, you can run TensorFlow ML enabled pipelines on devices such as Raspberry Pi and others running on supported platforms. For example, to detect natural disasters like floods in high-risk areas to prevent damages to valuable assets.
Breast Cancer Classification
Let’s consider the use case of classifying breast cancer tumor as being malignant or benign. The (Wisconsin) breast cancer is a classic dataset and is available as part of scikit-learn. To see how I’ve trained and exported a simple TF model using this dataset in Python, checkout my code on GitHub. As you’ll notice, the model creation and training is kept to a minimum and is pretty simple with only a couple of hidden layers. The most important aspect to pay attention to is how the model is exported and saved using TensorFlow SavedModelBuilder*.
*Note: To use TF models in Data Collector or Data Collector Edge, they should be exported/saved using TensorFlow SavedModelBuilder in your choice of supported language such as Python and interactive environment such as Jupiter Notebook.
Once the model is trained and exported using TensorFlow SavedModelBuilder, using it in your dataflow pipelines for prediction or classification is pretty straightforward—as long as the model is saved in a location accessible by Data Collector.
Pipeline Overview
Before diving into details, here’s what the pipeline looks like.

Pipeline Details
- Directory Origin
- This will load breast cancer records from a .csv file. (Note: this input data source can be easily replaced with other origins including Kafka, AWS S3, or for a MySQL instance.)
- Field Converter
- This processor will convert all input breast cancer record features to be used by the model from String to Float.
mean_radius,mean_texture,mean_perimeter,mean_area,mean_smoothness,mean_compactness,mean_concavity,mean_concave_points,mean_symmetry,mean_fractal_dimension,radius_error,texture_error,perimeter_error,area_error,smoothness_error,compactness_error,concavity_error,concave_points_error,symmetry_error,fractal_dimension_error,worst_radius,worst_texture,worst_perimeter,worst_area,worst_smoothness,worst_compactness,worst_concavity,worst_concave_points,worst_symmetry,worst_fractal_dimension
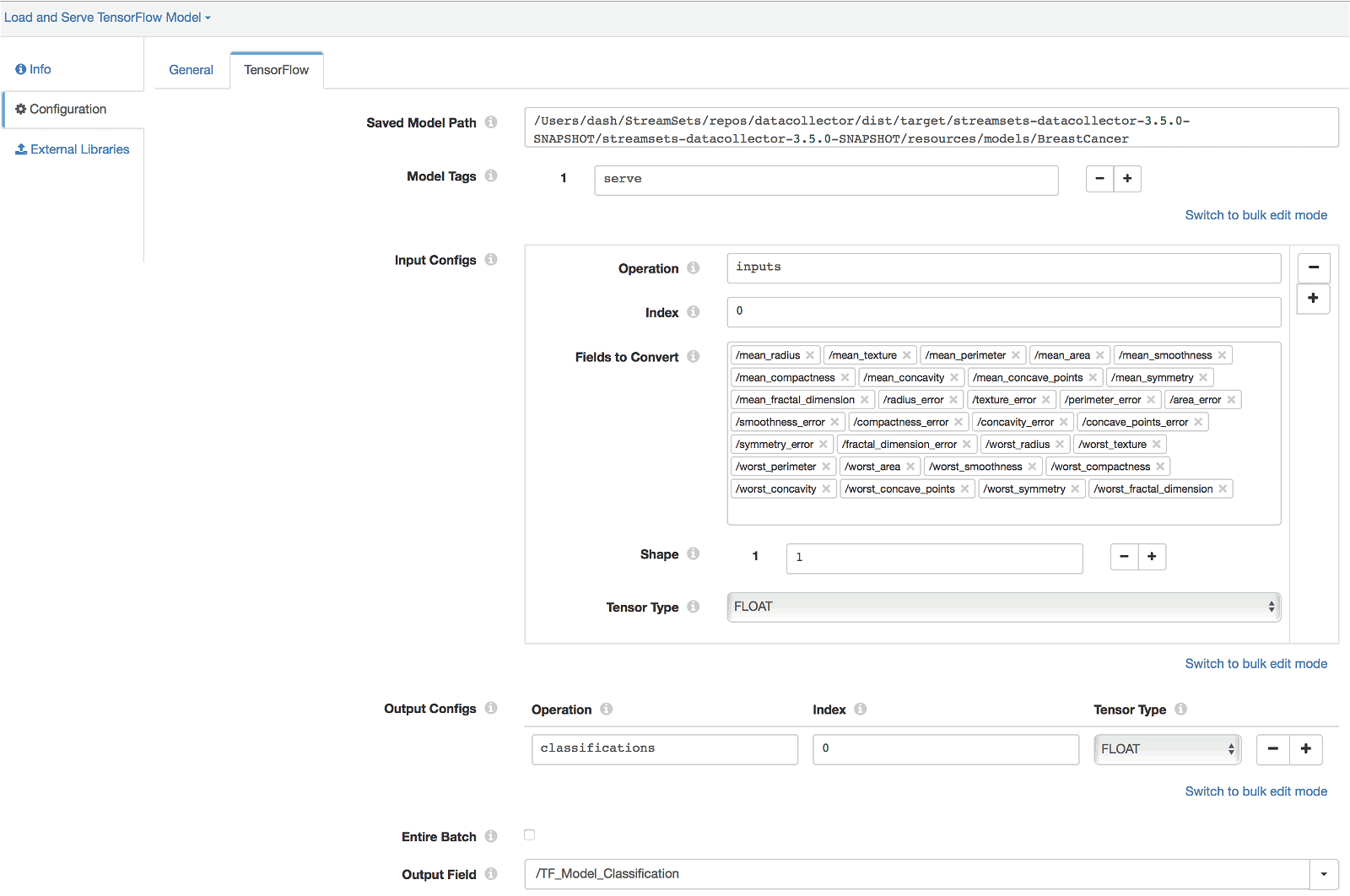
- TensorFlow Evaluator*
- Saved Model Path: Specify location of the pre-trained TF model to be used served.
- Model Tags: Set to ‘serve’ because the meta graph (in our exported model) was intended to be used in serving. For more details, see tag_constants.py and related TensorFlow API documentation.
- Input Configs: Specify the input tensor information as configured during training and exporting the model. (See Train model and save/export it using TensorFlow SavedModelBuilder section.)
- Output Configs: Specify the output tensor information as configured during training and exporting the model. (See Train model and save/export it using TensorFlow SavedModelBuilder section.)
- Output Field: Output record field that we’d like to store the classification values.
- Expression Evaluator
- This processor evaluates model output/classification value of 0 or 1 (stored in output field TF_Model_Classification) and creates a new record field ‘Condition’ with values Benign or Malignant respectively.
- Stream Selector
- This processor evaluates cancer condition (Benign or Malignant) and routes records to respective Kafka producers.
- Kafka Producers
- Input records along with model output/classification values are conditionally routed to two Kafka producers for further processing snd analysis. (Note: these destinations can be easily replaced with other destination(s) such as AWS S3, MySQL, NoSQL, etc. for further processing and/or analysis.)
*TensorFlow Evaluator Configuration
Note: Once the TensorFlow Evaluator produces model output, the pipeline stages that follow in this example are optional and interchangeable with other processors and destinations as required by the use case.
Pipeline Execution
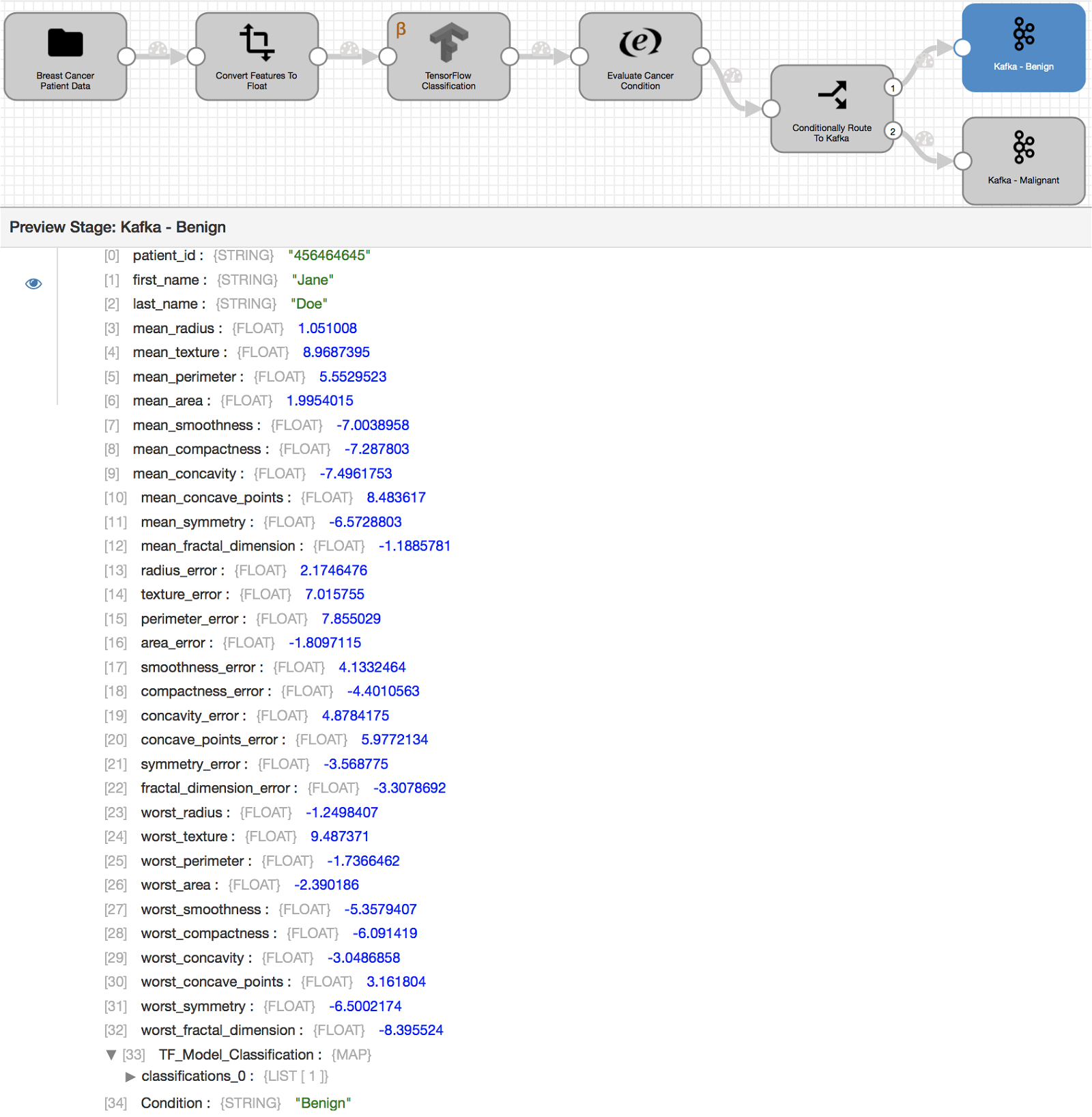
Upon previewing (or executing) the pipeline, the input breast cancer records are passed through dataflow pipeline stages outlined above including serving our TensorFlow model. The final output records sent to Kafka producers (as shown above) include breast cancer features used by the model for classification, model output value of 0 or 1 in user-defined field TF_Model_Classification, and respective cancer condition Benign or Malignant in field Condition created by Expression Evaluator.
Summary
This blog post illustrated the use of the newly released TensorFlow Evaluator in Data Collector 3.5.0. Generally speaking, this evaluator will enable you to serve pre-trained TF models for generating predictions and/or classifications without having to write any custom code.
You can deploy Data Collector, fast ingestion engine, on your choice of cloud provider or you can download it for local development.