Learn how StreamSets, a modern data integration platform for DataOps, can help expedite operations at some of the most crucial stages of Machine Learning Lifecycle and MLOps.
Data Acquisition And Preparation
Machine learning models are only as good as the quality of data and the size of datasets used to train the models. Data has shown that data scientists spend around 80% of their time on preparing and managing data for analysis and 57% of the data scientists regard cleaning and organizing data as the least enjoyable part of their work. This further validates the idea of MLOps and the need for collaboration between data scientists and data engineers.
During this crucial phase of data acquisition and preparation, data scientists identify what types of (trusted) datasets are needed to train models and work closely with data engineers to acquire data from viable data sources.
How Can StreamSets Help
Some of the common data sources for acquiring datasets for data science projects include: Amazon S3, Microsoft Azure Blob Storage, Google Cloud Storage, Kafka, Hadoop, on-prem and cloud data warehouses. StreamSets DataOps Platform provides easy-to-use GUI for building smart data pipelines for streaming and batch dataflows for fast data ingestion of large amounts of data from distributed systems–including all of the common sources mentioned above.
Another aspect of the data ingestion process is the storage–in some cases, companies may already have a data lake or a data warehouse and in some cases they may need to build one. StreamSets DataOps Platform is capable of connecting to existing data lakes and data warehouses (on-prem or in the cloud) and also has built-in capabilities of creating new ones.
As part of building these data pipelines, data engineers can also perform some of the key transformations needed by data scientists. Some of the common transformations required during data preparation include: data type conversion for fields/columns/features, renaming fields/columns/features, joining datasets, merging datasets, repartitioning, dataset data format conversion (for example, JSON to Parquet for efficient downstream analysis in Apache Spark), etc. All of these transformations and many more are readily supported by StreamSets DataOps Platform.
Imp Note: Extensive and thorough feature engineering tasks and in depth analysis of features, their correlation with the target variable, feature importances, etc. is best suited for and better performed on interactive tools, such as, Databricks Notebook, Jupyter, RStudio, and ML platforms.
Model Experiments, Tracking, And Registration
Experimentation is a big precursor to model development where data scientists take sufficient subsets of trusted datasets and create several models in a rapid, iterative manner.
Without proper industry standards, data scientists have to rely on manual tracking of models, inputs, hyperparameters, outputs and any other such artifacts throughout the model experimentation and development process. This results in very long model deployment/release cycles, which effectively prevents organizations from adapting to dynamic changes, gaining competitive advantage, and in some cases staying in compliance with changing governance and regulations.
How Can StreamSets Help
Using StreamSets Transformer, a Spark ETL engine, it’s easy to integrate with MLflow using its PySpark or Scala APIs.
- This MLflow integration allows for tracking and versioning of model training code, data, config, hyperparameters as well as register and manage models in a central repository in MLflow from Transformer. This is critical for retraining models and/or for reproducing experiments.
- When using MLflow on Databricks, this creates a powerful and seamless solution because Transformer can run on Databricks clusters and Databricks comes bundled with MLflow server.
End-to-end Use Case
Let’s walk through an end-to-end scenario where we’ll ingest data from a cloud object storage (for example, Amazon S3), perform necessary transformations, and train a regression model. The dataset consists of a set of houses with features like number of bedrooms, bathrooms, square footage, etc. and the price it was sold at.
Apart from tracking, versioning, and registering models in MLflow with every run we’d also like the pipeline to automatically promote models from “staging” to “production” provided they meet a certain set of conditions. For example, if r2 >= ${r2Threshold} or rmse <= ${rmseThreshold}, then the model needs to be promoted to “Production” on MLflow server on Databricks. This can be one of the requirements and part of the specification given by the data scientists to the data engineering team responsible for deploying the models.
Pipeline Overview
The StreamSets Transformer pipeline shown below is designed to load training data from Amazon S3, perform transformations like remove row id, rename target column “mdev” to “label” (which is required by SparkMLlib), train Gradient Boosted Regression model using PySpark processor and archive the training data in Amazon S3.
More importantly, the pipeline also integrates with MLflow on Databricks to track and version model training code including hyperparameters, model evaluation metrics, and register models.
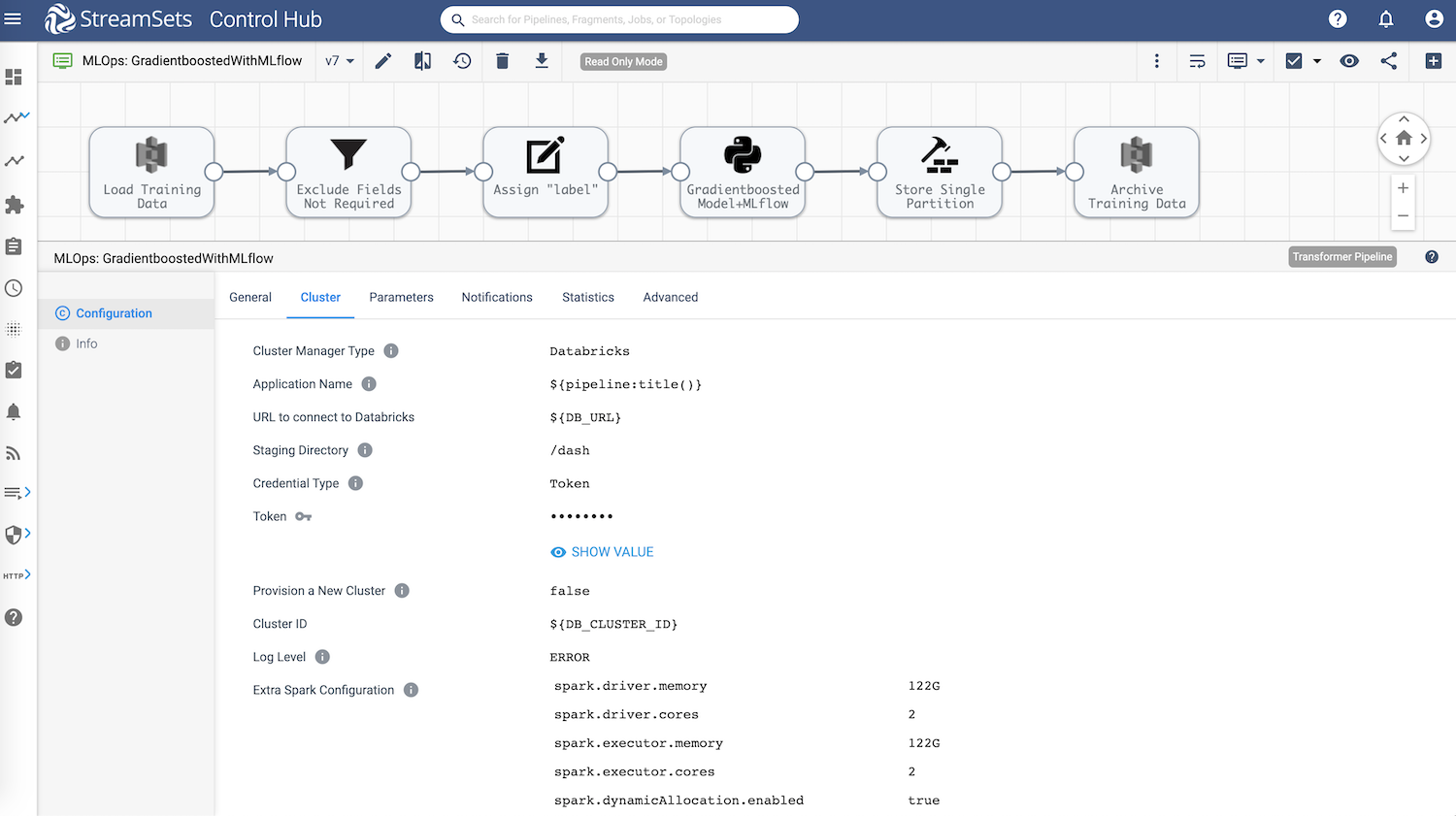
Model Training And Experimentation
Here’s the code snippet of interest in PySpark Processor — this is part of the pipeline that trains the Gradient Boosted Regression model and tracks everything in MLflow including promoting models from “staging” to “production” based on certain conditions.
# Import required libraries
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.linalg import Vectors
from pyspark.ml import Pipeline, PipelineModel
from pyspark.sql.functions import *
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
from pyspark.ml.evaluation import MulticlassClassificationEvaluator, RegressionEvaluator
from pyspark.ml.regression import GBTRegressor
from pyspark.sql.types import FloatType
import mlflow
import mlflow.spark
import mlflow.tracking
mlflow.set_experiment('/Users/dash@streamsets.com/transformer-experiments')
mlflow_client = mlflow.tracking.MlflowClient()
# Setup variables for convenience and readability
trainSplit = ${trainSplit}
testSplit = ${testSplit}
maxIter = ${maxIter}
numberOfCVFolds = ${numberOfCVFolds}
r2 = 0
rmse = 0
stage = "Staging"
# The input dataframe is accessbile via inputs[0]
df = inputs[0]
features = ['crim', 'zn', 'indus', 'chas', 'nox', 'rm', 'age', 'dis', 'rad', 'tax', 'ptratio', 'black', 'lstat']
# MUST for Spark features
vectorAssembler = VectorAssembler(inputCols = features, outputCol = 'features')
df = vectorAssembler.transform(df)
# Split dataset into "train" and "test" sets
(train, test) = df.randomSplit([trainSplit, testSplit], 42)
# Setup evaluator -- default is F1 score
classEvaluator = MulticlassClassificationEvaluator(metricName="accuracy")
with mlflow.start_run():
# Gradient-boosted tree regression
gbt = GBTRegressor(maxIter=maxIter)
# Setup pipeline
pipeline = Pipeline(stages=[gbt])
# Setup hyperparams grid
paramGrid = ParamGridBuilder().build()
# Setup model evaluators
rmseevaluator = RegressionEvaluator() #Note: By default, it will show how many units off in the same scale as the target -- RMSE
r2evaluator = RegressionEvaluator(metricName="r2") #Select R2 as our main scoring metric
# Setup cross validator
cv = CrossValidator(estimator=pipeline, estimatorParamMaps=paramGrid, evaluator=r2evaluator, numFolds=numberOfCVFolds)
# Fit model on "train" set
cvModel = cv.fit(train)
# Get the best model based on CrossValidator
model = cvModel.bestModel
# Run inference on "test" set
predictions = model.transform(test)
rmse = rmseevaluator.evaluate(predictions)
r2 = r2evaluator.evaluate(predictions)
mlflow.log_param("transformer-pipeline-id","${pipeline:id()}")
mlflow.log_param("features", features)
mlflow.log_param("maxIter_hyperparam", maxIter)
mlflow.log_param("numberOfCVFolds_hyperparam", numberOfCVFolds)
mlflow.log_metric("rmse_metric_param", rmse)
mlflow.log_metric("r2_metric_param", r2)
# Log and register the model
mlflow.spark.log_model(spark_model=model, artifact_path="SparkML-GBTRegressor-model", registered_model_name="SparkML-GBTRegressor-model")
mlflow.end_run()
# Transition the current model to 'Staging' or 'Production'
current_version = mlflow_client.search_model_versions('name="SparkML-GBTRegressor-model"')[0].version
while mlflow_client.search_model_versions('name="SparkML-GBTRegressor-model"')[0].status != 'READY':
current_version = current_version
if (r2 >= ${r2Threshold} or rmse <= ${rmseThreshold}):
stage = "Production"
mlflow_client.transition_model_version_stage(name="SparkML-GBTRegressor-model",stage=stage,version=current_version)
output = inputs[0]
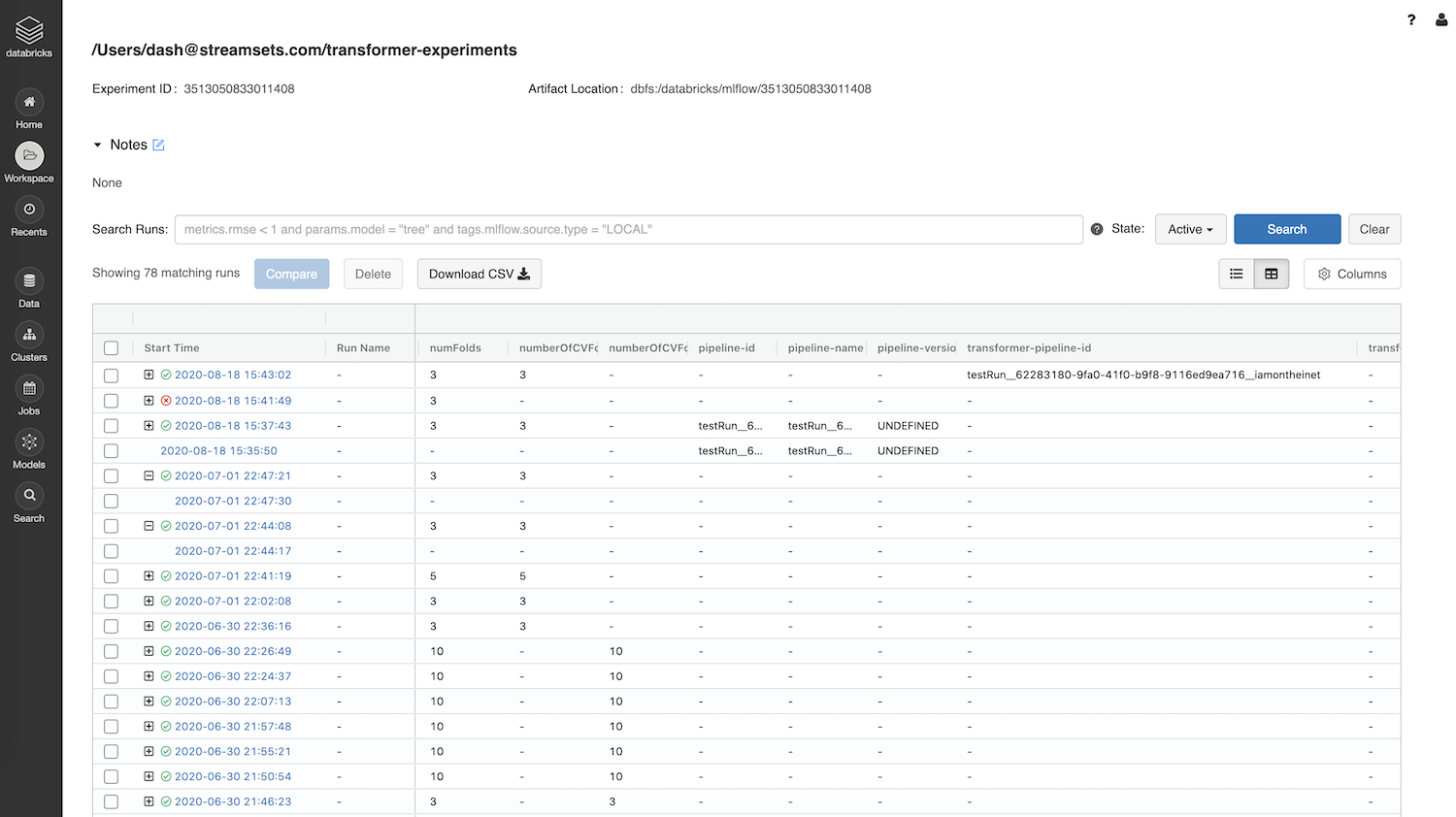
Model Tracking in MLflow On Databricks
Here are the model training runs from the Transformer pipeline tracked in MLflow.
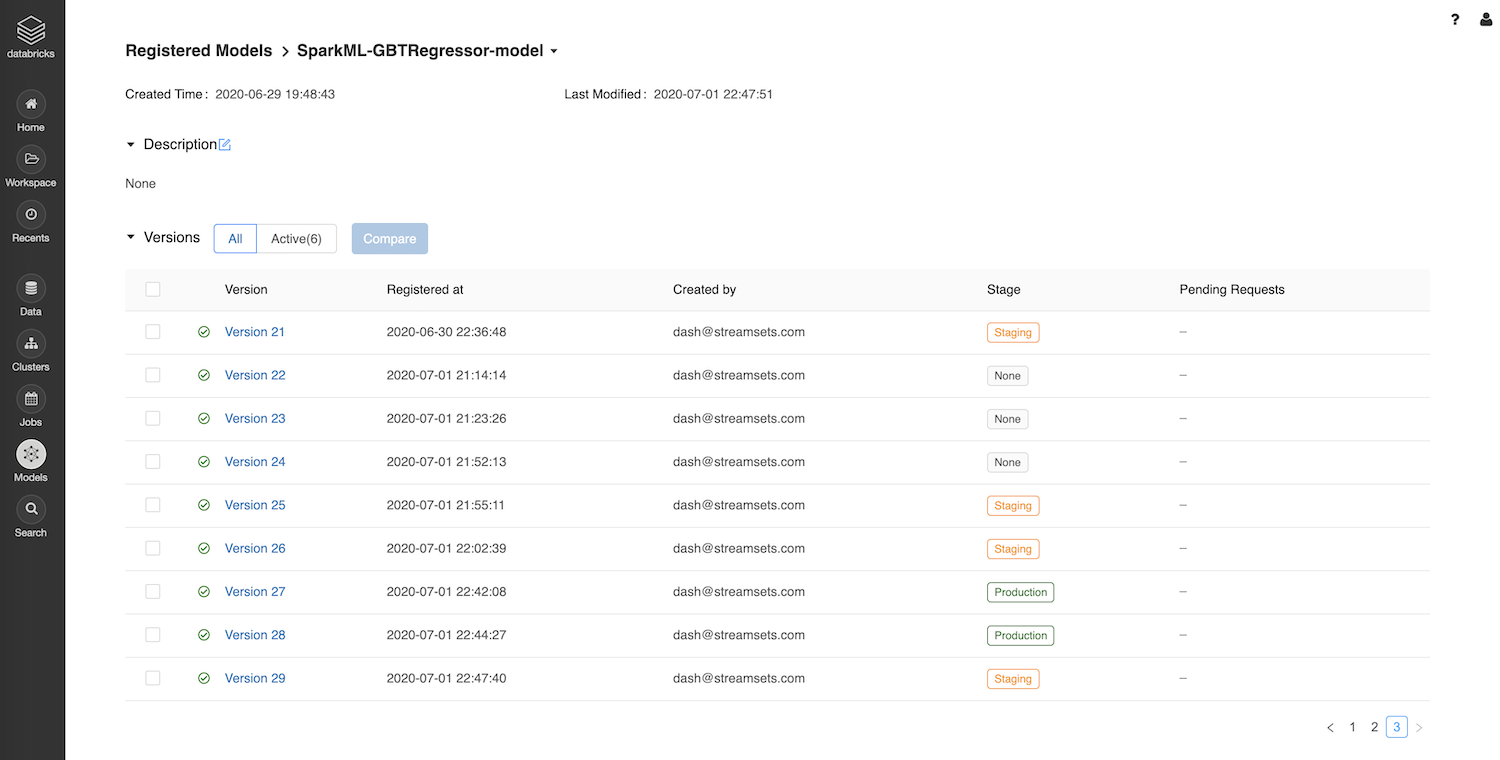
Model Versioning in MLflow On Databricks
Here are the model versions registered from the Transformer pipeline.
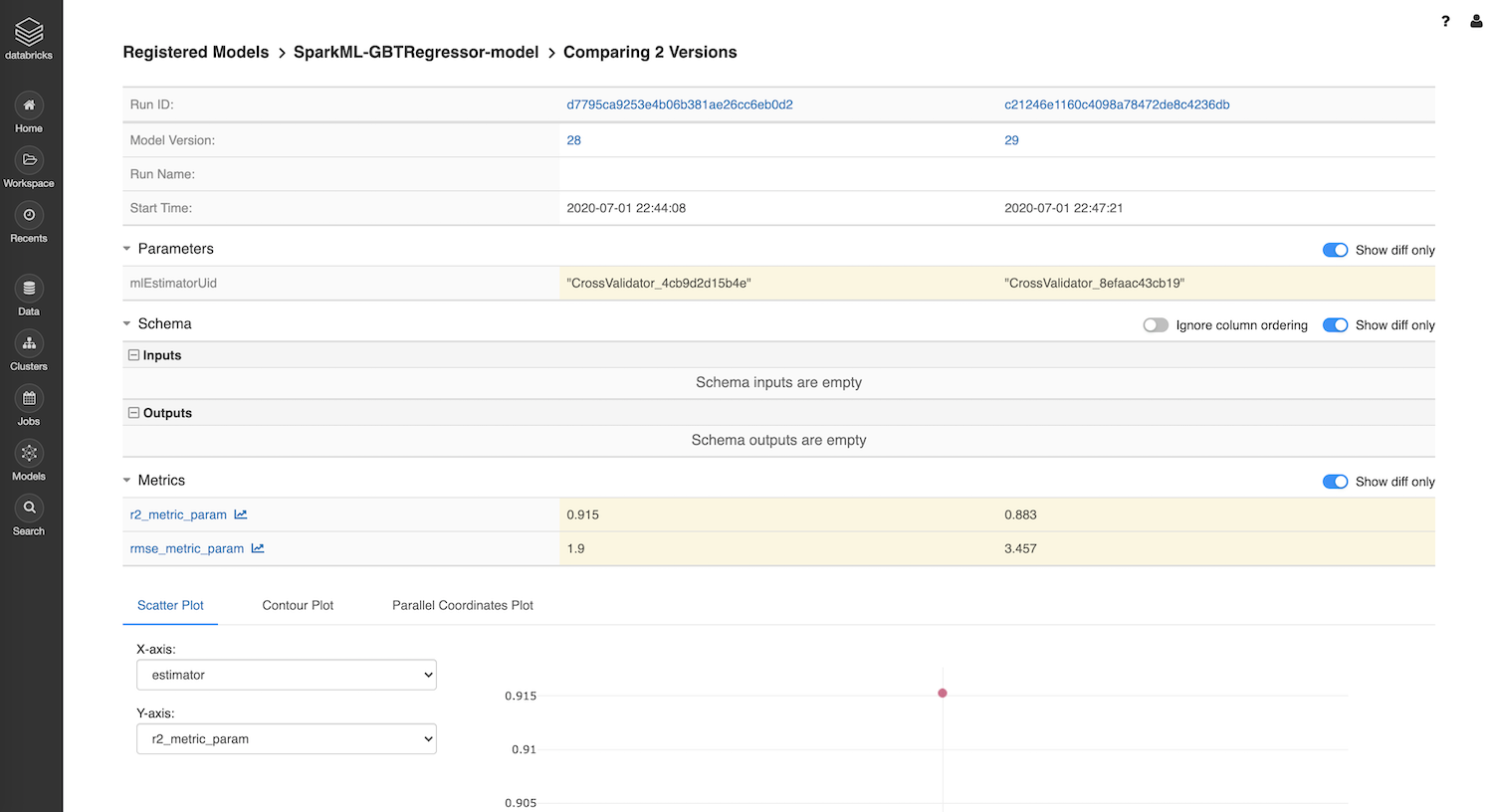
Model Comparison in MLflow On Databricks
Here’s a side-by-side comparison of two selected models created from the Transformer pipeline.
Model Retraining
Now, a very common requirement is to automate the process of retraining the model as and when more data becomes available–especially if the model hasn’t yet met the evaluation criteria. For example, accuracy can be one of the metrics on how a particular model is evaluated. This type of automation can be implemented by setting up an orchestrator pipeline as shown below.
The orchestrator pipeline is designed to continuously run and “wait” for training dataset files to be uploaded on Amazon S3. As soon as a training dataset is uploaded, this pipeline triggers/starts the model (re)training job described earlier.
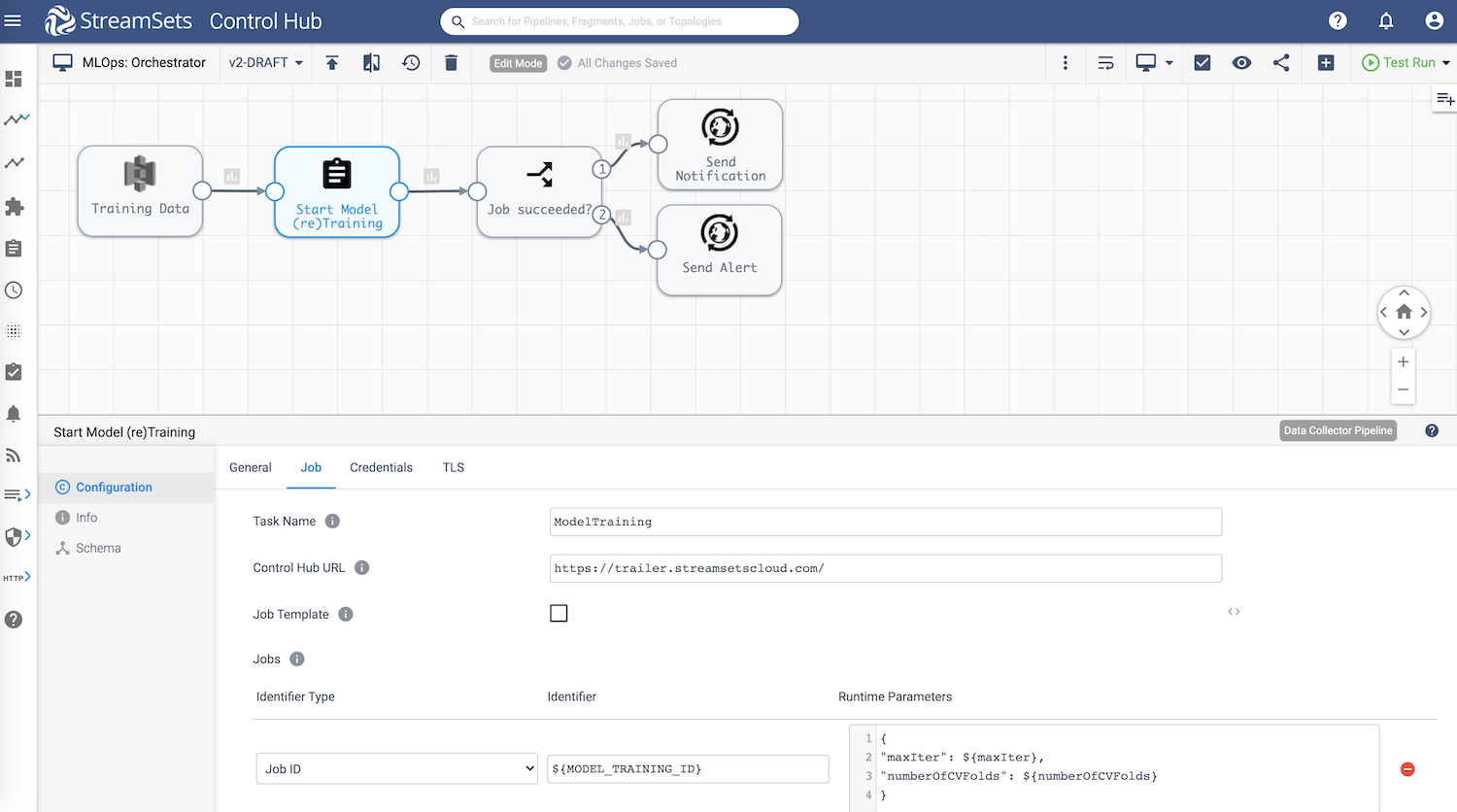
Also note that there are two hyperparameters maxIter and numberOfCVFolds passed in the pipeline so there’s no need to hard code them, and can be dynamically passed into the pipeline during model retraining and experimentation. The StreamSets DataOps Platform also provides ways to check the status of jobs that are currently running so that actions can be taken based on the status as shown above in the pipeline.
Sample Pipelines
If you’re interested in additional technical details and sample pipelines, please reach out to me: dash at streamsets dot com or @iamontheinet.
Get Started With Your Own Model Experiments
StreamSets DataOps Platform is not a machine learning platform, but it does provide important capabilities and extensibility that can help and expedite operations at some of the most crucial stages of the ML Lifecycle and MLOps. See this data pipeline demo at my Data + AI Summit session.
Learn more about StreamSets For Databricks available on AWS Marketplace and Microsoft Azure Marketplace.