Apache Kudu and Open Source StreamSets Data Collector Simplify Batch and Real-Time Processing
As originally posted on the Cloudera VISION Blog.
At StreamSets, we come across dataflow challenges for a variety of applications. Our product, StreamSets Data Collector is an open-source any-to-any dataflow system that ensures that all your data is safely delivered in the various systems of your choice. At its core is the ability to handle data drift that allows these dataflow pipelines to evolve with your changing data landscape without incurring redesign costs.
This position at the front of the data pipeline has given us visibility into various use cases, and we have found that many applications rely on patched-together architectures to achieve their objective. Not only does this make dataflow and ingestion difficult, it also puts the burden of reconciling different characteristics of various components onto the applications. With numerous boundary conditions and special cases to deal with, companies often find the complexity overwhelming, requiring a team of engineers to maintain and operate it.
In integrating our product, StreamSets Data Collector, alongside Apache Kudu, we’ve found users can reduce the overall complexity of their applications by orders of magnitude and make them more performant, manageable, predictable and expandable at a fraction of the cost.
Take the example of real-time personalization for social websites, a use case we have seen a few times. Previously, a typical implementation would use offline batch jobs to train the models, whereas the scores are calculated on real-time interactions. If the calculated scores do not reflect the most recent trends or viral effects, chances are the model training has become stale. A key question is “how do you ensure that the models are trained with latest information so that the calculated scores are up-to-the-minute?”
For the longest time, the choice of the underlying storage tier dictated what kind of analysis you could possibly do. For example, for large volume batch jobs such as training models on large datasets, the most effective storage layer is HDFS. However HDFS is not suited for aggregating trickle feed information due to various limitations, such as the inability to handle updates and requiring large files. As a result, applications often utilize multiple storage tiers and partition the data manually to route real-time streams into a system like Apache HBase and aggregated sets into HDFS. This is the reason why lambda architectures, among other architectural patterns, exist for Apache Hadoop applications.
In our example of real-time personalization, user interaction information is captured and sent to both an online and offline store. The online store, HBase in this case, is used for real-time scoring that creates personalization indices that are used by the web application to serve personalized content. The offline store, HDFS in this case, is used for training the models in a periodic batch manner. A minimum threshold of data is accumulated before it is sent to HDFS to be used by the batch training jobs. This introduces significant latency into the personalization process and introduces a host of problematic boundary conditions onto the application. For instance, since data is being captured from multiple web servers, the application must make sure it can handle any out-of-sequence or late-arriving data correctly.
All this sounds remarkably complex and hard to implement, which it is. But it does not need to be that way anymore. We’ve found that by integrating StreamSets Data Collector and Kudu, such applications can be greatly simplified and built more quickly than ever before. What’s more, operating and managing such applications is easier as well.
Kudu is an innovative new storage engine that is designed from the ground up to overcome the limitations of various storage systems available today in the Hadoop ecosystem. For the very first time, Kudu enables the use of the same storage engine for large scale batch jobs and complex data processing jobs that require fast random access and updates. As a result, applications that require both batch as well as real-time data processing capabilities can use Kudu for both types of workloads. With Kudu’s ability to handle atomic updates, you no longer need to worry about boundary conditions relating to late-arriving or out-of-sequence data. In fact, data with inconsistencies can be fixed in place in almost real time, without wasting time deleting or refreshing large datasets. Having one system of record that is capable of handling fast data for both analytics and real-time workloads greatly simplifies application design and implementation.
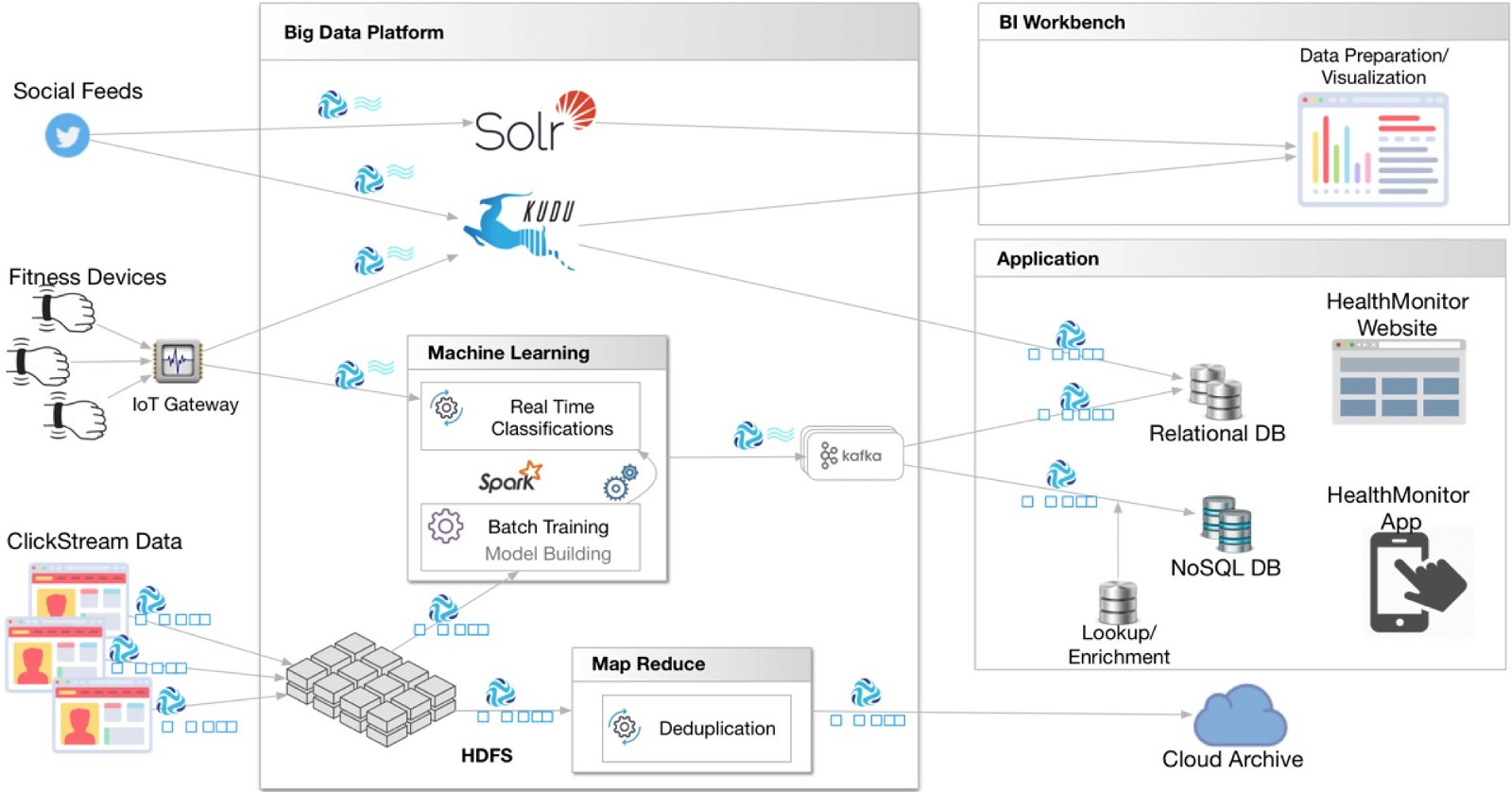
An example of a personalization dataflow topology using StreamSets Data Collector and Apache Kudu.
From the perspective of StreamSets, we’ve worked very hard to make the ingest layer simple and easy to use via a drag-and-drop UI. This means that when you introduce new data sources, change your data formats, modify the schema or structure of data, or upgrade your infrastructure to introduce new or updated components, your dataflows will continue to operate with minimal intervention. While this reduces the application complexity considerably on the ingestion side, the processing tier remains considerably complex when working with patched-together components. The introduction of Kudu reduces that complexity and allows users to build applications that can truly focus on business needs as opposed to handling complex boundary conditions.
Going back to our example of real-time personalization, the overall implementation can be greatly simplified by using StreamSets Data Collector based dataflows feeding into Kudu. The batch jobs that train the models can then directly run on top of Kudu as well as the real-time jobs that calculate the interaction scores. With StreamSets Data Collector depositing most recent interaction data into Kudu, the models will be trained with the latest information always and the real-time personalization will not need to suffer from artificial latency to buffer sufficient data for processing first.
For the first time in the Hadoop ecosystem, you now have the tools necessary to build applications that truly focus on business logic as opposed to doing a balancing act between different technology components that have significant impedance mismatch. No longer do you need to worry about capturing data from numerous sources, or feeding different systems of record to harness their native capabilities that are required for your applications’ processing logic. Consequently, you no longer need to reconcile the differences between such systems that create numerous boundary conditions and special case scenarios.