![]() In times of yo-yo-ing markets, rapid change, and economic recession, real time analytics—and the streaming data that makes it possible—can make the difference between barely hanging on and thriving.
In times of yo-yo-ing markets, rapid change, and economic recession, real time analytics—and the streaming data that makes it possible—can make the difference between barely hanging on and thriving.
2020 has been a tough year, with a global pandemic, a highly contentious US election, and a major recession in the mix. After 100,000+ business closures, hundreds of thousands of job losses, and over 7 months of sheltering in place / social distancing, the market continues its wild ups and downs.
In many regions in the US, workers will be remote until the middle of 2021 or later. Meanwhile, essential workers and those returning to work must pass rigorous health checks every day. Yikes! The last 5-10 years may have been dynamic, but we can all agree that 2020 came along with a ‘hold my beer’ attitude and blew away all previous frames of reference.
Data and Decision-making in Unprecedented Times
The impact of the pandemic alone has been unprecedented, and most companies have been forced to make dramatic changes. As Judy Ko, Chief Product Officer at StreamSets, explored in her series on adjusting your data practice for the pandemic, making data-driven decisions fast is a critical component of success (or failure), in these times.
Organizations that make changes and decisions relying on real time analytics in this type of rapidly changing environment have a distinct advantage over those relying on historical data. In fact, the Compliance, Governance and Oversight Counsel reported waaaaay back in 2018 that 60% of corporate data has “no business, legal or regulatory value.” Why? Essentially, too much data and no good way to make sense of and act on it.
Since it’s a widely known fact that the amount of data produced increases exponentially every day, hour, second, we can extrapolate that there’s a LOT more useless corporate data today than there was just two years ago. In addition, an estimated 80% of that data collected by enterprises is now unstructured and semi-structured, adding an extra layer of complexity. It’s probably not a surprise then that a 2020 Big Data and AI Executive Survey found that business adoption of Big Data continues to be a struggle, with close to 75% of firms citing this as an ongoing challenge.
Challenges Data Engineers Face Today
Though there are always organizational reasons to consider, much of the reason business can’t tap into the power of real time data for decision making is a lack of the right data and analytics architecture. This is due to three major challenges facing data engineers today as they’re building the platforms that drive analytics.
- Everybody wants data quickly, but it takes too long to build and debug pipelines. The demand for analytics, data science, and machine learning is accelerating. Most tools are either too complex, requiring specialized coding expertise, or way too simple to run non-stop pipelines. As a result, project backlogs pile up.
- 80% of time spent on maintaining and fixing pipelines due to data drift. Maintenance of hand coded data pipelines is tedious. Brittle code or mappings require major rework or break unexpectedly whenever things change, delaying downstream processes.
- Adoption of the latest, greatest data technologies is too slow. The rate technology changes and modernizes is non-stop. In fact, according to Gartner, 75% of all databases will be on a cloud platform by 2023*. Changing data platforms requires fundamentally rewriting data pipelines, slowing new technology adoption.
These challenges are daunting but they can all be overcome.
How Smart Data Pipelines and Powerful Cloud Services Fuel Real-time Analytics
Going back to that 60% valueless data—most data loses value over time if not contextualized with real-time data, and some data value goes to zero value almost immediately (for example, fraud monitoring and mitigation for your bank account or credit card).
When paired with the challenges data engineers face today, making use of data for all but the most critical use cases for business decision making can seem like an insurmountable feat. It’s not. The way to shift the balance from unusable to valuable data is to make the data available to real time analytics systems with the lowest possible latency and scalable capacity—streaming data pipelines to ingest data into cloud data warehouses.
Streaming Data Architecture
Data streaming technology, like StreamSets smart data pipelines for AWS, enables customers to ingest, process, and analyze high volumes of high-velocity data from a variety of sources in real time.
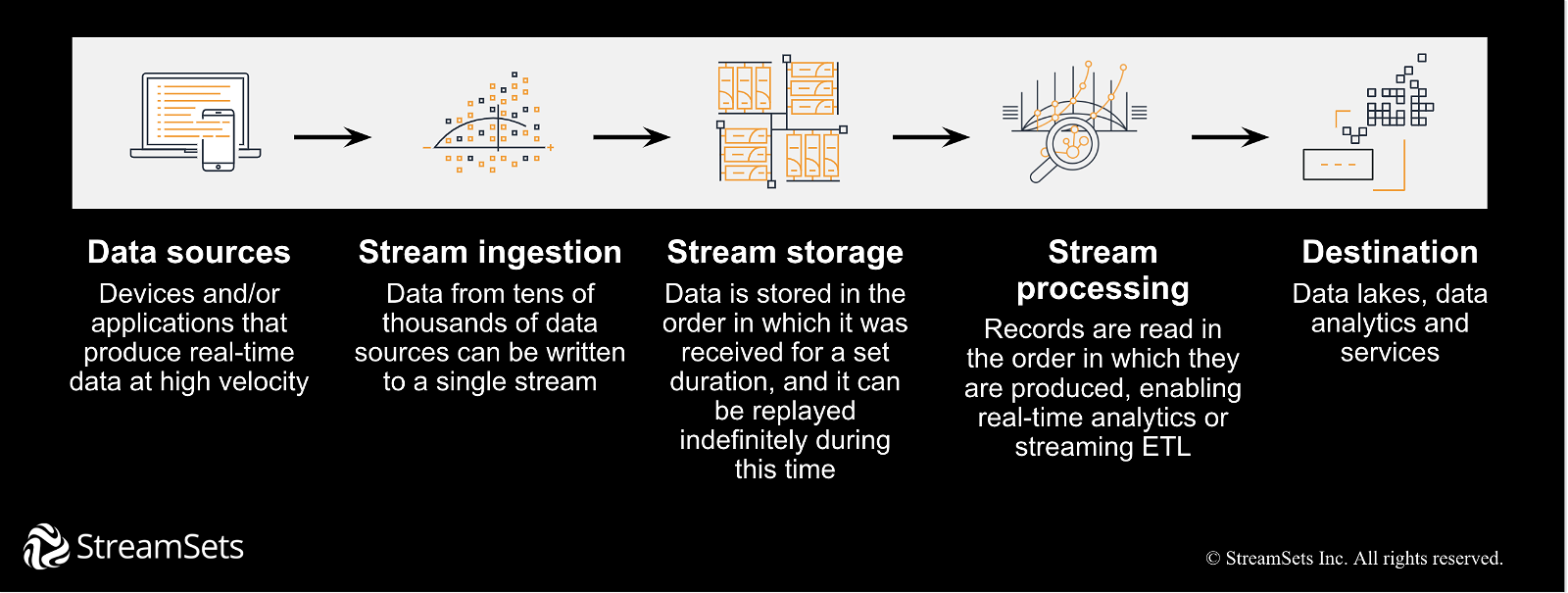 Raw data generated from all of the data sources is ingested into a single stream—a software library or SDK or agent—which reliably takes that data and pushes it to a streaming storage system. That storage system will capture the data, durably store it over time, and allow multiple applications to simultaneously and independently consume the data. Streamed data is stored in the order it was received, and is able be played back in the same order, which enables real-time analytics or streaming ETL. It also provides an advantage for decoupling your applications and using the data pipelines to consume the data in any way you want to. Once your data is processed, it typically lands in a destination data lake, data warehouse, No SQL store, or Elasticsearch database, which connects to your visual BI/analytics tool.
Raw data generated from all of the data sources is ingested into a single stream—a software library or SDK or agent—which reliably takes that data and pushes it to a streaming storage system. That storage system will capture the data, durably store it over time, and allow multiple applications to simultaneously and independently consume the data. Streamed data is stored in the order it was received, and is able be played back in the same order, which enables real-time analytics or streaming ETL. It also provides an advantage for decoupling your applications and using the data pipelines to consume the data in any way you want to. Once your data is processed, it typically lands in a destination data lake, data warehouse, No SQL store, or Elasticsearch database, which connects to your visual BI/analytics tool.
Moving Data to and on AWS with Smart Data Pipelines
AWS provides the building blocks for developers to create a secure, flexible, cost-effective real time analytics solution in the cloud. When it comes to extracting data for analysis, a different type of tool is required for a different user: the data engineer.
StreamSets is uniquely positioned to provide one easy-to-use tool for data engineers to build and manage smart data pipelines that conquer the challenges they face. Smart data pipelines pull together any source of data, any type of pipeline, and are easily portable to every destination, from cloud to on-premises.
The StreamSets DataOps Platform empowers your whole team, from highly skilled data engineers to visual ETL developers, to do powerful data engineering work on the AWS stack. Only StreamSets makes it easy for any data professional to get started quickly with data pipelines, while providing power features that make it easy to extend for sophisticated enterprise needs.
StreamSets’ smart data pipelines are unique in addressing the full data engineering ecosystem so:
- 1 data engineer enables 10s of ETL developers to serve 100s of analysts.
- 80% of the time spent on break-fix and maintenance is ELIMINATED by being resilient to data drift, and letting your team port pipelines to new data platforms without rewrites.
- Data is continuously delivered via DataOps, despite constant data drift.
By using StreamSets smart data pipelines for AWS, you can simplify adoption of the AWS architecture with agility, easy design, and 100s of pre-built connections to AWS services. StreamSets also operationalizes and enables continuous data delivery by addressing the entire design-deploy-operate lifecycle of data pipelines moving data on AWS and between AWS services.
StreamSets is proud to be an AWS Advanced Technology Partner. That means StreamSets stays up to date with the latest developments in the AWS cloud and provides native integration with AWS Linux 2, Redshift, Kinesis, S3, and EMR.
Real Time Analytics for Better Decision Making & Outcomes
While standard batch processing and analysis may have worked prior to 2020, the world has changed. The pandemic and resulting rapid market and business changes have shifted digital transformation into high gear for most companies. Demand for services spikes or vanishes, often overnight, then does the opposite hours or days later. The pandemic dies down in one area only to spike in another. And almost everyone is online, almost all of the time. Business may have been fast before, but now it’s super-warp speed, with no end in sight.
Data engineers need to get new data pipelines up and running fast and extend them to their teams just as quickly. It’s imperative they know exactly what’s going on, in all of their data pipelines, all of the time, in a scalable way. Pipelines need to be abstracted and decoupled to handle the majority of structure and implementation changes (90% with StreamSets) with minimal to no effort. And redeploying to a new platform has to be as simple as a destination update, not a full rewrite.
Once data engineers have this type of freedom, data analysts and business users will be able to reliably get the information they need to keep up with 2020 decision making and beyond.
*“Cloud Data Warehouse: Are You Shifting Your Problems to the Cloud or Solving Them?” Robert Thanaraj, 7 April 2020.
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally, and is used herein with permission. All rights reserved.