 Jowanza Joseph is a principal software engineer at One Click Retail with long experience of building reliable and performant distributed data systems. Recently, Jowanza built a pair of data pipelines with StreamSets Data Collector to read data from Ford GoBike and send it to MapD via Kafka. It’s a great example of Data Collector’s versatility in dealing with web services. We’re reposting this entry from Jowanza’s original blog with his kind permission.
Jowanza Joseph is a principal software engineer at One Click Retail with long experience of building reliable and performant distributed data systems. Recently, Jowanza built a pair of data pipelines with StreamSets Data Collector to read data from Ford GoBike and send it to MapD via Kafka. It’s a great example of Data Collector’s versatility in dealing with web services. We’re reposting this entry from Jowanza’s original blog with his kind permission.
In this post, we will use the Ford GoBike Real-Time System, StreamSets Data Collector, Apache Kafka and MapD to create a real-time data pipeline of bike availability in the Ford GoBike bike share ecosystem. We’ll walk through the architecture and configuration that enables this data pipeline and share a simple auto-updating dashboard within MapD Immerse.
High-Level Architecture
The high-level architecture consists of two data pipelines; one pipeline polls the GoBike system and publishes that data to Kafka. The other pipeline consumes from Kafka using Data Collector, transforms the data, then writes the data to MapD:
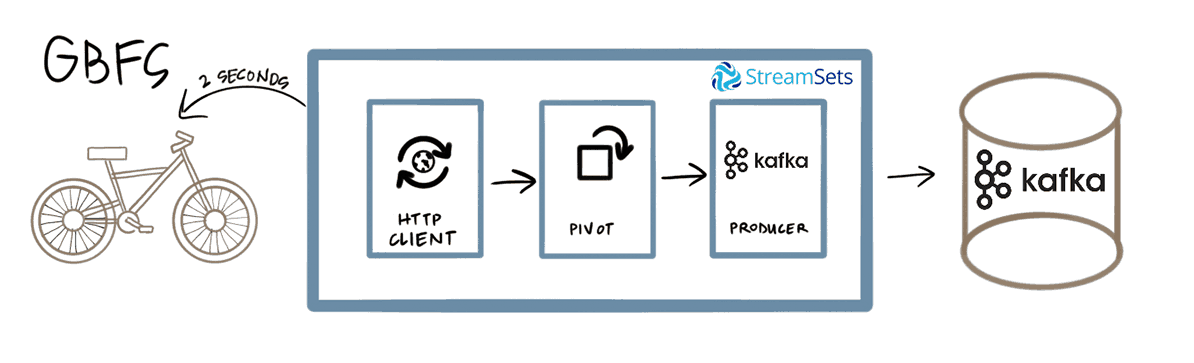
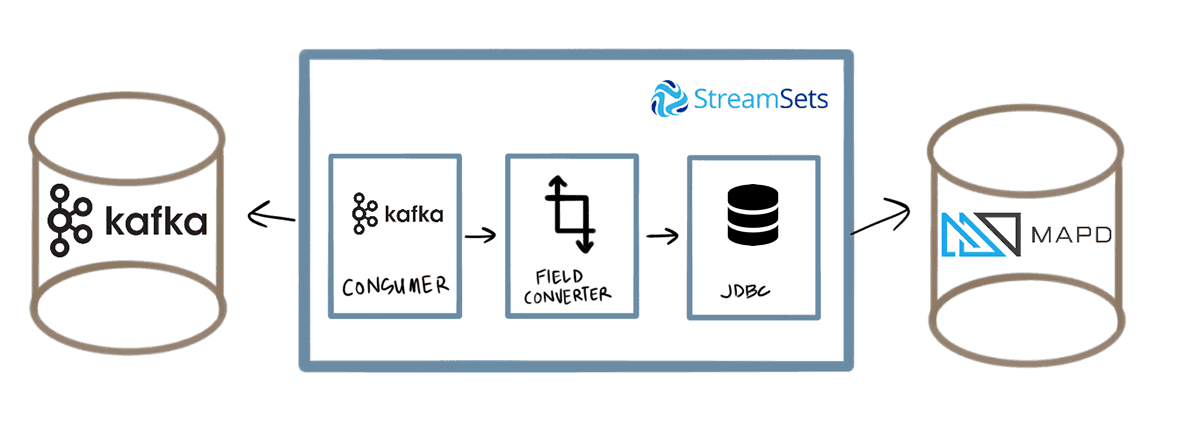
In the remainder of this post, I’ll outline each of the components of the pipelines and their configurations.
GBFS
GBFS is a data feed specification for bike share programs. It provides several JSON schemas so that the same data from every bike share can be open to app developers to incorporate into their systems or for researchers. The Ford GoBike system uses GBFS so I refer to data from Ford as GBFS for simplicity for the remainder of this article.
From GBFS, there are several feeds available and the details about each can be found here. For our use case, we’re interested in each station’s status and also each station’s locations for future visualization. For a sample of the feeds, you can check out the documentation.
For this project, we’ll poll the GBFS for the station status. Station locations change infrequently, so a daily or weekly cron pull of the station locations should be sufficient to ensure our tables have the most correct information.
StreamSets Data Collector
The majority of the heavy lifting for this system is managed using Data Collector. If you’re unfamiliar with StreamSets, their website and documentation is top notch. At a high level, Data Collector is a plug-and-play stream-processing framework. I like to think of it as Spark Streaming with a UI on top of it. It provides a drag-and-drop interface for the source-processor-sink streaming model.
HTTP Client
To poll GBFS, I created an HTTP Client origin in Data Collector with the following configuration:
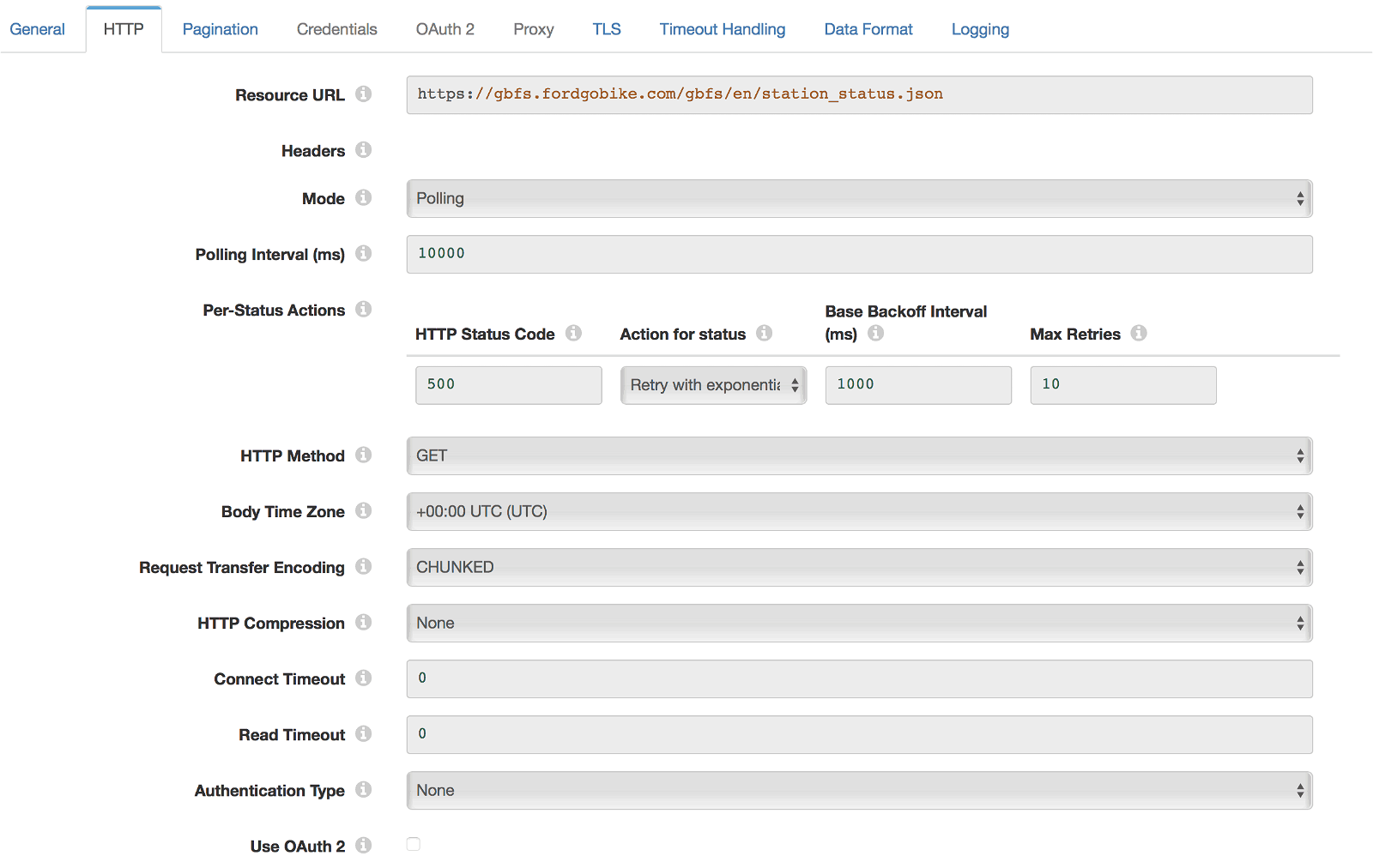
Each GET request will return all stations for Ford GoBike and a status as outlined in the GBFS specification. The more desirable state would if every station_id JSON object were its own message. Fortunately, Data Collector has a pivot processor which will take a JSON Array like this:

and flatten it so that each object is its own message:
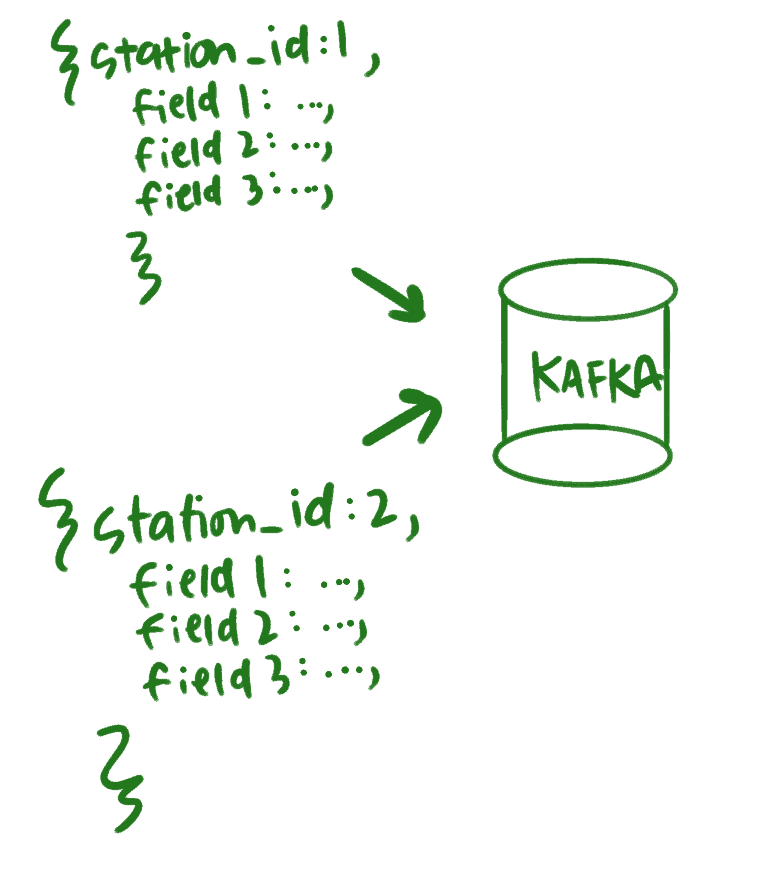
The configuration looks like this:
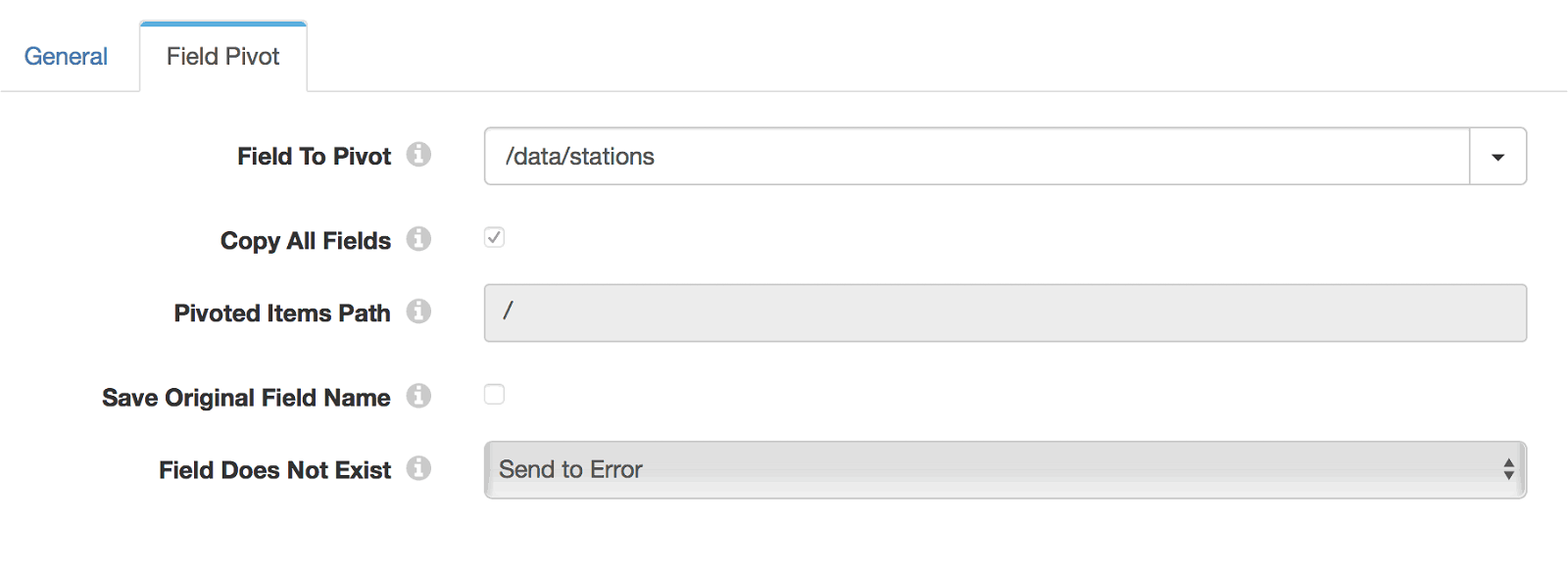
Kafka Producer
With the data polled from the GBFS API and flattened, it’s time to write it to Kafka. Connecting to Kafka with Data Collector is quite simple. Data Collector’s Kafka stage library has all the facilities for producing and consuming Kafka messages. You’ll need to install it if it’s not present in your Data Collector installation.
If you have a distributed deployment of Kafka (which you should for production), you have to ensure all of the Kafka node URIs are present in the Kafka Producer configuration:
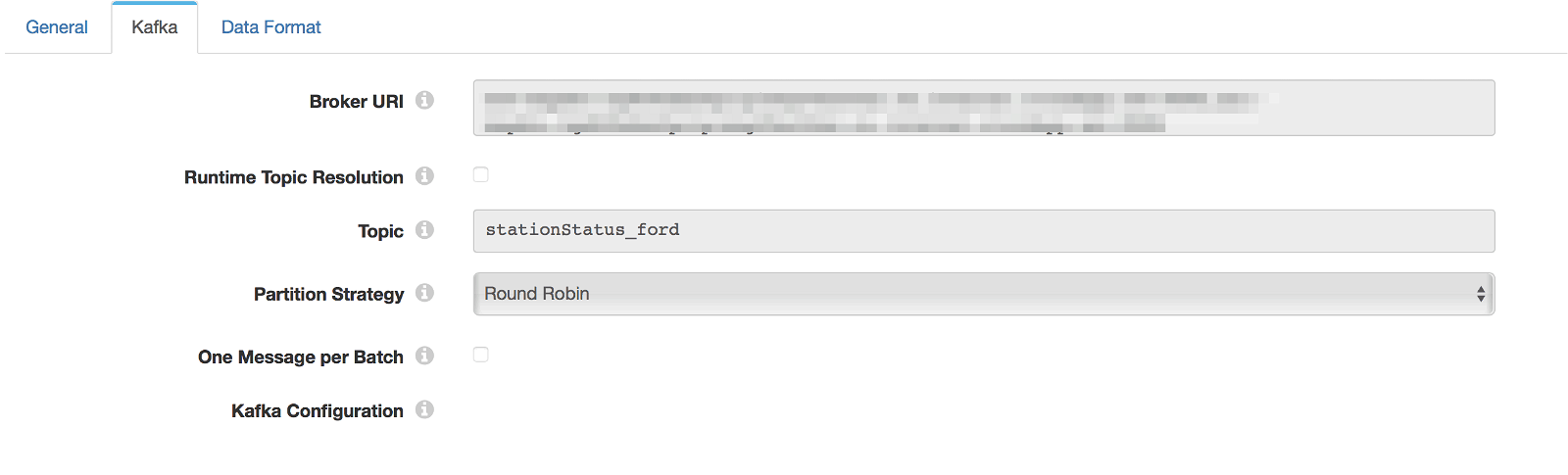
Kafka Consumer
With a working producing pipeline we’re publishing about 500 messages every 2 seconds to Kafka. We’d like to consume that data and write it to MapD. Data Collector’s Kafka Consumer is easy to configure:
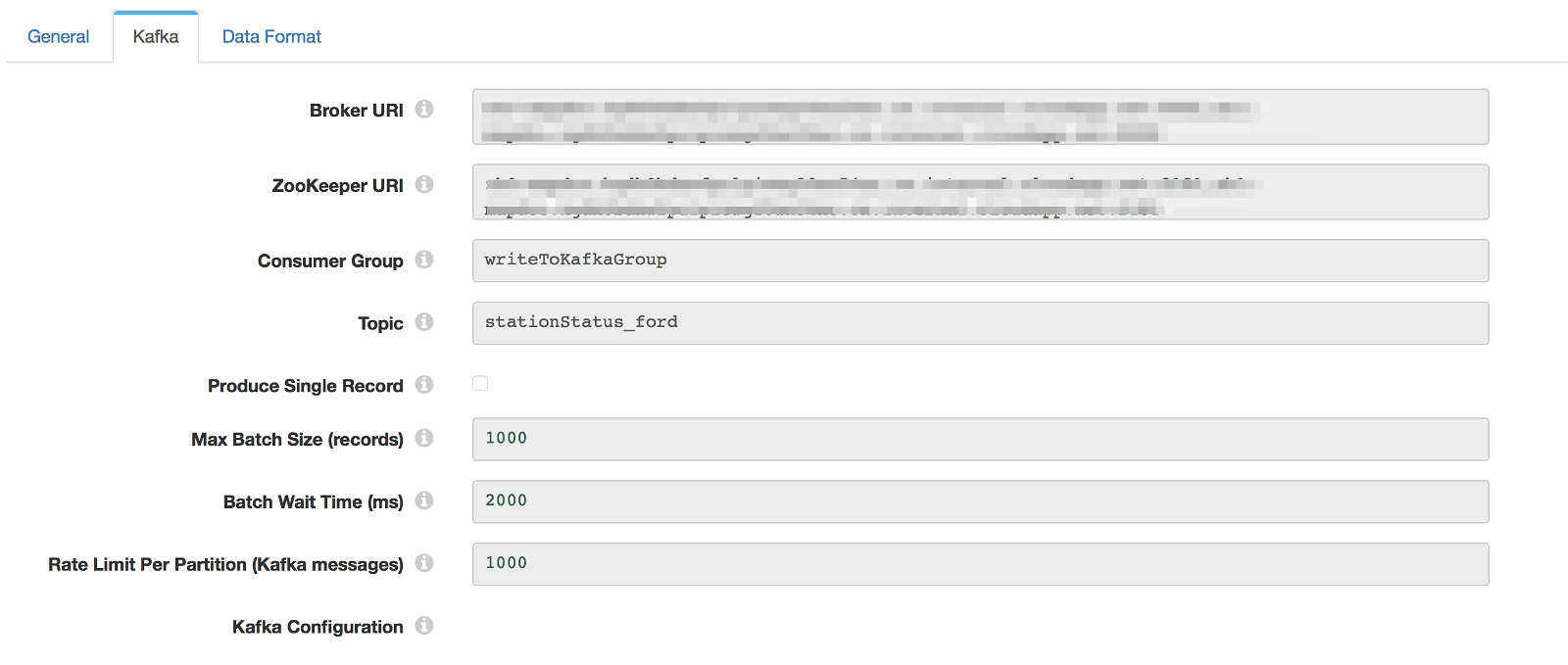
For the consumer, you need both the Broker URIs and the Zookeeper URIs. On initial testing, I ran into failures downstream when using the JDBC Producer destination. With the JSON payload, some of the fields are strings that I outlined as Integers in my MapD table schema.
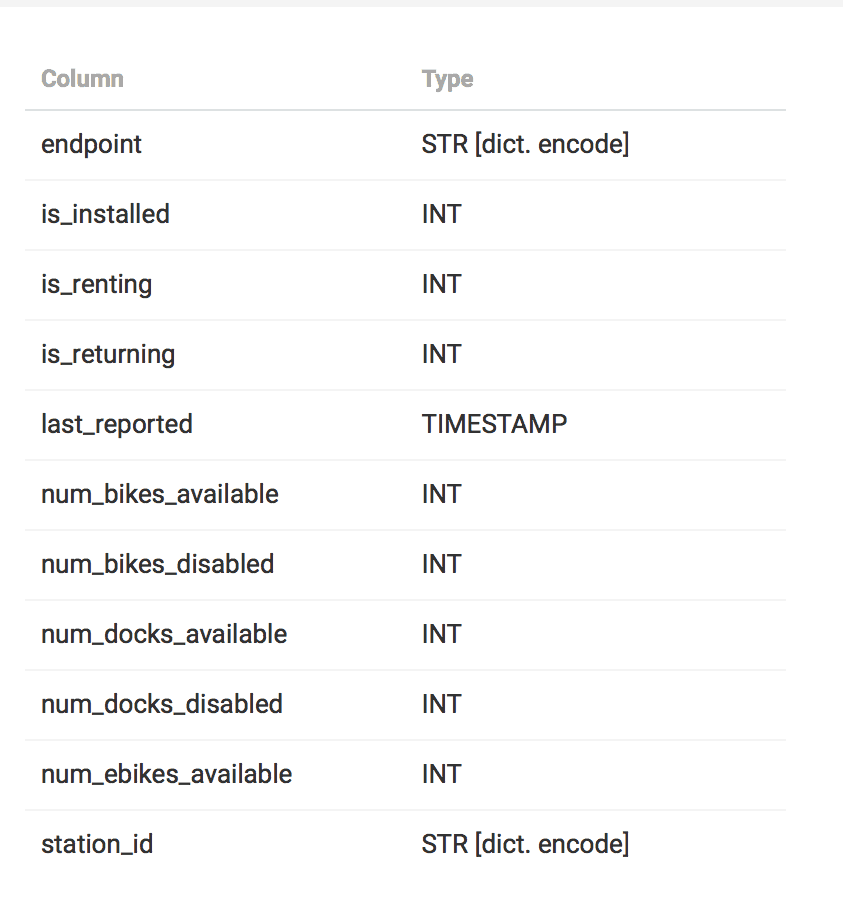
Using Data Collector’s Field Converter processor I isolated these fields and converted them to the appropriate data type.
MapD via JDBC
Now that the rest of the pipeline is ready, we need to sink to our final destination, the MapD database.
Step 1 is getting the JDBC driver for MapD installed on Data Collector. You can download the latest driver here, and install it via the Package Manager External Libraries page:
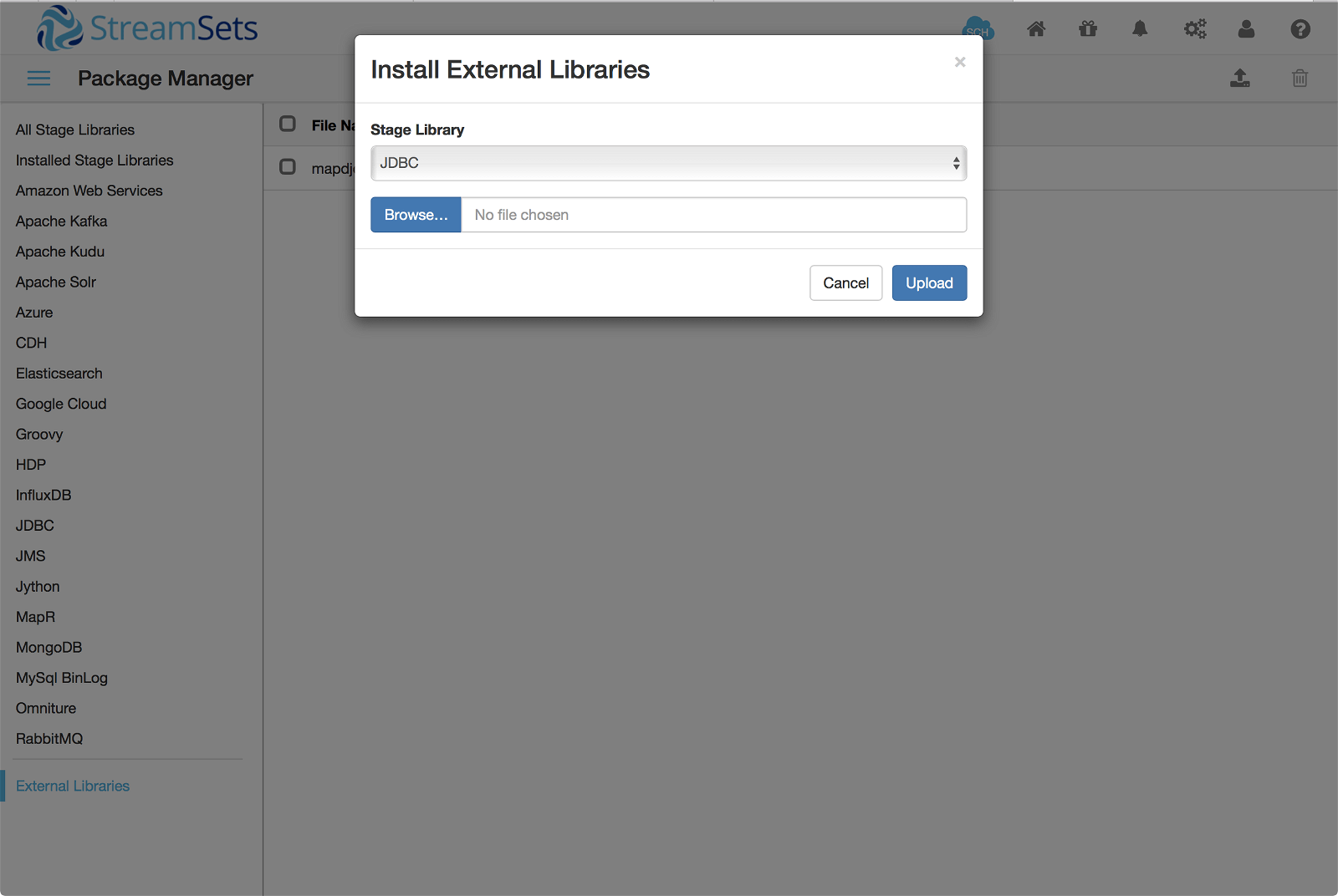
Step 2 is to configure the JDBC connection in Data Collector. Connecting to MapD via JDBC is outlined in their documentation. I used the following JSON configuration to set up each field in the MapD table and how they made up the JSON payload coming from Kafka:
[
{
"paramValue": "?",
"dataType": "STRING",
"columnName": "endpoint",
"field": "/endpoint",
"defaultValue": ""
},
{
"paramValue": "?",
"dataType": "INTEGER",
"columnName": "is_installed",
"field": "/is_installed",
"defaultValue": "NULL"
},
{
"paramValue": "?",
"dataType": "INTEGER",
"columnName": "is_renting",
"field": "/is_renting",
"defaultValue": "NULL"
},
{
"paramValue": "?",
"dataType": "INTEGER",
"columnName": "is_returning",
"field": "/is_returning",
"defaultValue": "NULL"
},
{
"paramValue": "?",
"dataType": "DATETIME",
"columnName": "last_reported",
"field": "/last_reported",
"defaultValue": "NULL"
},
{
"paramValue": "?",
"dataType": "INTEGER",
"columnName": "num_bikes_available",
"field": "/num_bikes_available",
"defaultValue": "NULL"
},
{
"paramValue": "?",
"dataType": "INTEGER",
"columnName": "num_bikes_disabled",
"field": "/num_bikes_disabled",
"defaultValue": "NULL"
},
{
"paramValue": "?",
"dataType": "INTEGER",
"columnName": "num_docks_available",
"field": "/num_docks_available",
"defaultValue": "NULL"
},
{
"paramValue": "?",
"dataType": "INTEGER",
"columnName": "num_docks_disabled",
"field": "/num_docks_disabled",
"defaultValue": "NULL"
},
{
"paramValue": "?",
"dataType": "INTEGER",
"columnName": "num_ebikes_available",
"field": "/num_ebikes_available",
"defaultValue": "NULL"
},
{
"paramValue": "?",
"dataType": "STRING",
"columnName": "station_id",
"field": "/station_id",
"defaultValue": ""
}
]
With these configurations, our data pipeline is complete.
Conclusion & Dashboard
With the 10-second polling interval on GBFS and splitting each GBFS record, we can write ~1000 m/s to MapD. We could poll more often to increase the throughput, but this should be adequate for our needs. Using MapD Immerse, we can provide a real-time dashboard to monitor our record counts in real-time. Watch the record count closely – you should see it change every 10 seconds or so.
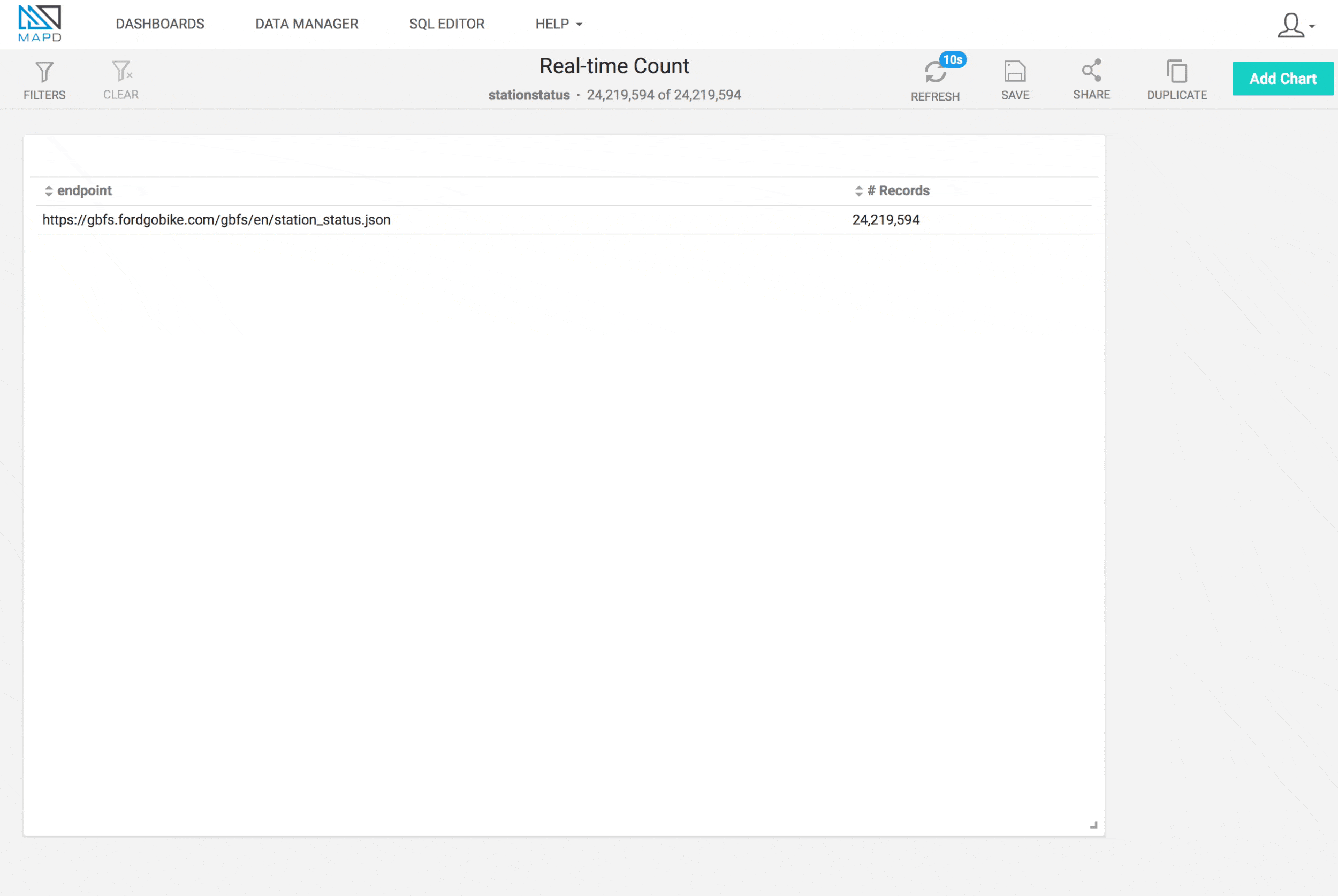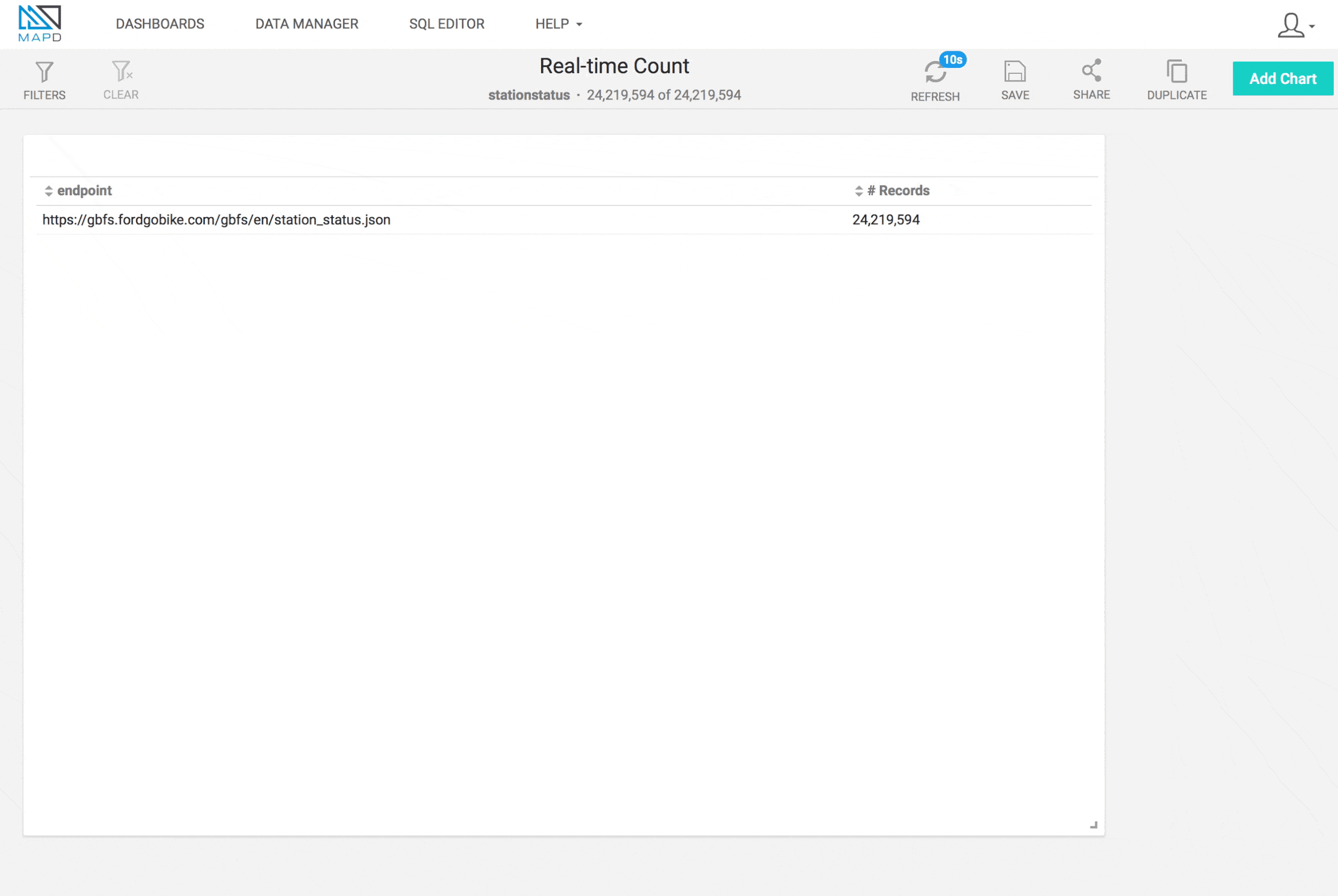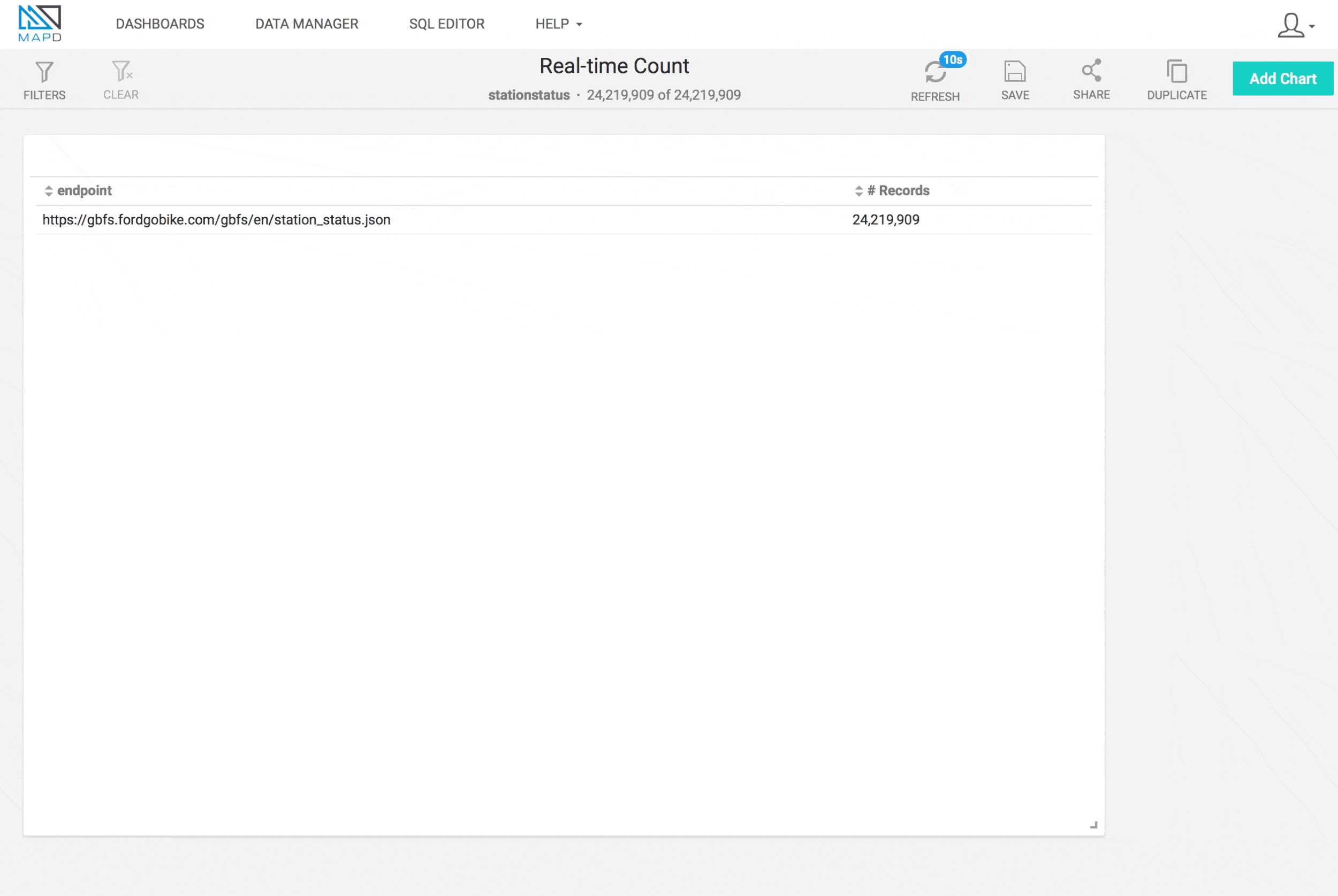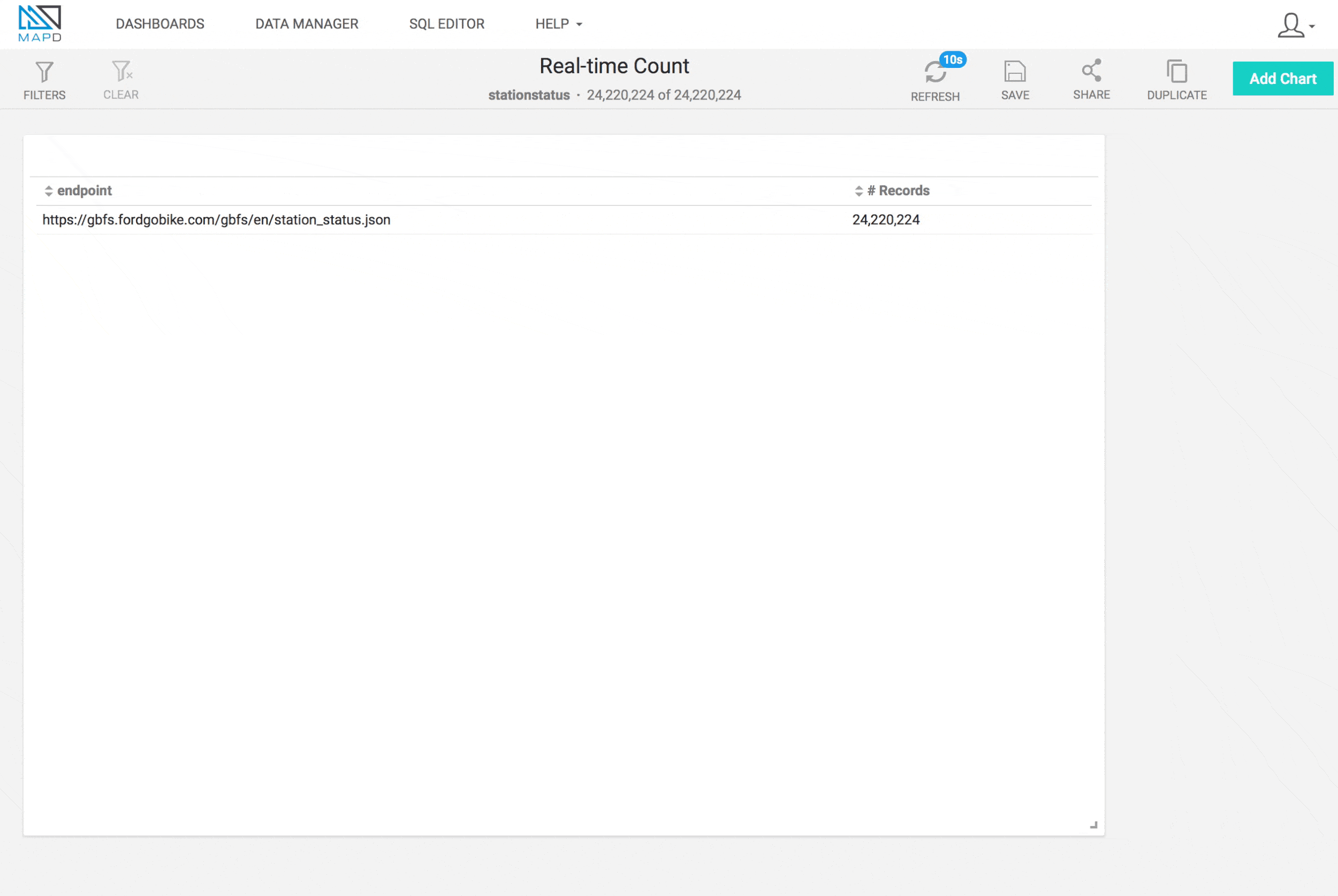
In a future post, we’ll use this same system to write more feeds that follow the GBFS to test the scalability of streaming lots of data into MapD.
Notes
Thanks to Randy Zwitch for editing previous drafts of this post and his contributions to building the pipeline and provisioning the virtual machines.