![]() In this blog post, I will present a step-by-step guide on how to scale Data Collector instances on Azure Kubernetes Service (AKS) using provisioning agents—which help automate upgrading and scaling resources on-demand, without having to stop execution of pipeline jobs. AKS removes the complexity of implementing, installing, and maintaining Kubernetes in Azure and you only pay for the resources you consume.
In this blog post, I will present a step-by-step guide on how to scale Data Collector instances on Azure Kubernetes Service (AKS) using provisioning agents—which help automate upgrading and scaling resources on-demand, without having to stop execution of pipeline jobs. AKS removes the complexity of implementing, installing, and maintaining Kubernetes in Azure and you only pay for the resources you consume.
Provisioning Agent
Provisioning agents are containerized applications that run within a container orchestration framework, such as Kubernetes. In our case, the StreamSets Control Agent runs as a Kubernetes deployment and it automatically provisions Data Collector containers in a given Kubernetes cluster.
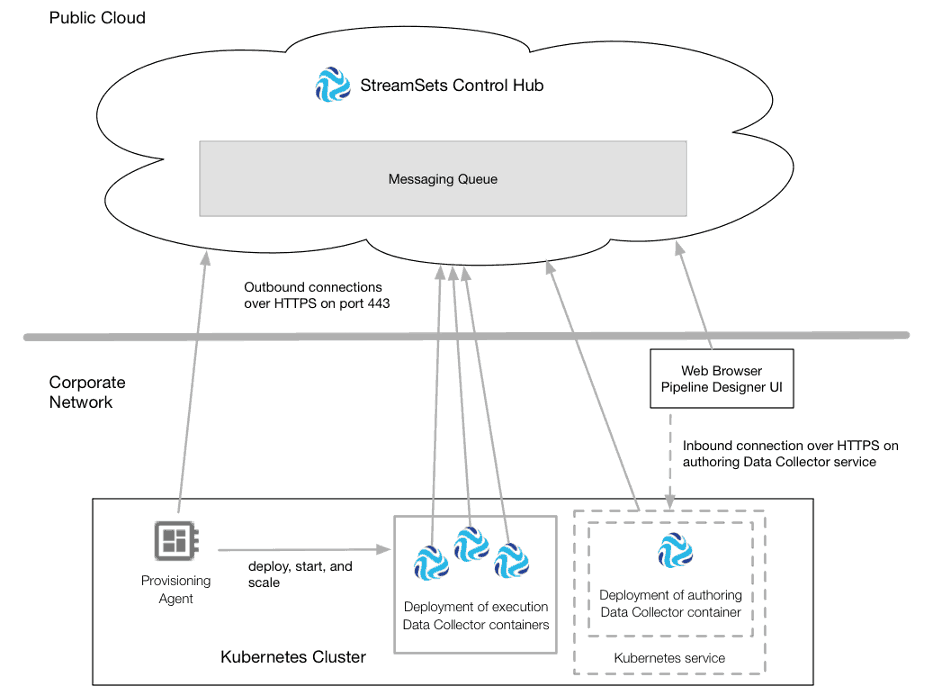
For more details, click here.
Prerequisites
In order to follow along, you’ll need the following prerequisites.
- Access to StreamSets Control Hub (SCH)
- With Auth Token Administrator and Provisioning Operator roles
- If you don’t have access to SCH, sign up for 30-day free trial
- Azure Kubernetes Service
- Access to existing Kubernetes cluster or privileges to create one
- Azure CLI
- kubectl
Ok, let’s get started!
STEP 1. Prepare Control Agent Deployment
Download a copy of the deployment template found here—https://github.com/iamontheinet/StreamSets/blob/master/Kubernetes/Azure-AKS/control-agent.yaml—and optionally update lines 4 and 41 with your desired name. For example, I set it to ‘dash-aks-agent‘.
STEP 2. Prepare Control Agent Deployment Script
Downlaod a copy of the script template found here—https://github.com/iamontheinet/StreamSets/blob/master/Kubernetes/Azure-AKS/deploy-control-agent-on-aks-template.sh—and update the following variables:
* SCH_URL = YOUR CONTROL HUB URL
* SCH_ORG = YOUR CONTROL HUB ORG
* SCH_USER = YOUR CONTROL HUB USER
* SCH_PASSWORD = YOUR CONTROL HUB PASSWORD
* CLUSTER_NAME = YOUR AZURE CLUSTER NAME
* RESOURCE_GROUP = YOUR AZURE CLUSTER RESOURCE GROUP
Things to note about the above script:
- It expects the file control-agent.yaml referenced in step 1 to be present in the local directory
- It requires utilities such as jq and perl so you may need to install those
- If you’re using unsigned SSL certificate for your SCH installation, you may need to add -k parameter to the `curl` command
STEP 3. Deploy Control Agent
To deploy the control agent, run the script referenced in step 2 as follow.
$ chmod +x deploy-control-agent-on-aks-template.sh $ ./deploy-control-agent-on-aks-template.sh
This script might take a few minutes to run and if all goes well, you’ll see output similar to:
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 203 100 203 0 0 966 0 --:--:-- --:--:-- --:--:-- 962
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 405 100 405 0 0 757 0 --:--:-- --:--:-- --:--:-- 758
DPM Agent "0D5DC09F-B9E3-467D-A39E-DC56644BE727" successfully registered with SCH
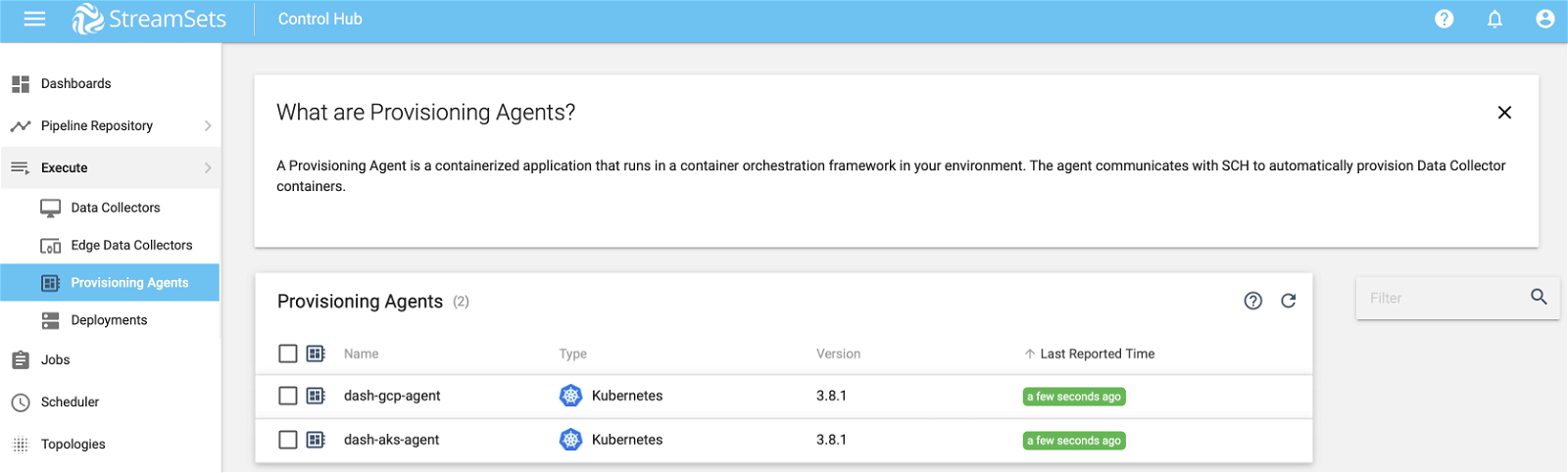
STEP 4. Control Agent In SCH
The control agent created in step 3 should now show up in SCH as shown below.
You may also use `kubectl` to confirm that the control agent was deployed successfully.
$ kubectl get deployments NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE dash-aks-agent 1 1 1 1 14m
$ kubectl get pods NAME READY STATUS RESTARTS AGE dash-aks-agent-6cf96997b7-6hhwn 1/1 Running 0 15m
STEP 5. Data Collector Containers In SCH
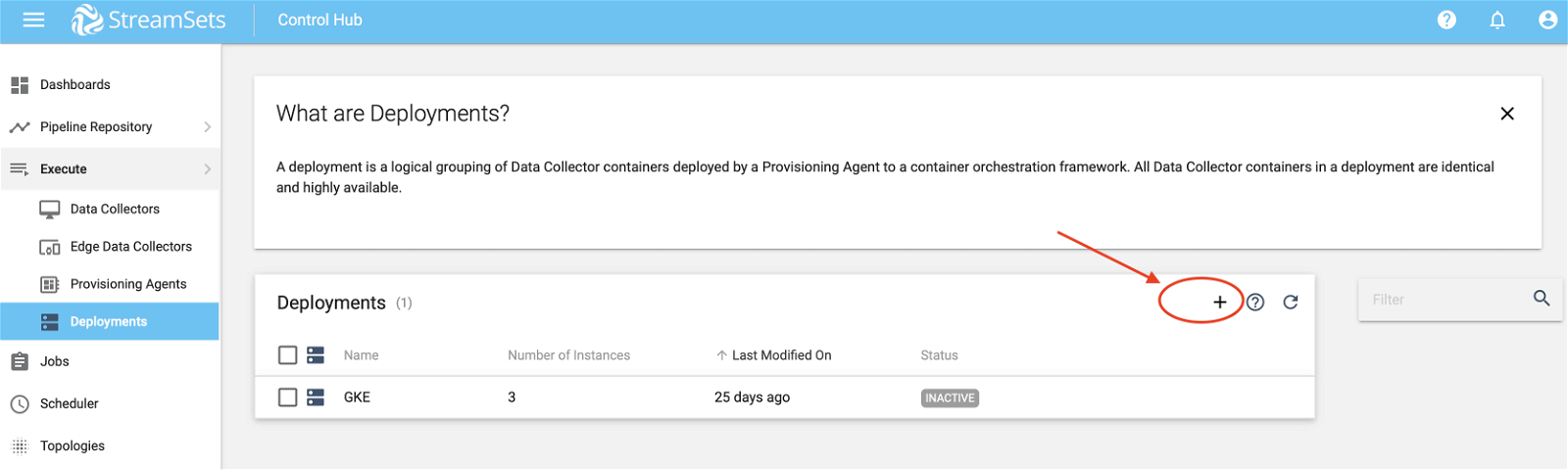
Now let’s look at how to create a logical grouping of Data Collector containers that can be deployed by our provisioning agent created in step 3.
Select Deployments on the left sidebar menu and then click on + as show below.
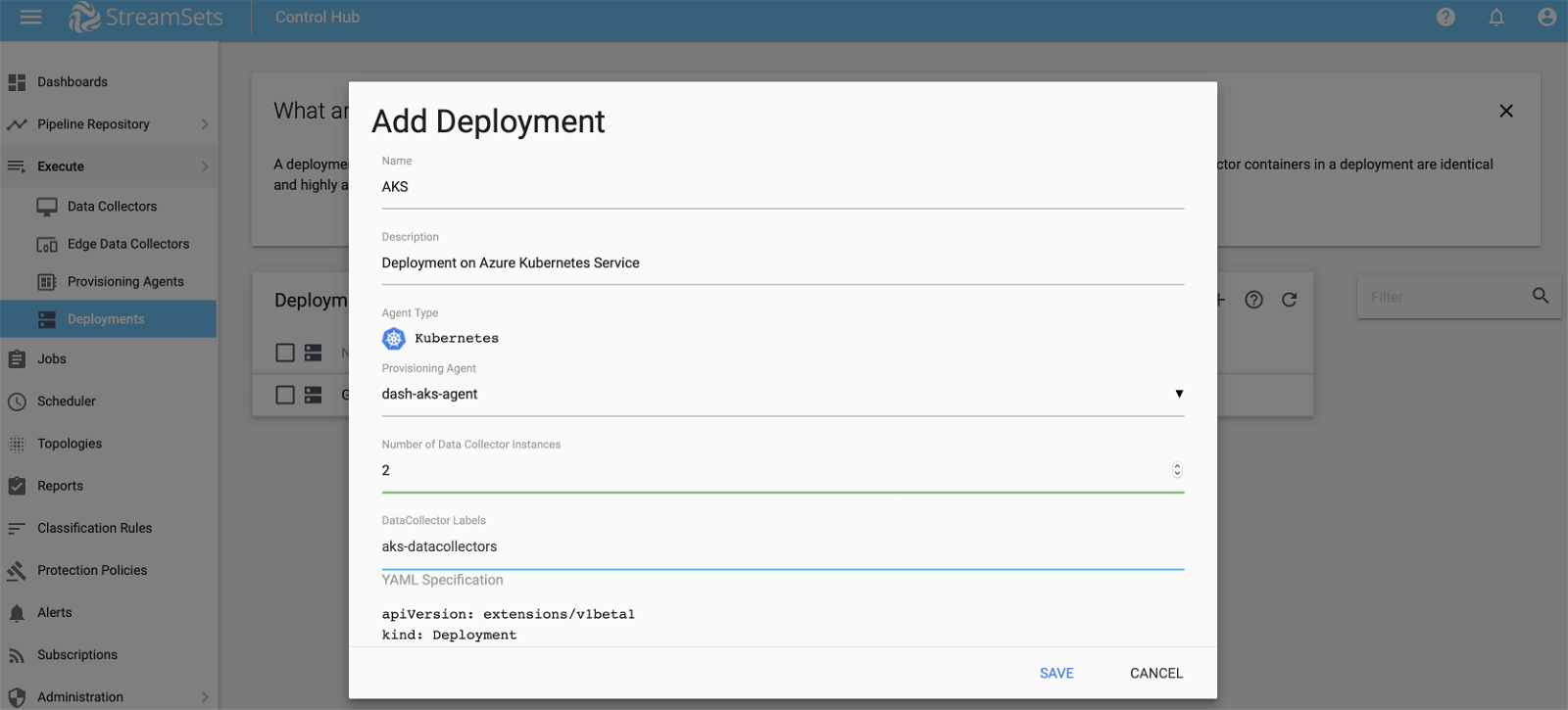
- Fill in Name and Description
- For Provisioning Agent select the one created in step 3
- For Number of Data Collector Instances we’ll start with 2 and then we’ll see how we can add more while the job is running
- For DataCollector Labels enter ‘aks-datacollectors‘—more on this later
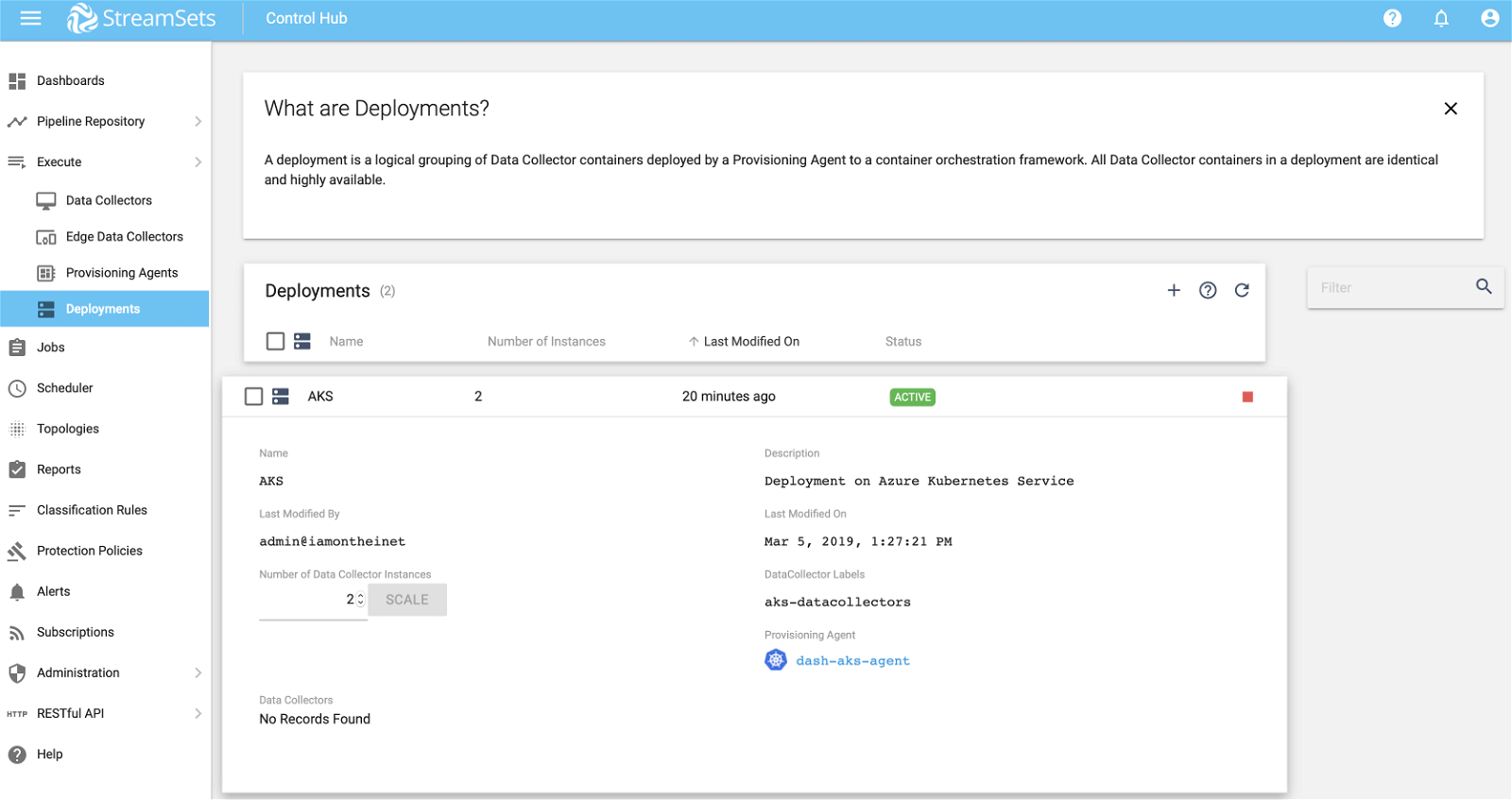
STEP 6. Activate Deployment In SCH
To activate the deployment created in step 5, click on Play button as show below.

This may take a couple of mins and then you should see the status change to Active.
This also means that 2 Data Collector instances would have been created and made available for running pipeline jobs. You can verify this by selecting Execute >> Data Collectors as shown below.
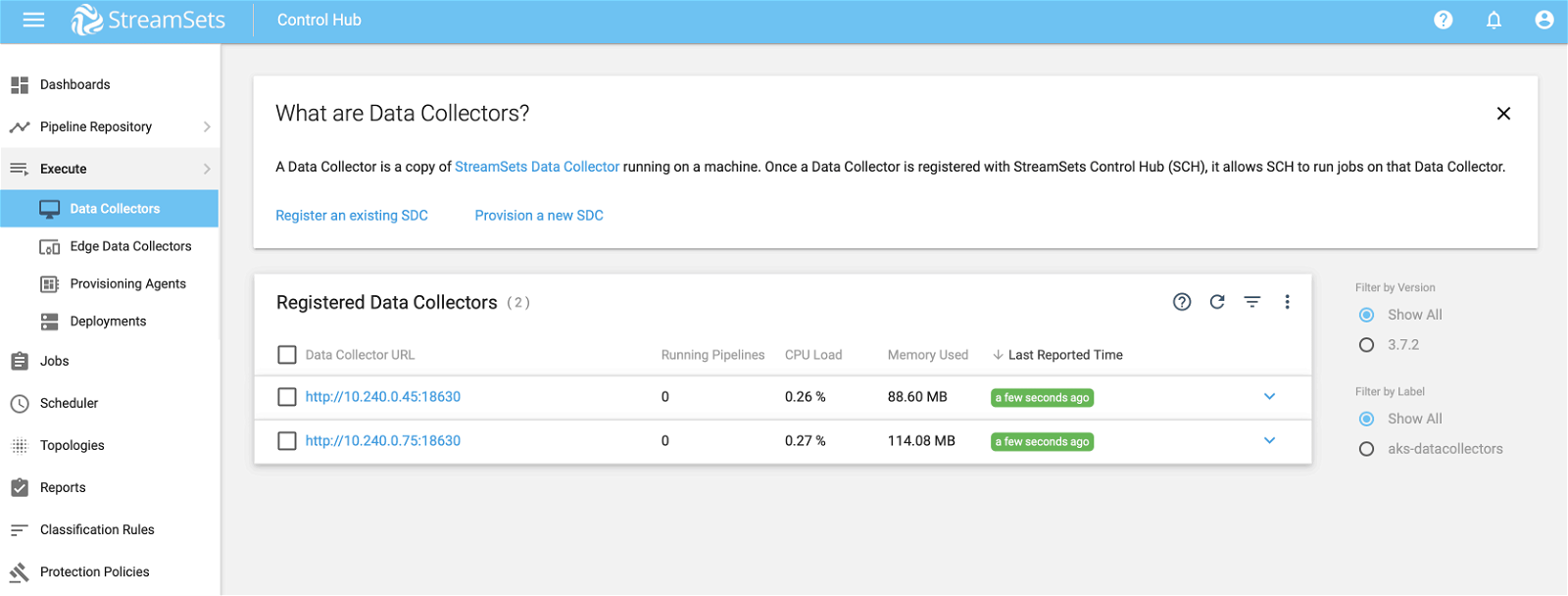
You can also run the following `kubectl` command to confirm Data Collector container pod deployments.
$ kubectl get pods NAME READY STATUS RESTARTS AGE dash-aks-agent-6cf96997b7-6hhwn 1/1 Running 0 1h datacollector-deployment-6468d7fbcd-snvqv 0/1 ContainerCreating 0 3s datacollector-deployment-6468d7fbcd-spv52 0/1 ContainerCreating 0 3s
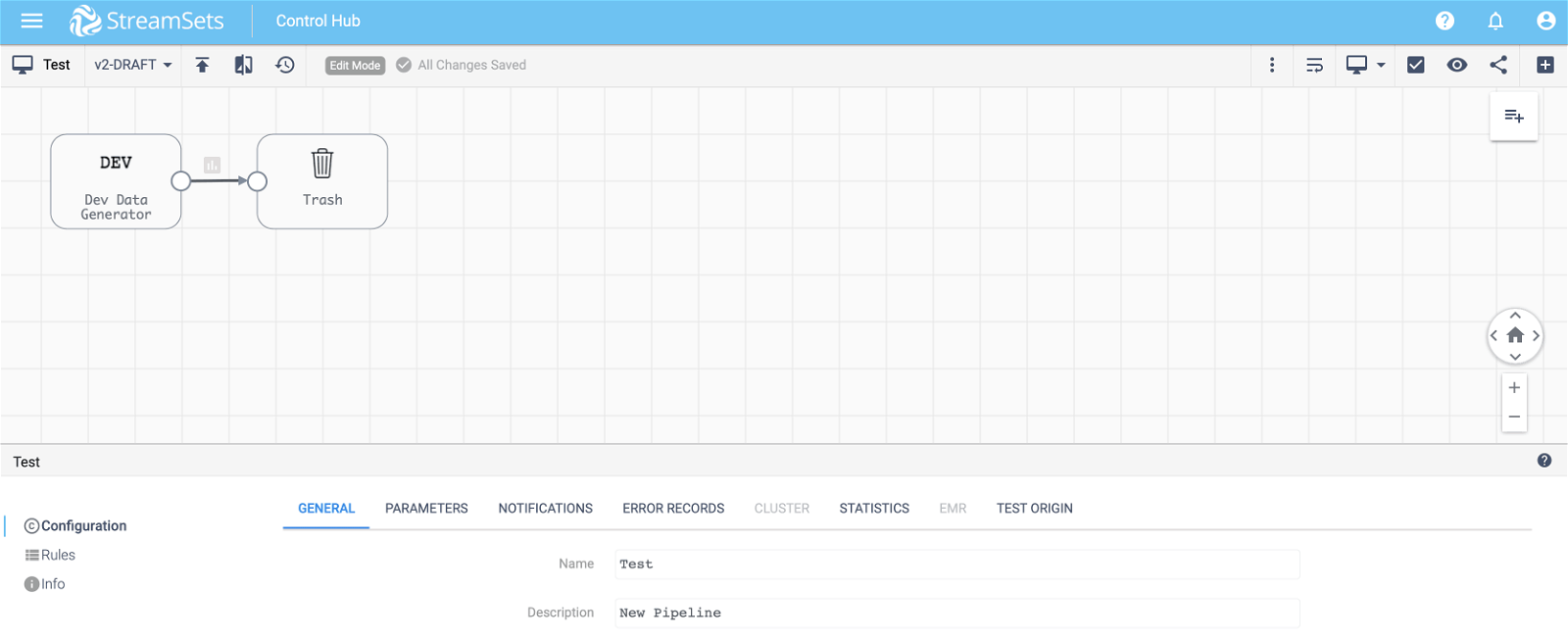
STEP 7. Create Pipeline and Job
To test our deployment, let’s create a simple pipeline (with Dev Raw Data Source origin and Trash destination) and a job to run the pipeline as shown below.

IMPORTANT: Make sure to select the correct pipeline and enter ‘aks-datacollectors‘ for Data Collector Labels–which matches label of Data Collectors created by container deployment in step 5. (Note: Jobs use labels as selection criteria for Data Collectors to run associated pipelines.)
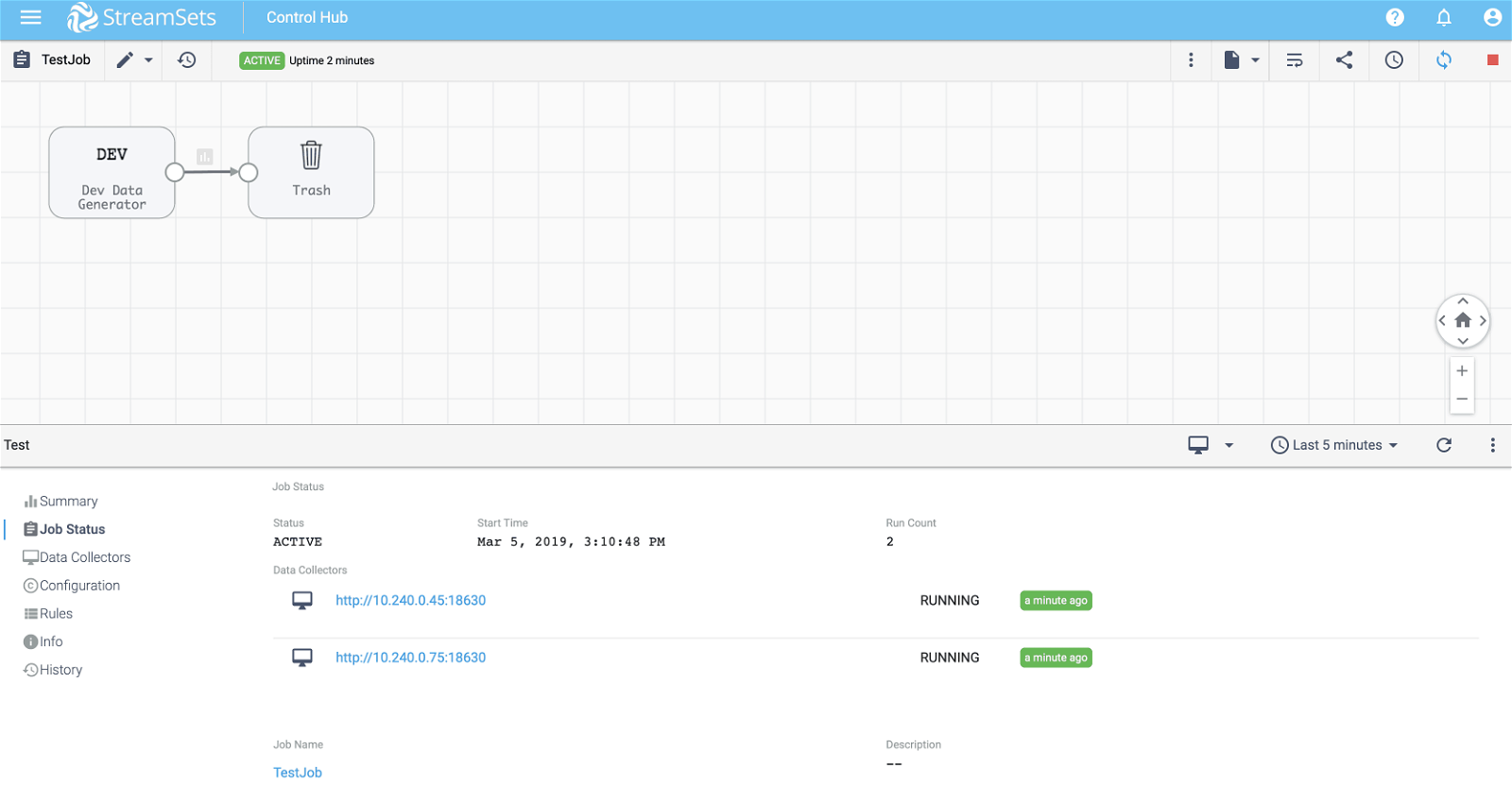
STEP 8. Execute Job
Select job created in step 7 and click on Play button. If all goes well, the job will start executing the pipeline on two Data Collector instances as shown below.
STEP 9. Scale Up Data Collectors
Now let’s see how we can scale up Data Collectors without having to stop job execution.
Select Execute >> Deployments from the left sidebar menu and click on the deployment created in step 5. Then, increase Number of Data Collector Instances to 3 and click on Scale button as shown below.

This should almost instantaneously bring up another Data Collector instance identical to the other two. To confirm, select Execute >> Data Collectors from the left sidebar menu as show below.
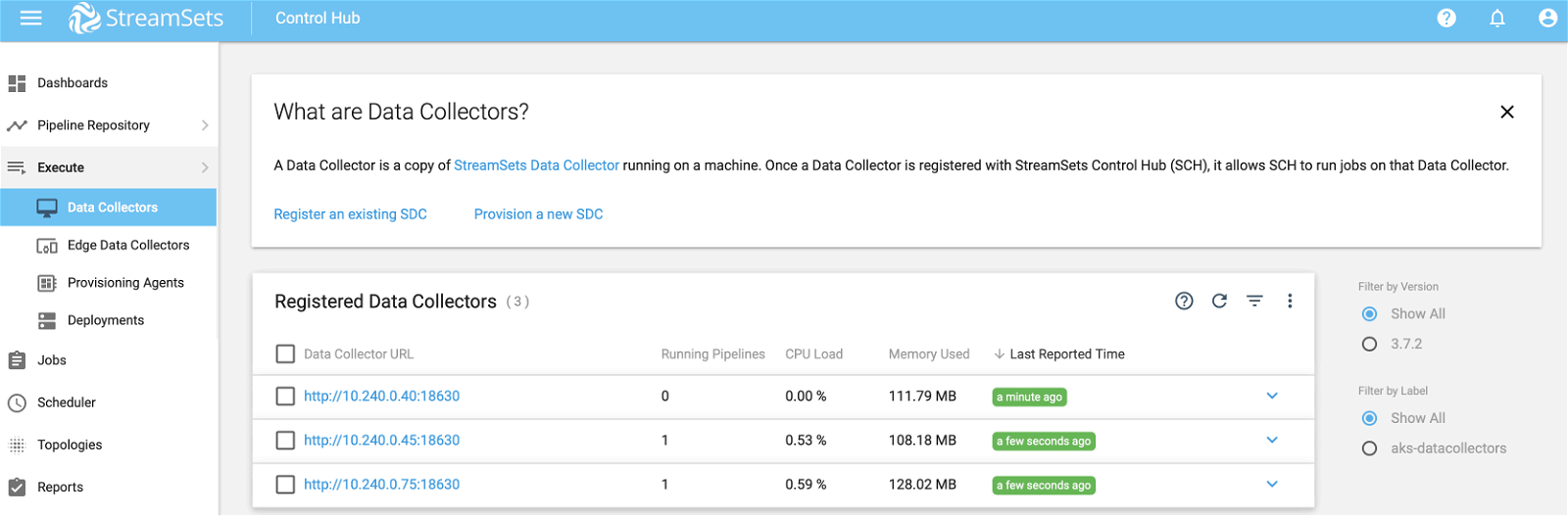
IMPORTANT: Notice that two Data Collectors are showing that there’s 1 pipeline running on each—via the running job—but the third Data Collector is running 0 pipelines. This is because we need to synchronize the job so that it is instructed to start pipeline(s) on additional Data Collectors that match the labels specified in the job.
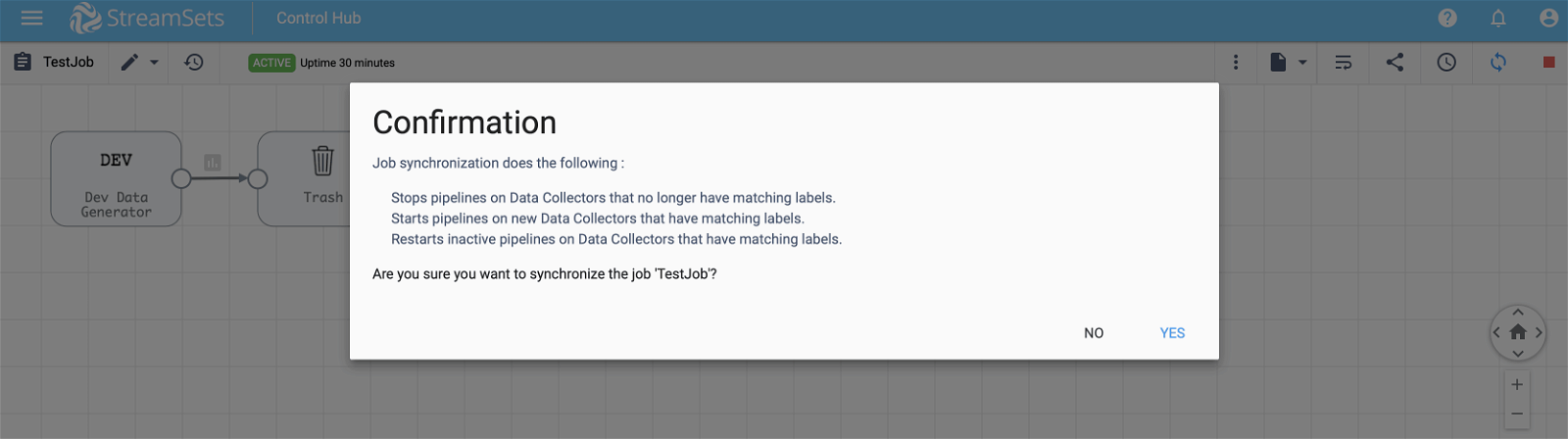
To synchronize the job without stopping its execution, click on Sync button located on the top right corner and then select Yes as shown below.

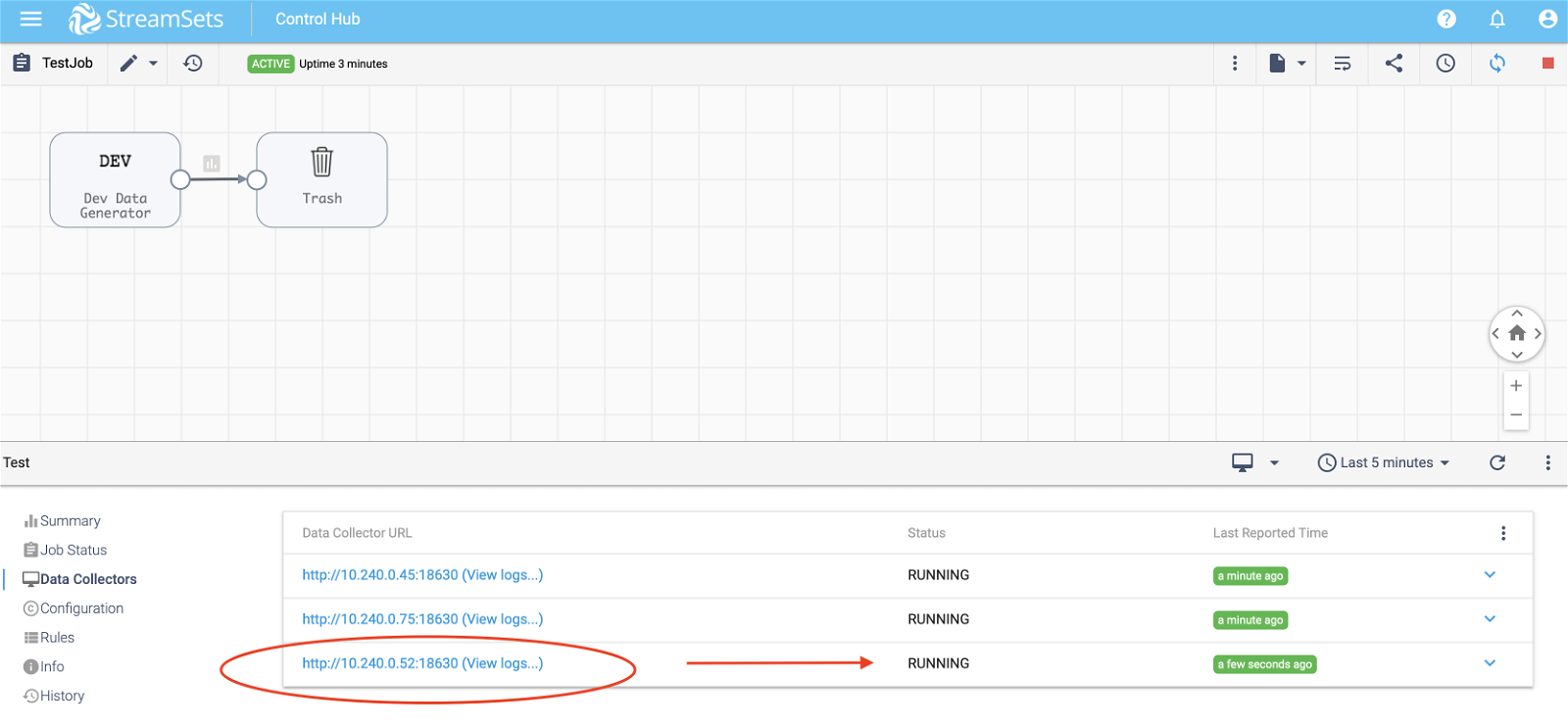
Give it a few minutes and you should see the pipeline running on the third Data Collector as shown below.
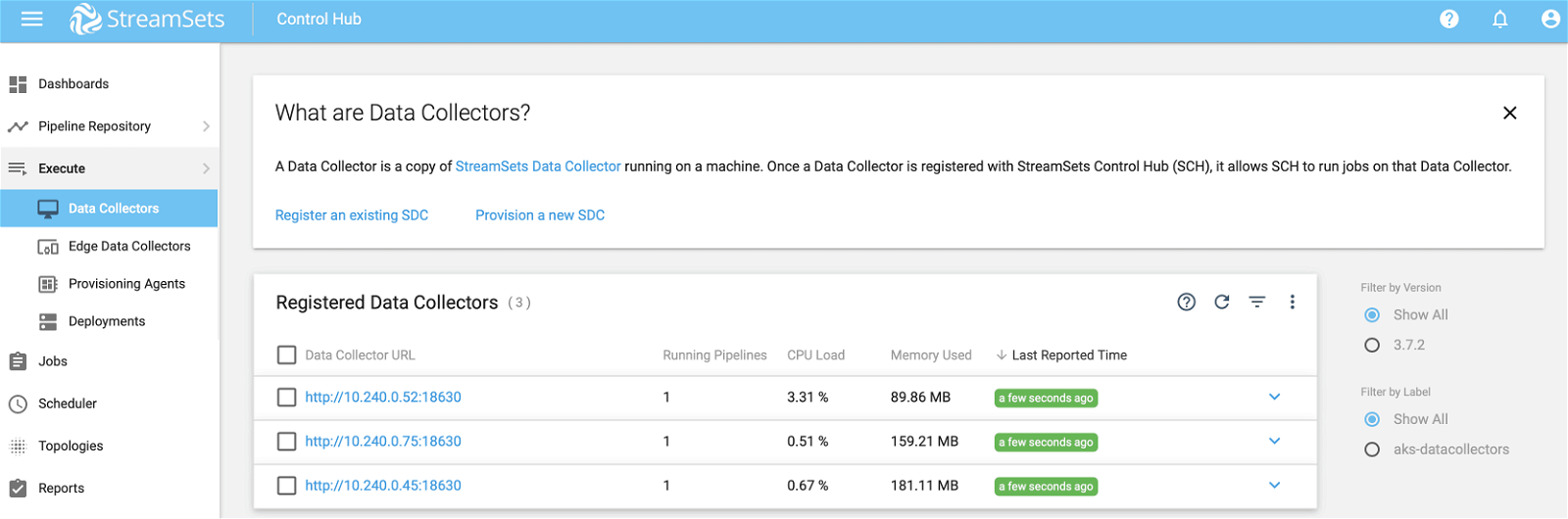
Similarly, you can scale down Data Collector instances without having to stop the job execution.
That’s all folks!
Summary
StreamSets Control Hub makes it extremely easy to create and manage your Data Collector deployments on Kubernetes both on Azure and Google Cloud Platform (GCP). For Data Collector deployments on GCP Kubernetes Engine, checkout this blog post.
To learn about StreamSets and Microsoft partnership, click here.