 UPDATE – Since this blog post was written, StreamSets Control Hub added a Control Agent for Kubernetes that supports creating and managing Data Collector deployments and a Pipeline Designer that allows designing pipelines without having to install Data Collectors. This blog entry has full details: Using StreamSets Control Hub for Scalable Deployment via Kubernetes.
UPDATE – Since this blog post was written, StreamSets Control Hub added a Control Agent for Kubernetes that supports creating and managing Data Collector deployments and a Pipeline Designer that allows designing pipelines without having to install Data Collectors. This blog entry has full details: Using StreamSets Control Hub for Scalable Deployment via Kubernetes.
In today’s microservice revolution, where software applications are designed as independent services that work together, two technologies stand out. Docker, the defacto standard for containerization, and Kubernetes, a container orchestration and management tool. In this blog I will explain how to run StreamSets Data Collector (SDC) Docker containers on Kubernetes.
There are two ways in which SDC can be run on Kubernetes. The first option is to run SDC via Kubernetes StatefulSets and the second is to run SDC as a Kubernetes Deployment. Checkout repo datacollector-kubernetes to get started.
SDC as Kubernetes StatefulSets
Go to directory datacollector-kubernetes/statefulsets and run the following command:
kubectl create -f sdc.yaml
You will see a StatefulSet and a service in your Kubernetes dashboard as shown below.


You can assign an external IP address to SDC and make it accessible on the internet by changing the service type to “LoadBalancer”.
That’s it! SDC is running as a container on your Kubernetes cluster!
So far so good, but high availability (HA) & failover are requirements when running SDC in production. With StatefulSets Kubernetes spins up a new SDC when an existing one goes down. However, pipeline state and offsets are not tracked and pipelines do not fail over to the new SDC.
SDC as Kubernetes Deployment
This option addresses the above problem by running SDC as a Kubernetes Deployment along with StreamSets Dataflow Performance Manager (DPM). SDCs run as stateless execution units that rely on DPM to store pipelines and track offsets. With DPM, SDCs can take advantage of features like integration with SAML, versioned pipeline repository, high availability and failover of pipelines, and monitoring. In the rest of the article I will walk through this setup in detail. Ensure you have an account with StreamSets Dataflow Performance Manager with Organization Administrator role. You can apply for a trial account here.
Solution Overview and Architecture
In order to design and execute pipelines, I recommend 2 deployments: “Design” deployment with one SDC and “Execution” deployment with many. Since DPM stores pipelines and tracks offsets, no additional persistent storage is necessary in either deployment. SDCs can be accessed within the Kubernetes cluster or via a VPN connection. The single Design SDC may be exposed as a Kubernetes Service if necessary. Execution SDCs are meant to be stateless execution units that run pipelines and periodically report back pipeline state, offsets and metrics to DPM. The execution SDC deployment can be scaled as required using Kubernetes.
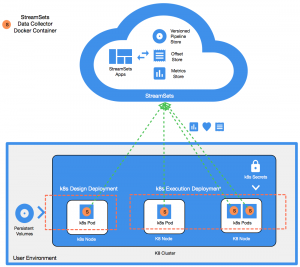
SDC Docker Image
To start with, you need an SDC Docker image which registers with DPM on startup and deregisters on termination. Build the Docker image using the Dockerfile and scripts from directory datacollector-kubernetes/docker and publish it into your private registry. Feel free to modify the Dockerfile to include any stage libraries you want.
Setting Up the Environment
Go to directory datacollector-kubernetes/design-sdc and run the following commands to create a new namespace called “streamsets”:
kubectl create -f namespace.yaml
kubectl config set-context $(kubectl config current-context) --namespace=streamsets
The SDC Docker image requires the DPM Organization Administrator username and password to register with DPM on startup. It expects this information to be available in a secret named “mysecrets”. The secret will be mounted as a volume into the SDC resources directory by the yaml file. Run the following command to create it:
kubectl create secret generic mysecrets --from-literal=dpmuser=user@org --from-literal=dpmpassword=password
Design Data Collector Deployment
Go to directory datacollector-kubernetes/design-sdc and update the design-sdc.yaml file with the path to your private image and organization name. Run the following commands to spin up a single design sdc:
kubectl create -f design-sdc.yaml
kubectl create -f design-sdc-svc.yaml
Note that SDC is now publicly available at that endpoint. Instead you may want to configure the type as “Node Port” and consider creating a SSH tunnel to the node to access the UI.
Execution Data Collector Deployment
Go to directory datacollector-kubernetes/exec-sdc and update the exec-sdc.yaml file with the path to your private image, organization name and desired number of replicas. Run the following commands to spin up execution SDCs.
kubectl create -f exec-sdc.yaml
You can scale up or scale down the number of execution SDCs using the command:
kubectl scale deployment exec-sdc --replicas=n
Your design and execution environment is ready! You should see the following Deployments and Pods in your Kubernetes dashboard:

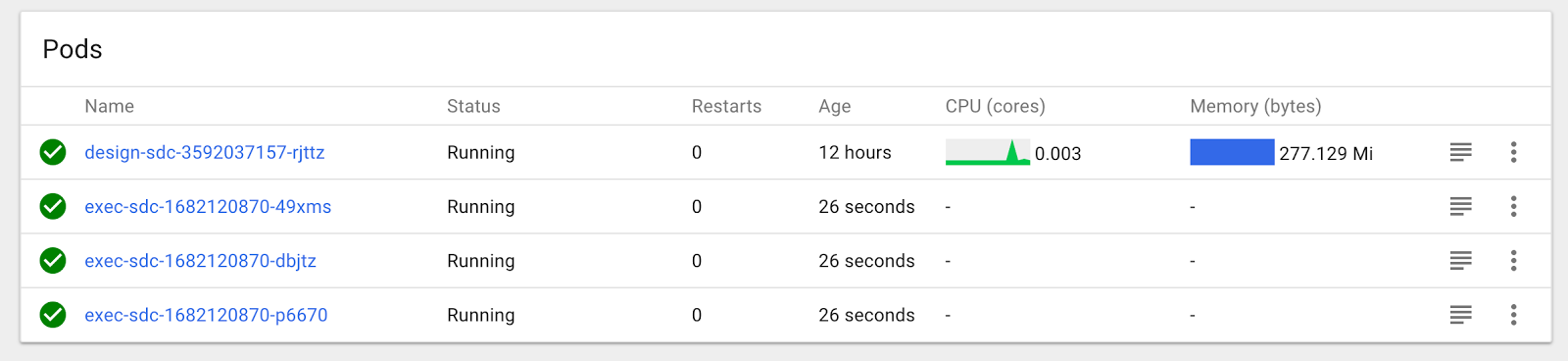
Verify SDCs in DPM
Verify that a single SDC with label “k8s-design-sdc” and ‘n’ SDCs with label “k8s-exec-sdc” are registered with DPM.
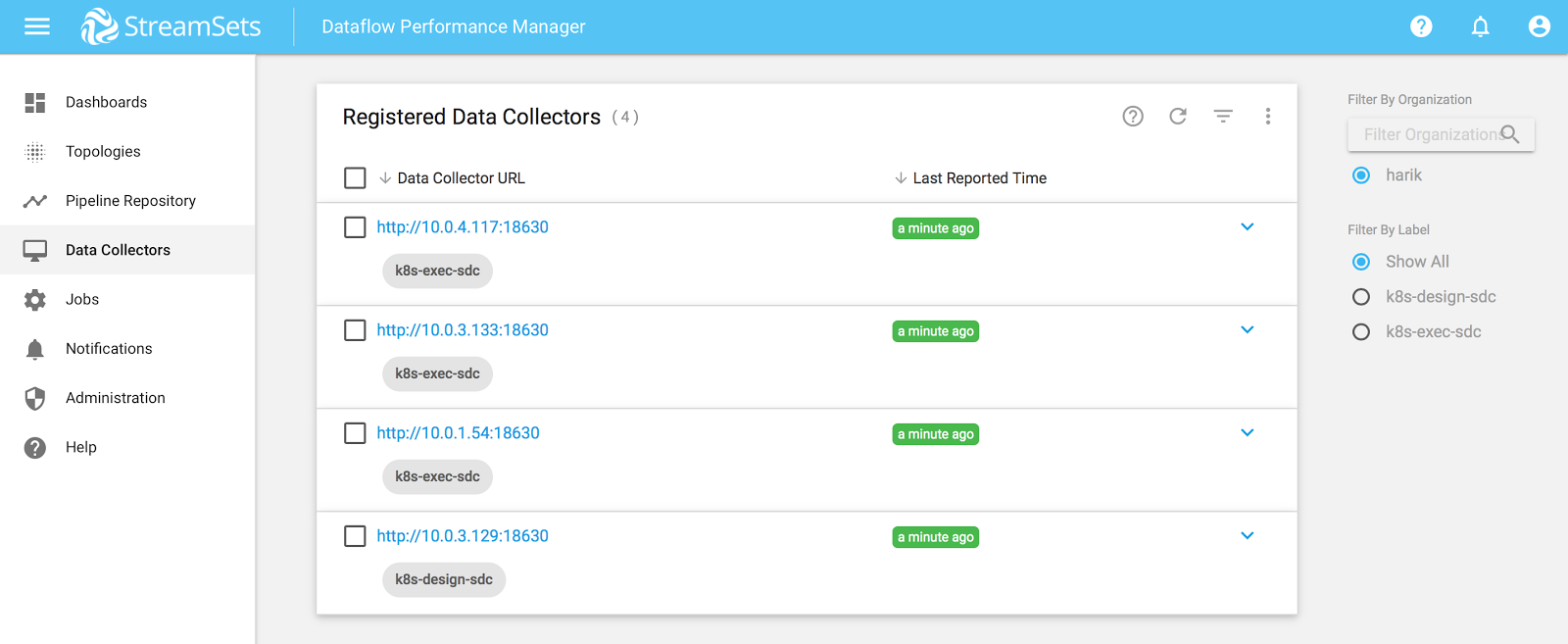
The setup is now ready. Design your pipeline in the design SDC and follow this tutorial to publish your pipeline to DPM.