In this blog post, learn how to perform sentiment analysis via an integration between Microsoft SQL Server 2019 Big Data Cluster and StreamSets Platform.
Greater flexibility is enabled when interacting with Big Data and managing it in a way that makes it easy to use the data for machine learning and analytical tasks. This process allows data team members to deploy scalable clusters of SQL Server, Apache Spark, and HDFS containers running on Kubernetes.
SQL Server 2019 Big Data Clusters enable creating a virtual data hub for users to query data from many sources, structured and unstructured through a single, unified interface via Polybase. StreamSets enhances the data hub by providing a data integration platform for physically moving data from disparate sources, locations, and formats in a continuous and reliable way, allowing you to build a modern data hub driving real time analytics.
Given that SQL Server Big Data Cluster is deployed as a set of containers on a Kubernetes cluster, it’s easy to deploy StreamSets in the same environment using provisioning agents. A provisioning agent is a containerized application that runs in Kubernetes. The agent communicates with StreamSets to automatically provision containers for StreamSets data plane components for moving data across data stacks. Provisioning includes automatically deploying, registering, starting, scaling and stopping data plane containers.
As noted, in this blog post, we’ll look at the integration between the two technologies to perform sentiment analysis on streaming data from Twitter.
Watch Demo Video
This demo is broken up into two flows as described below.
Ingestion: Twitter To Apache Kafka
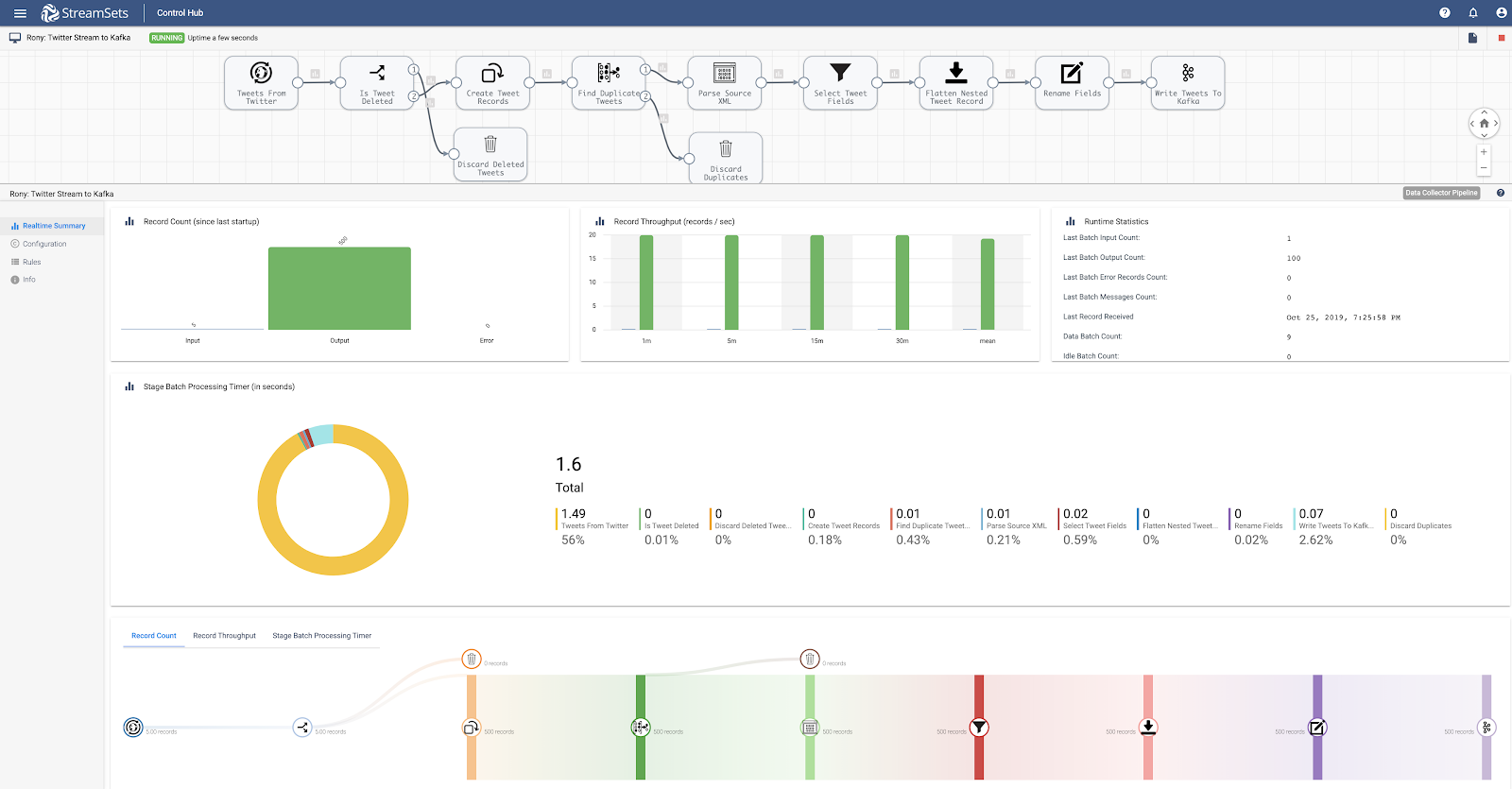
- Ingest
- Query tweets from Twitter using its Search API.
- Transform
- StreamSets offers over 60 out-of-the-box processors. Transformations in this pipeline include discarding deleted and duplicate tweets using Stream Selector, pivoting array of tweets returned by Twitter’s API into individual tweet records using Field Pivoter, flattening nested tweet structure using Field Flattener, and filtering and renaming fields using Field Remover and Field Renamer.
- Store
- The transformed tweet records are sent to Apache Kafka destination.
Sentiment Analysis: Apache Kafka To SQL Server 2019 Big Data Cluster
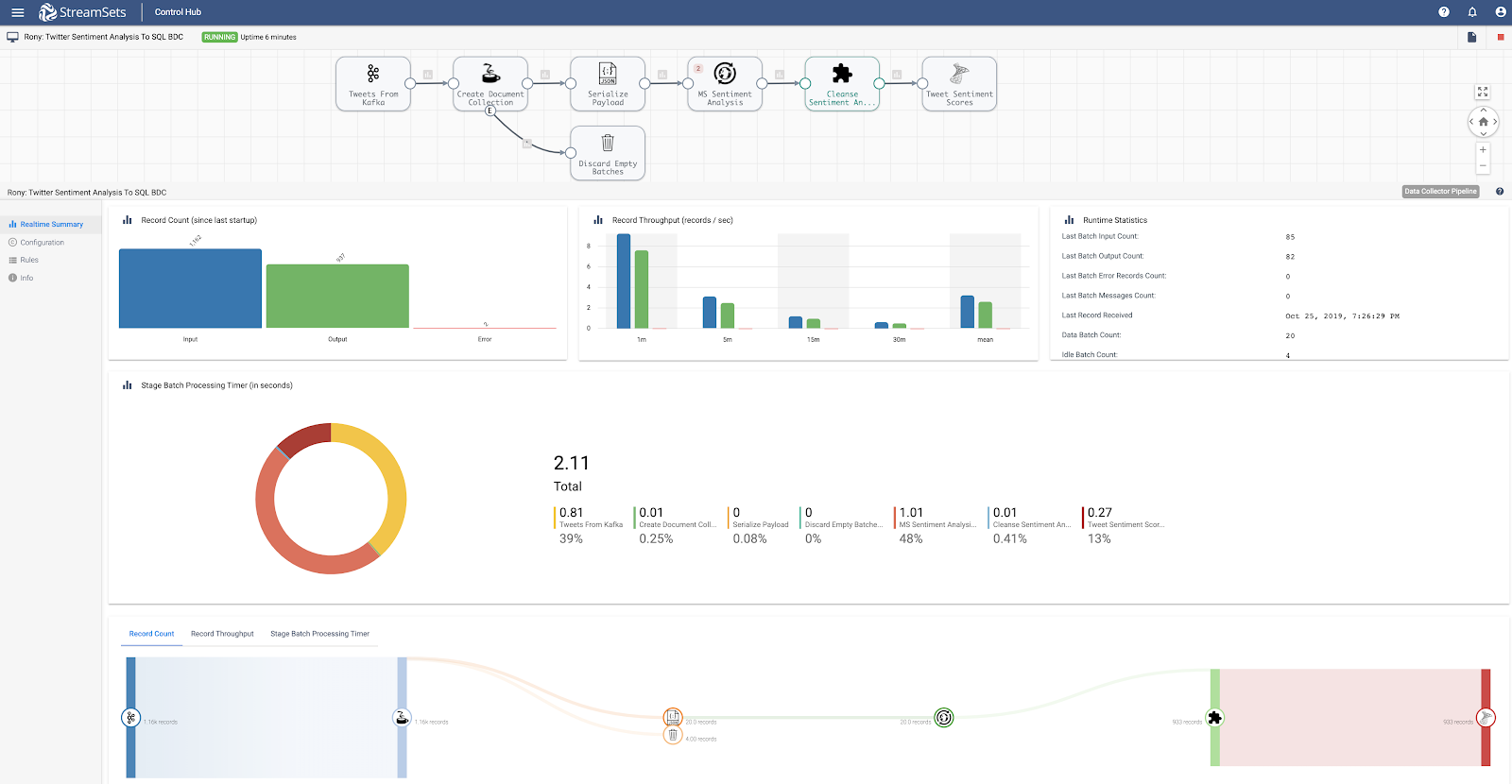
- Ingest
- Transformed tweet records are read from Apache Kafka.
- Transform
- Transformations include prepping tweet records into a collection of JSON documents with attributes id, text, and language as required by Azure Sentiment Analysis API. (See below sample API input and output***.) The processors used in this pipeline are: Jython Evaluator, JSON Parser, and HTTP Client.
- Machine Learning
- HTTP Client processor initiates request to Azure Sentiment Analysis API to analyze and score tweet text. Scores close to 1 indicate positive sentiment and scores close to 0 indicate negative sentiment.
- Store
- Each tweet record along with its sentiment analysis score is stored in SQL Server 2019 Big Data Cluster for querying and further analysis.
***Sample Azure Sentiment Analysis API input:
{ "documents": [ { "language": "en", "id": "1", "text": "RT @UnoPlatform: Hey tweeps – will any of you be at Ignite conference in Orlando? We will be there and would love to connect, get a coffee." }, { "language": "es", "id": "2", "text": "MS-500 está reservado mientras estoy en #MSIgnite2019. Ahora a golpear los libros!" }, { "language": "en", "id": "3", "text": "Take a look at @VirtDesktopTT's top 10 Microsoft Ignite 2019 sessions for VDI admins. You won't want to miss." } ] }
***Sample Azure Sentiment Analysis API output:
{ "documents": [ { "id": "1", "score": 0.92 }, { "id": "2", "score": 0.85 }, { "id": "3", "score": 0.64 } ], "errors": [] }
Query Sentiment Analysis on SQL Server 2019 Big Data Cluster
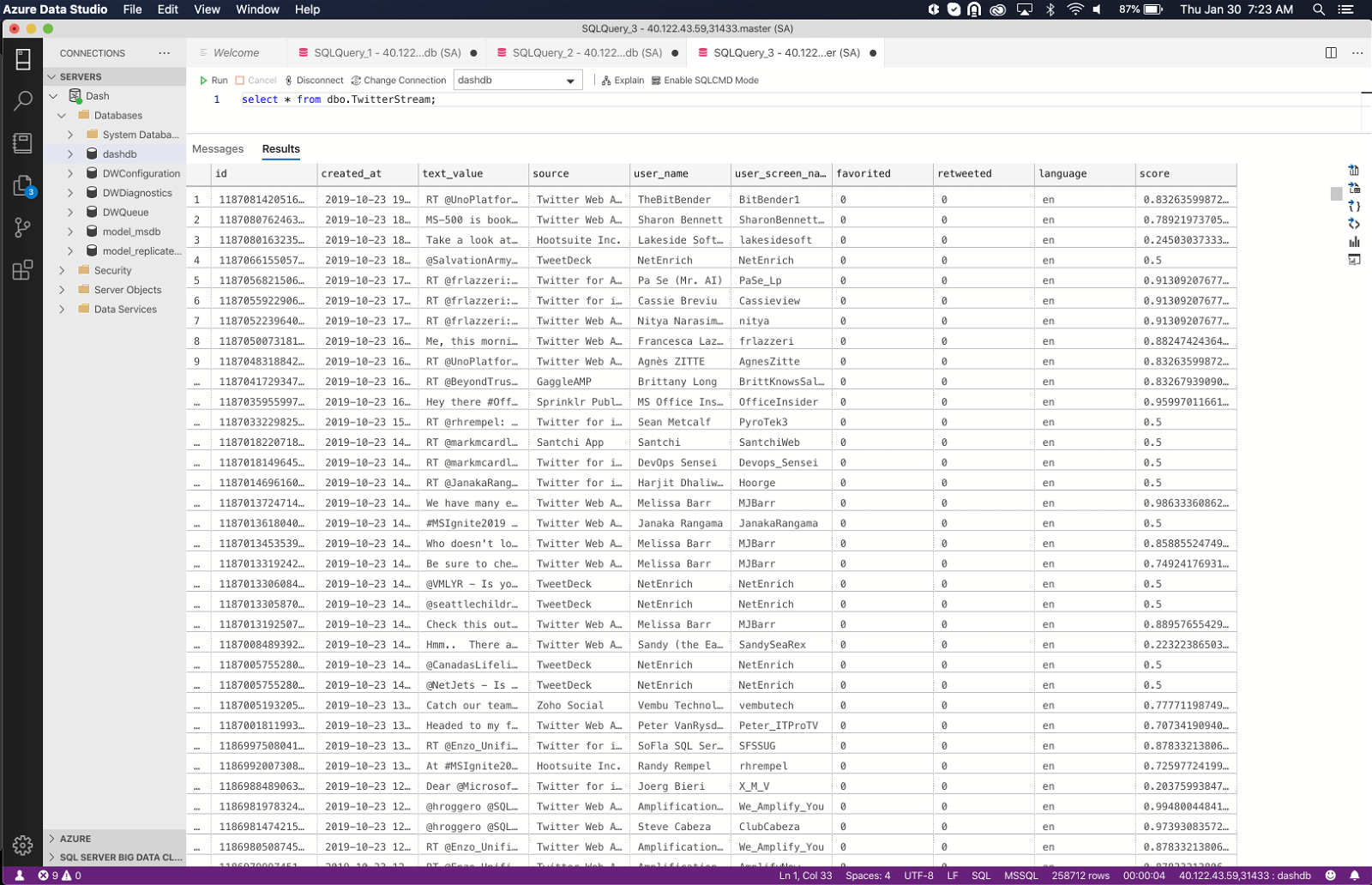
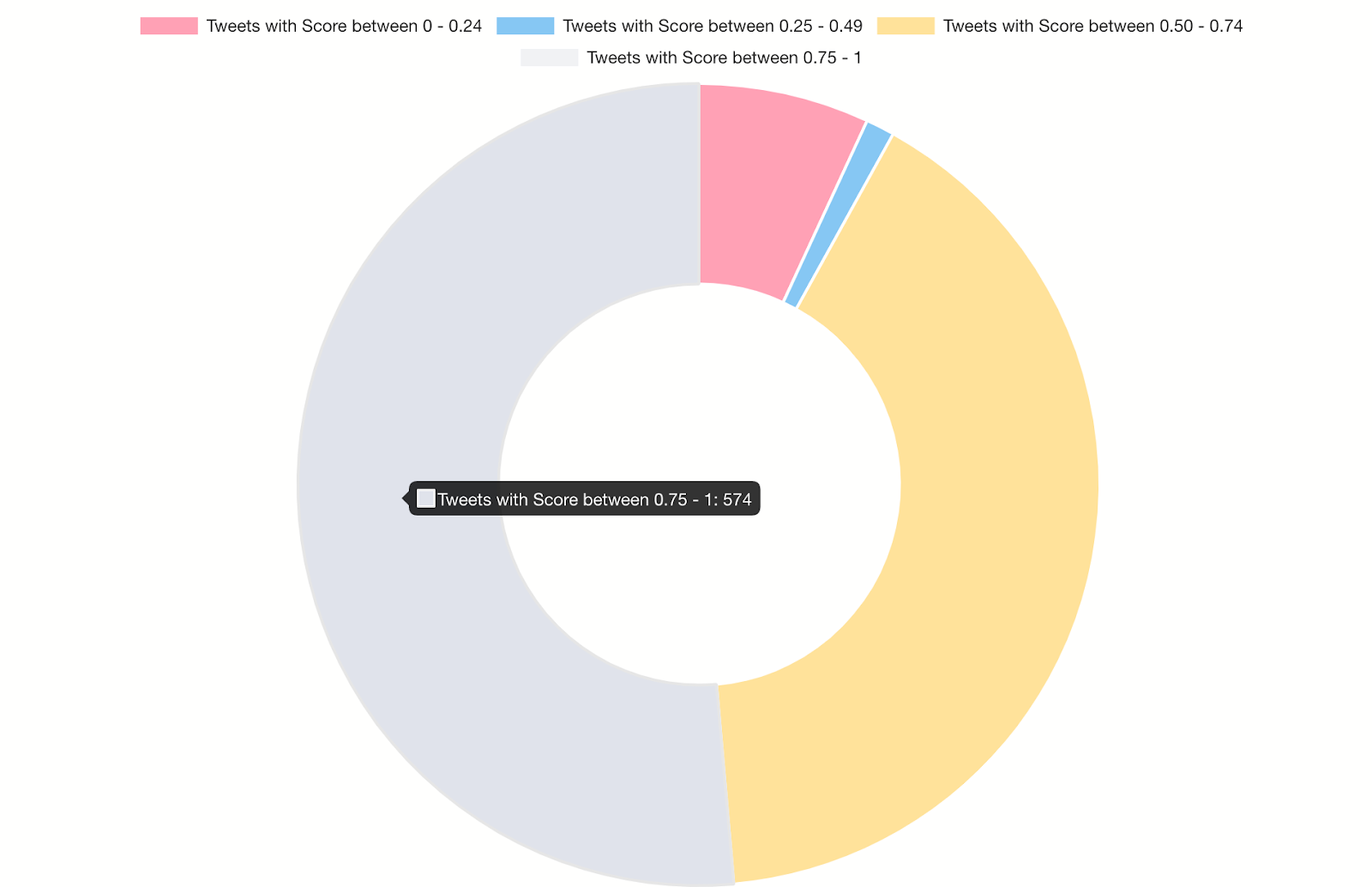
Once the tweets data along with sentiment analysis scores is stored in SQL Server Big Data Cluster, they’re ready for querying in Azure Data Studio.
Retrieve the tweet records.
SELECT * FROM [dashdb].[dbo].[TwitterStream];
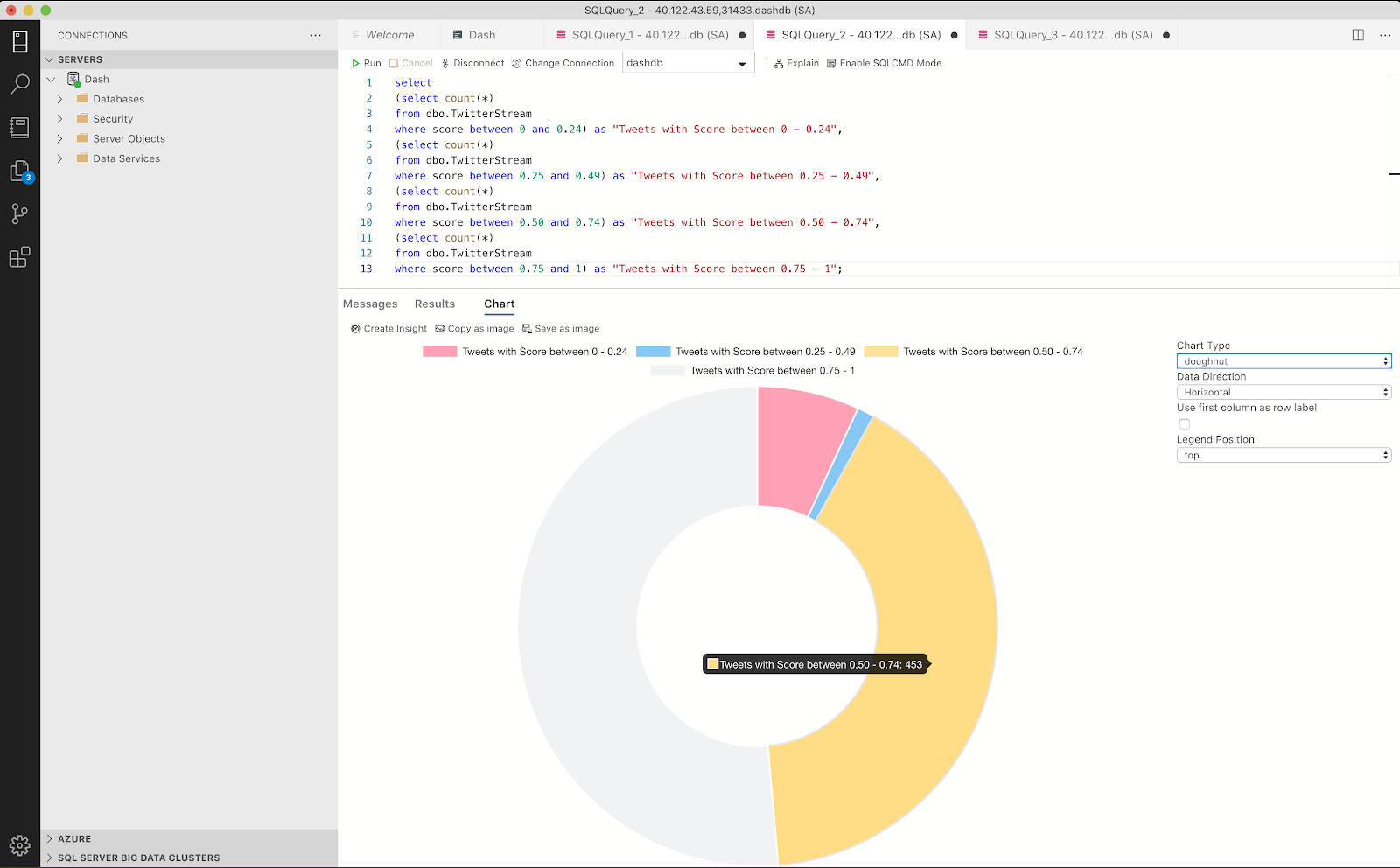
Create “bins” based on scoring range.
select (select count(*) from dbo.TwitterStream where score between 0 and 0.24) as "Tweets with Score between 0 - 0.24", (select count(*) from dbo.TwitterStream where score between 0.25 and 0.49) as "Tweets with Score between 0.25 - 0.49", (select count(*) from dbo.TwitterStream where score between 0.50 and 0.74) as "Tweets with Score between 0.50 - 0.74", (select count(*) from dbo.TwitterStream where score between 0.75 and 1) as "Tweets with Score between 0.75 - 1";
Summary
In this blog, I’ve illustrated how easily you can get started with Microsoft SQL Server 2019 Big Data Cluster and StreamSets Platform. In the highlighted use case, you learned how to quickly gain insights using Machine Learning on streaming data using the two technologies.
Learn more about StreamSets Platform and the StreamSets and Microsoft partnership.