You may be taking an interest in Snowpark UDFs as a way to take full advantage of the power of your Snowflake Data Cloud. You’re not alone. Companies are always looking for new ways to get more out of their existing investments, simplify and standardize on technologies that can help them scale and support company growth. No matter what stage a business is in, creating more streamlined processes to automate certain tasks is essential.
Our goal at StreamSets is to help Data Engineers and architects do exactly that. We are excited about Snowpark because it provides a straightforward and familiar way for Snowflake users to push data intensive workloads directly into Snowflake. No need to set up and use complex external environments like Spark cluster. Snowpark UDFs for Python (currently in Private Preview), Java and Scala are an easy way for you to incorporate your own custom libraries or public libraries directly into your Snowflake data pipelines. StreamSets’ Transformer for Snowflake supports all the Snowpark UDFs and let me show you how simple this is!
Apply Python UDFs to your Snowflake Data Cloud using Transformer for Snowflake
Snowflake recently debuted their ability for users to call and execute Python libraries through their Snowpark developer framework. While Snowpark for Python UDF support is still in Private Preview, they already have compatibility for Java UDF and Scala API in their GA service.
Personally, I am most excited about Python because it is my preferred language. Python is quickly becoming one of the most widely used languages and I believe this will attract more people like myself to the Snowflake Data Cloud. Now through Snowpark you can program Python UDFs that are included in a pipeline using StreamSets’ Transformer for Snowflake and have all the logic executed natively in your Snowflake environment – no need to extract any data for external processing!
Let me cover some basics for those that are new users to StreamSets, Snowflake or both.
What is Transformer for Snowflake?
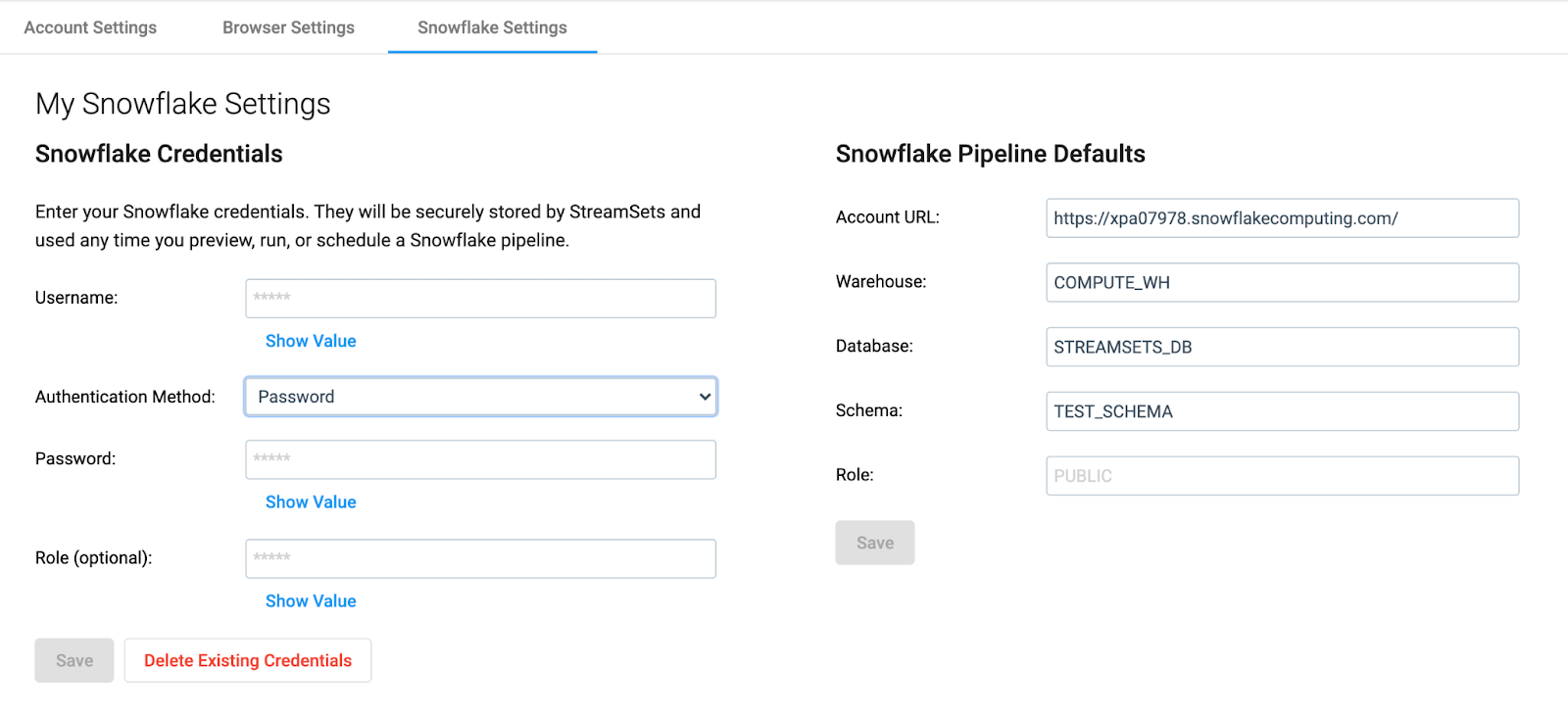
Transformer for Snowflake is our latest engine which is now Generally Available in StreamSets DataOps Platform. It utilizes the Snowpark API to run queries and transform your data within your Snowflake environment. You can build more complex pipelines and apply Snowpark UDFs to your data without ever needing to write SQL. Transformer for Snowflake is serverless which means you don’t have to set up any environments or deploy any engines! Just log into the platform and navigate to your Account Settings > Snowflake Settings by clicking on the User icon in the top right navigation and ‘My Account’. Input your Snowflake account credentials to connect to Snowflake and you can start building and running pipelines. It’s that easy.
What is Snowpark?
Snowpark, as described by Snowflake, is a new developer framework to program data in Snowflake through a set of optimized APIs and server-side functions – UDFs. Snowpark brings native support for true programming languages such as Java, Scala and now Python too to provide broader data programmability. This means data engineers now have the ability to apply complex programing logic to their data natively within their Snowflake Data Cloud, rather than having to extract their data, process it elsewhere and then reload it into Snowflake.
What is a UDF?
Technically a UDF, or user-defined function, is exactly what it sounds like. It is a custom program written by the user that can be used on top of any built-in function. When working with large databases, this allows engineers to be more efficient by reusing scripts or programs that can perform specific tasks, rather than rewriting them each time. Data engineers can call these functions whenever needed and simply need to pass in the parameters for their specific use case.
Building Your Pipeline and Applying Snowpark UDFs
This article will show you how simple it is to import and use your custom libraries in Snowflake, and then build pipelines with StreamSets to transform your data.
I’m going to use an email validation library that’s hard to do in SQL but easy in Python. The cool thing is it will all run natively in Snowflake. No data will need to be extracted and analyzed outside of Snowflake in a separate environment like a Spark cluster. Your StreamSets pipeline applies all transformations and UDFs natively within Snowflake. How cool is that?
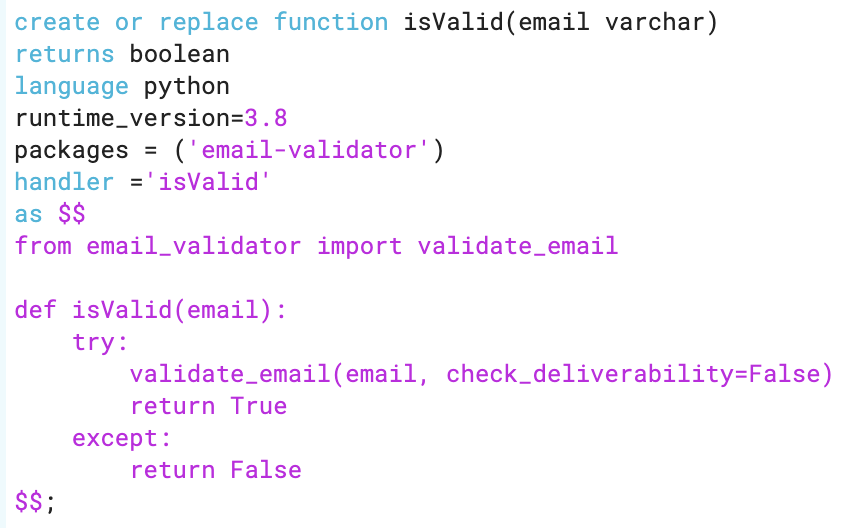
Since Snowflake Python API’s are still in Private Preview, this is advanced insight to what’s coming soon! You can request Private Preview access from Snowflake or wait a bit until it’s in Public Preview. Once you have that, you will be able to create your Python UDF function directly in your Snowflake worksheet. Instructions on how to formulate this function can be found here and I have included a simple one below for this example.
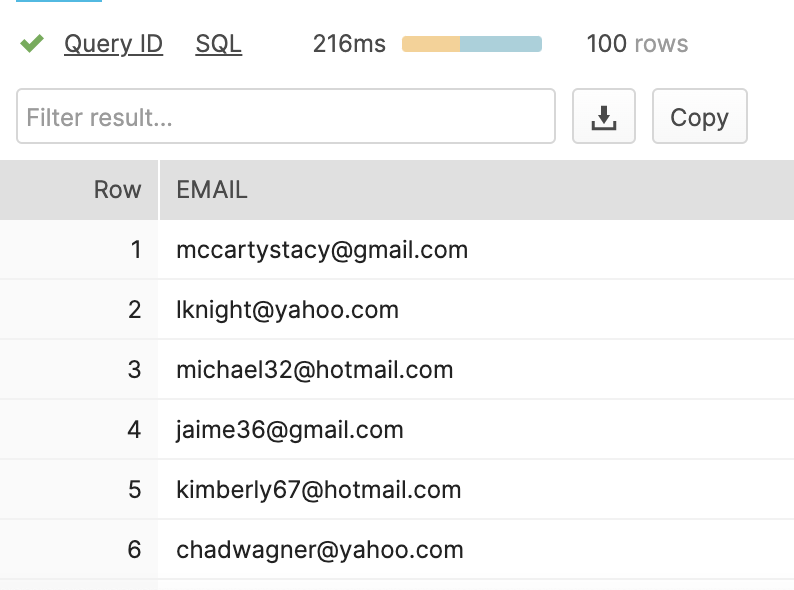
For this example, I generated a list of 100 email addresses and changed 3 of them to have incorrect syntax which I then uploaded to a Snowflake table, shown below.
I used a Python library called “email-validator”, which as you can guess, checks whether an email address is valid. You can read more about the specifics here, but essentially it checks that the syntax is correct and if desired, you can optionally customize it to check the domain for deliverability as well.
In fact, by default this library is designed to check each domain’s MX DNS record to ensure it can receive emails; however, I found out for security reasons Snowflake has constraints around network access. This required me to add the “check_deliverability=False” clause in my function, but it was a good thing to discover for my future efforts. So for our purposes in this quick example, we will just be checking whether the email address has a legitimate syntax. If it does, it will be passed through to be written to a new table, and if not, it will be discarded.

In this pipeline, I am reading from an existing table in my Snowflake warehouse, with 100 email addresses. The apply functions processor then calls the Snowpark UDF which I created in my Snowflake worksheet, then the filter sends all valid emails to the destination table and discards the rest. Since 3 were invalid, there should only be 97 emails in our final table if this worked as intended.
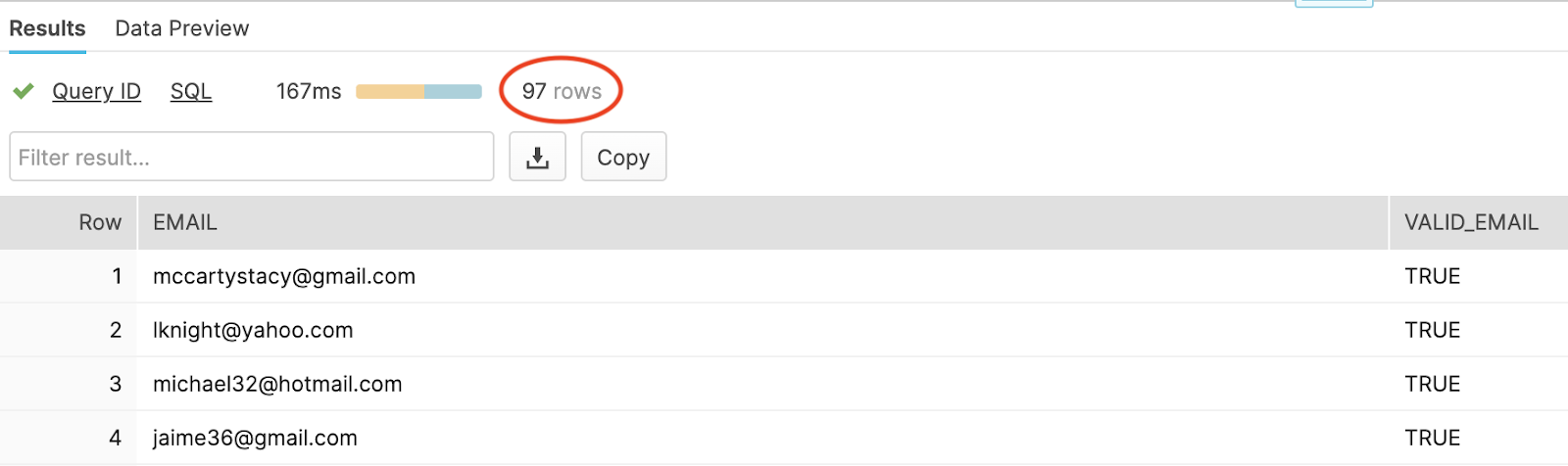
And when I check my table in Snowflake, it does! That’s how easy it is to apply Snowpark UDFs with StreamSets. This example uses a very simple publicly available Python library, however you can choose from a wide variety of other third party Python packages that will run within Snowflake, which are provided by Anaconda and listed here. Of course, you can also create your own custom UDFs as we can integrate with the current Java and Scala UDF’s as well.
As a Data Engineer, it would be common for me to create libraries which are custom or unique to my company. The more a company can standardize their custom libraries the more they can be assured their data is being processed to a common standard. StreamSets makes it easy to do this while building complex data pipelines. The same process can be applied to much more complex logic, processors and even data quality rules like Deequ from AWS.
I have only recently started to play around with Python UDFs in Snowpark during Private Preview, so I haven’t tried everything yet. But I’d love to hear from our users in our Community about what they have built and found useful!
If you are new to StreamSets and trying us out with Snowflake (or a different use case), don’t hesitate to reach out with any questions you may have. You can always book time directly with me or another Trial Success Engineer directly in the application.